 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeJOT-AutoML: LLM-Driven Feature Engineering for Job Execution Time Prediction in Databricks Cost Optimization
Mar 09, 2026Databricks job orchestration systems (e.g., LeJOT) reduce cloud costs by selecting low-priced compute configurations while meeting latency and dependency constraints. Accurate execution-time prediction under heterogeneous instance types and non-stationary runtime conditions is therefore critical. Existing pipelines rely on static, manually engineered features that under-capture runtime effects (e.g., partition pruning, data skew, and shuffle amplification), and predictive signals are scattered across logs, metadata, and job scripts-lengthening update cycles and increasing engineering overhead. We present LeJOT-AutoML, an agent-driven AutoML framework that embeds large language model agents throughout the ML lifecycle. LeJOT-AutoML combines retrieval-augmented generation over a domain knowledge base with a Model Context Protocol toolchain (log parsers, metadata queries, and a read-only SQL sandbox) to analyze job artifacts, synthesize and validate feature-extraction code via safety gates, and train/select predictors. This design materializes runtime-derived features that are difficult to obtain through static analysis alone. On enterprise Databricks workloads, LeJOT-AutoML generates over 200 features and reduces the feature-engineering and evaluation loop from weeks to 20-30 minutes, while maintaining competitive prediction accuracy. Integrated into the LeJOT pipeline, it enables automated continuous model updates and achieves 19.01% cost savings in our deployment setting through improved orchestration.
iScheduler: Reinforcement Learning-Driven Continual Optimization for Large-Scale Resource Investment Problems
Jan 30, 2026Scheduling precedence-constrained tasks under shared renewable resources is central to modern computing platforms. The Resource Investment Problem (RIP) models this setting by minimizing the cost of provisioned renewable resources under precedence and timing constraints. Exact mixed-integer programming and constraint programming become impractically slow on large instances, and dynamic updates require schedule revisions under tight latency budgets. We present iScheduler, a reinforcement-learning-driven iterative scheduling framework that formulates RIP solving as a Markov decision process over decomposed subproblems and constructs schedules through sequential process selection. The framework accelerates optimization and supports reconfiguration by reusing unchanged process schedules and rescheduling only affected processes. We also release L-RIPLIB, an industrial-scale benchmark derived from cloud-platform workloads with 1,000 instances of 2,500-10,000 tasks. Experiments show that iScheduler attains competitive resource costs while reducing time to feasibility by up to 43$\times$ against strong commercial baselines.
MCP-ITP: An Automated Framework for Implicit Tool Poisoning in MCP
Jan 12, 2026To standardize interactions between LLM-based agents and their environments, the Model Context Protocol (MCP) was proposed and has since been widely adopted. However, integrating external tools expands the attack surface, exposing agents to tool poisoning attacks. In such attacks, malicious instructions embedded in tool metadata are injected into the agent context during MCP registration phase, thereby manipulating agent behavior. Prior work primarily focuses on explicit tool poisoning or relied on manually crafted poisoned tools. In contrast, we focus on a particularly stealthy variant: implicit tool poisoning, where the poisoned tool itself remains uninvoked. Instead, the instructions embedded in the tool metadata induce the agent to invoke a legitimate but high-privilege tool to perform malicious operations. We propose MCP-ITP, the first automated and adaptive framework for implicit tool poisoning within the MCP ecosystem. MCP-ITP formulates poisoned tool generation as a black-box optimization problem and employs an iterative optimization strategy that leverages feedback from both an evaluation LLM and a detection LLM to maximize Attack Success Rate (ASR) while evading current detection mechanisms. Experimental results on the MCPTox dataset across 12 LLM agents demonstrate that MCP-ITP consistently outperforms the manually crafted baseline, achieving up to 84.2% ASR while suppressing the Malicious Tool Detection Rate (MDR) to as low as 0.3%.
LeJOT: An Intelligent Job Cost Orchestration Solution for Databricks Platform
Dec 20, 2025With the rapid advancements in big data technologies, the Databricks platform has become a cornerstone for enterprises and research institutions, offering high computational efficiency and a robust ecosystem. However, managing the escalating operational costs associated with job execution remains a critical challenge. Existing solutions rely on static configurations or reactive adjustments, which fail to adapt to the dynamic nature of workloads. To address this, we introduce LeJOT, an intelligent job cost orchestration framework that leverages machine learning for execution time prediction and a solver-based optimization model for real-time resource allocation. Unlike conventional scheduling techniques, LeJOT proactively predicts workload demands, dynamically allocates computing resources, and minimizes costs while ensuring performance requirements are met. Experimental results on real-world Databricks workloads demonstrate that LeJOT achieves an average 20% reduction in cloud computing costs within a minute-level scheduling timeframe, outperforming traditional static allocation strategies. Our approach provides a scalable and adaptive solution for cost-efficient job scheduling in Data Lakehouse environments.
