 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLink: Linking Black-Box Models from Multiple Domains for Collaborative Inference
Sep 28, 2022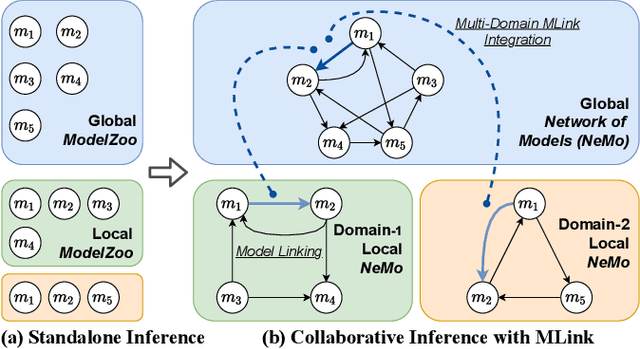
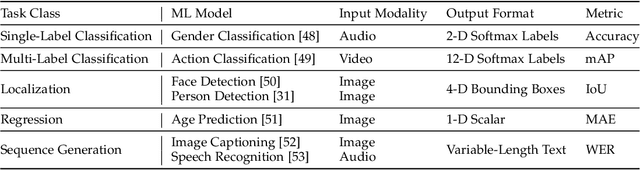
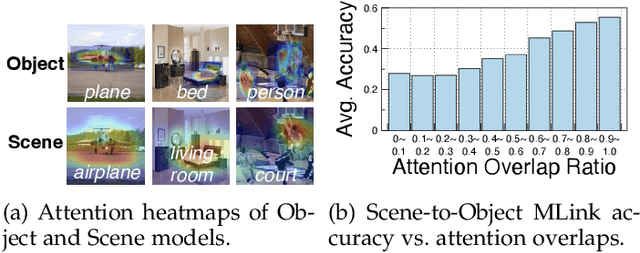
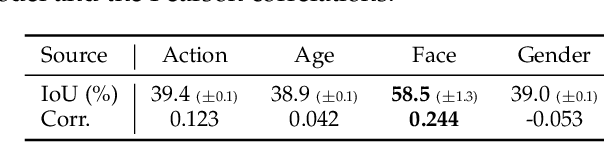
The cost efficiency of model inference is critical to real-world machine learning (ML) applications, especially for delay-sensitive tasks and resource-limited devices. A typical dilemma is: in order to provide complex intelligent services (e.g. smart city), we need inference results of multiple ML models, but the cost budget (e.g. GPU memory) is not enough to run all of them. In this work, we study underlying relationships among black-box ML models and propose a novel learning task: model linking, which aims to bridge the knowledge of different black-box models by learning mappings (dubbed model links) between their output spaces. We propose the design of model links which supports linking heterogeneous black-box ML models. Also, in order to address the distribution discrepancy challenge, we present adaptation and aggregation methods of model links. Based on our proposed model links, we developed a scheduling algorithm, named MLink. Through collaborative multi-model inference enabled by model links, MLink can improve the accuracy of obtained inference results under the cost budget. We evaluated MLink on a multi-modal dataset with seven different ML models and two real-world video analytics systems with six ML models and 3,264 hours of video. Experimental results show that our proposed model links can be effectively built among various black-box models. Under the budget of GPU memory, MLink can save 66.7% inference computations while preserving 94% inference accuracy, which outperforms multi-task learning, deep reinforcement learning-based scheduler and frame filtering baselines.
On-edge Multi-task Transfer Learning: Model and Practice with Data-driven Task Allocation
Jul 06, 2021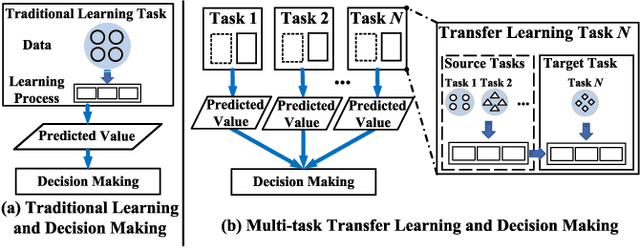

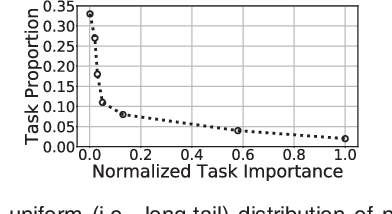
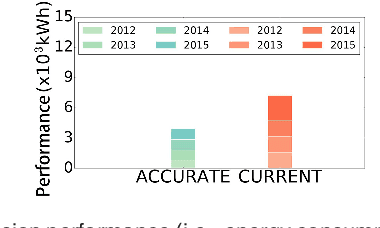
On edge devices, data scarcity occurs as a common problem where transfer learning serves as a widely-suggested remedy. Nevertheless, transfer learning imposes a heavy computation burden to resource-constrained edge devices. Existing task allocation works usually assume all submitted tasks are equally important, leading to inefficient resource allocation at a task level when directly applied in Multi-task Transfer Learning (MTL). To address these issues, we first reveal that it is crucial to measure the impact of tasks on overall decision performance improvement and quantify \emph{task importance}. We then show that task allocation with task importance for MTL (TATIM) is a variant of the NP-complete Knapsack problem, where the complicated computation to solve this problem needs to be conducted repeatedly under varying contexts. To solve TATIM with high computational efficiency, we propose a Data-driven Cooperative Task Allocation (DCTA) approach. Finally, we evaluate the performance of DCTA by not only a trace-driven simulation, but also a new comprehensive real-world AIOps case study that bridges model and practice via a new architecture and main components design within the AIOps system. Extensive experiments show that our DCTA reduces 3.24 times of processing time, and saves 48.4\% energy consumption compared with the state-of-the-art when solving TATIM.
* 15 pages, published in IEEE TRANSACTIONS ON Parallel and Distributed Systems, VOL. 31, NO. 6, JUNE 2020