 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentMiner: Intent Inversion Attack via Tool Call Analysis in the Model Context Protocol
Dec 16, 2025The rapid evolution of Large Language Models (LLMs) into autonomous agents has led to the adoption of the Model Context Protocol (MCP) as a standard for discovering and invoking external tools. While this architecture decouples the reasoning engine from tool execution to enhance scalability, it introduces a significant privacy surface: third-party MCP servers, acting as semi-honest intermediaries, can observe detailed tool interaction logs outside the user's trusted boundary. In this paper, we first identify and formalize a novel privacy threat termed Intent Inversion, where a semi-honest MCP server attempts to reconstruct the user's private underlying intent solely by analyzing legitimate tool calls. To systematically assess this vulnerability, we propose IntentMiner, a framework that leverages Hierarchical Information Isolation and Three-Dimensional Semantic Analysis, integrating tool purpose, call statements, and returned results, to accurately infer user intent at the step level. Extensive experiments demonstrate that IntentMiner achieves a high degree of semantic alignment (over 85%) with original user queries, significantly outperforming baseline approaches. These results highlight the inherent privacy risks in decoupled agent architectures, revealing that seemingly benign tool execution logs can serve as a potent vector for exposing user secrets.
STAMImputer: Spatio-Temporal Attention MoE for Traffic Data Imputation
Jun 11, 2025Traffic data imputation is fundamentally important to support various applications in intelligent transportation systems such as traffic flow prediction. However, existing time-to-space sequential methods often fail to effectively extract features in block-wise missing data scenarios. Meanwhile, the static graph structure for spatial feature propagation significantly constrains the models flexibility in handling the distribution shift issue for the nonstationary traffic data. To address these issues, this paper proposes a SpatioTemporal Attention Mixture of experts network named STAMImputer for traffic data imputation. Specifically, we introduce a Mixture of Experts (MoE) framework to capture latent spatio-temporal features and their influence weights, effectively imputing block missing. A novel Low-rank guided Sampling Graph ATtention (LrSGAT) mechanism is designed to dynamically balance the local and global correlations across road networks. The sampled attention vectors are utilized to generate dynamic graphs that capture real-time spatial correlations. Extensive experiments are conducted on four traffic datasets for evaluation. The result shows STAMImputer achieves significantly performance improvement compared with existing SOTA approaches. Our codes are available at https://github.com/RingBDStack/STAMImupter.
RainfalLTE: A Zero-effect Rainfall Sensing System Utilizing Existing LTE Infrastructure
May 20, 2025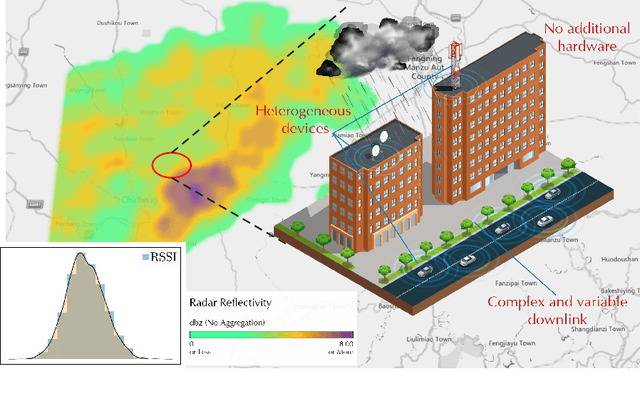



Environmental sensing is an important research topic in the integrated sensing and communication (ISAC) system. Current works often focus on static environments, such as buildings and terrains. However, dynamic factors like rainfall can cause serious interference to wireless signals. In this paper, we propose a system called RainfalLTE that utilizes the downlink signal of LTE base stations for device-independent rain sensing. In articular, it is fully compatible with current communication modes and does not require any additional hardware. We evaluate it with LTE data and rainfall information provided by a weather radar in Badaling Town, Beijing The results show that for 10 classes of rainfall, RainfalLTE achieves over 97% identification accuracy. Our case study shows that the assistance of rainfall information can bring more than 40% energy saving, which provides new opportunities for the design and optimization of ISAC systems.
RINN: One Sample Radio Frequency Imaging based on Physics Informed Neural Network
Apr 19, 2025