IntentMiner: Intent Inversion Attack via Tool Call Analysis in the Model Context Protocol
Dec 16, 2025The rapid evolution of Large Language Models (LLMs) into autonomous agents has led to the adoption of the Model Context Protocol (MCP) as a standard for discovering and invoking external tools. While this architecture decouples the reasoning engine from tool execution to enhance scalability, it introduces a significant privacy surface: third-party MCP servers, acting as semi-honest intermediaries, can observe detailed tool interaction logs outside the user's trusted boundary. In this paper, we first identify and formalize a novel privacy threat termed Intent Inversion, where a semi-honest MCP server attempts to reconstruct the user's private underlying intent solely by analyzing legitimate tool calls. To systematically assess this vulnerability, we propose IntentMiner, a framework that leverages Hierarchical Information Isolation and Three-Dimensional Semantic Analysis, integrating tool purpose, call statements, and returned results, to accurately infer user intent at the step level. Extensive experiments demonstrate that IntentMiner achieves a high degree of semantic alignment (over 85%) with original user queries, significantly outperforming baseline approaches. These results highlight the inherent privacy risks in decoupled agent architectures, revealing that seemingly benign tool execution logs can serve as a potent vector for exposing user secrets.
Scalable Mixed-Integer Optimization with Neural Constraints via Dual Decomposition
Nov 12, 2025Embedding deep neural networks (NNs) into mixed-integer programs (MIPs) is attractive for decision making with learned constraints, yet state-of-the-art monolithic linearisations blow up in size and quickly become intractable. In this paper, we introduce a novel dual-decomposition framework that relaxes the single coupling equality u=x with an augmented Lagrange multiplier and splits the problem into a vanilla MIP and a constrained NN block. Each part is tackled by the solver that suits it best-branch and cut for the MIP subproblem, first-order optimisation for the NN subproblem-so the model remains modular, the number of integer variables never grows with network depth, and the per-iteration cost scales only linearly with the NN size. On the public \textsc{SurrogateLIB} benchmark, our method proves \textbf{scalable}, \textbf{modular}, and \textbf{adaptable}: it runs \(120\times\) faster than an exact Big-M formulation on the largest test case; the NN sub-solver can be swapped from a log-barrier interior step to a projected-gradient routine with no code changes and identical objective value; and swapping the MLP for an LSTM backbone still completes the full optimisation in 47s without any bespoke adaptation.
MolChord: Structure-Sequence Alignment for Protein-Guided Drug Design
Oct 31, 2025Structure-based drug design (SBDD), which maps target proteins to candidate molecular ligands, is a fundamental task in drug discovery. Effectively aligning protein structural representations with molecular representations, and ensuring alignment between generated drugs and their pharmacological properties, remains a critical challenge. To address these challenges, we propose MolChord, which integrates two key techniques: (1) to align protein and molecule structures with their textual descriptions and sequential representations (e.g., FASTA for proteins and SMILES for molecules), we leverage NatureLM, an autoregressive model unifying text, small molecules, and proteins, as the molecule generator, alongside a diffusion-based structure encoder; and (2) to guide molecules toward desired properties, we curate a property-aware dataset by integrating preference data and refine the alignment process using Direct Preference Optimization (DPO). Experimental results on CrossDocked2020 demonstrate that our approach achieves state-of-the-art performance on key evaluation metrics, highlighting its potential as a practical tool for SBDD.
MVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
RainfalLTE: A Zero-effect Rainfall Sensing System Utilizing Existing LTE Infrastructure
May 20, 2025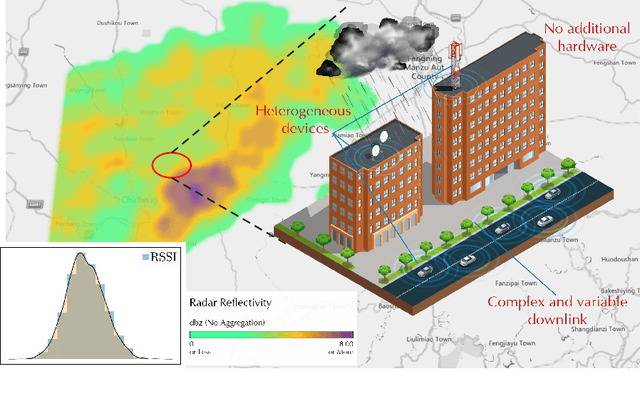



Environmental sensing is an important research topic in the integrated sensing and communication (ISAC) system. Current works often focus on static environments, such as buildings and terrains. However, dynamic factors like rainfall can cause serious interference to wireless signals. In this paper, we propose a system called RainfalLTE that utilizes the downlink signal of LTE base stations for device-independent rain sensing. In articular, it is fully compatible with current communication modes and does not require any additional hardware. We evaluate it with LTE data and rainfall information provided by a weather radar in Badaling Town, Beijing The results show that for 10 classes of rainfall, RainfalLTE achieves over 97% identification accuracy. Our case study shows that the assistance of rainfall information can bring more than 40% energy saving, which provides new opportunities for the design and optimization of ISAC systems.