Due to its ability to work in non-line-of-sight and low-light environments, radio frequency (RF) imaging technology is expected to bring new possibilities for embodied intelligence and multimodal sensing. However, widely used RF devices (such as Wi-Fi) often struggle to provide high-precision electromagnetic measurements and large-scale datasets, hindering the application of RF imaging technology. In this paper, we combine the ideas of PINN to design the RINN network, using physical constraints instead of true value comparison constraints and adapting it with the characteristics of ubiquitous RF signals, allowing the RINN network to achieve RF imaging using only one sample without phase and with amplitude noise. Our numerical evaluation results show that compared with 5 classic algorithms based on phase data for imaging results, RINN's imaging results based on phaseless data are good, with indicators such as RRMSE (0.11) performing similarly well. RINN provides new possibilities for the universal development of radio frequency imaging technology.
The Field-based Model: A New Perspective on RF-based Material Sensing
Dec 07, 2024



This paper introduces the design and implementation of WiField, a WiFi sensing system deployed on COTS devices that can simultaneously identify multiple wavelength-level targets placed flexibly. Unlike traditional RF sensing schemes that focus on specific targets and RF links, WiField focuses on all media in the sensing area for the entire electric field. In this perspective, WiField provides a unified framework to finely characterize the diffraction, scattering, and other effects of targets at different positions, materials, and numbers on signals. The combination of targets in different positions, numbers, and sizes is just a special case. WiField proposed a scheme that utilizes phaseless data to complete the inverse mapping from electric field to material distribution, thereby achieving the simultaneous identification of multiple wavelength-level targets at any position and having the potential for deployment on a wide range of low-cost COTS devices. Our evaluation results show that it has an average identification accuracy of over 97% for 1-3 targets (5 cm * 10 cm in size) with different materials randomly placed within a 1.05 m * 1.05 m area.
Research on Personalized Compression Algorithm for Pre-trained Models Based on Homomorphic Entropy Increase
Aug 16, 2024In this article, we explore the challenges and evolution of two key technologies in the current field of AI: Vision Transformer model and Large Language Model (LLM). Vision Transformer captures global information by splitting images into small pieces and leveraging Transformer's multi-head attention mechanism, but its high reference count and compute overhead limit deployment on mobile devices. At the same time, the rapid development of LLM has revolutionized natural language processing, but it also faces huge deployment challenges. To address these issues, we investigate model pruning techniques, with a particular focus on how to reduce redundant parameters without losing accuracy to accommodate personalized data and resource-constrained environments. In this paper, a new layered pruning strategy is proposed to distinguish the personalized layer from the common layer by compressed sensing and random sampling, thus significantly reducing the model parameters. Our experimental results show that the introduced step buffering mechanism further improves the accuracy of the model after pruning, providing new directions and possibilities for the deployment of efficient and personalized AI models on mobile devices in the future.
SGSM: A Foundation-model-like Semi-generalist Sensing Model
Jun 15, 2024

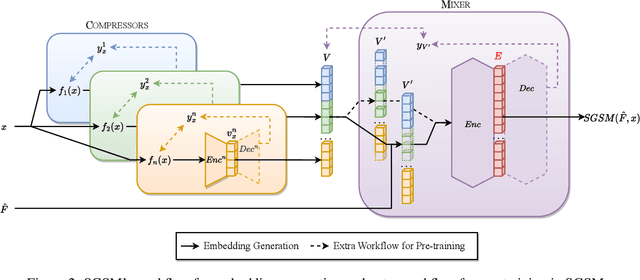

The significance of intelligent sensing systems is growing in the realm of smart services. These systems extract relevant signal features and generate informative representations for particular tasks. However, building the feature extraction component for such systems requires extensive domain-specific expertise or data. The exceptionally rapid development of foundation models is likely to usher in newfound abilities in such intelligent sensing. We propose a new scheme for sensing model, which we refer to as semi-generalist sensing model (SGSM). SGSM is able to semiautomatically solve various tasks using relatively less task-specific labeled data compared to traditional systems. Built through the analysis of the common theoretical model, SGSM can depict different modalities, such as the acoustic and Wi-Fi signal. Experimental results on such two heterogeneous sensors illustrate that SGSM functions across a wide range of scenarios, thereby establishing its broad applicability. In some cases, SGSM even achieves better performance than sensor-specific specialized solutions. Wi-Fi evaluations indicate a 20\% accuracy improvement when applying SGSM to an existing sensing model.
Towards the limits: Sensing Capability Measurement for ISAC Through Channel Encoder
May 15, 2024



Integrated Sensing and Communication (ISAC) is gradually becoming a reality due to the significant increase in frequency and bandwidth of next-generation wireless communication technologies. Therefore it becomes crucial to evaluate the communication and sensing performance using appropriate channel models to address resource competition from each other. Existing work only models the sensing capability based on the mutual information between the channel response and the received signal, and its theoretical resolution is difficult to support the high-precision requirements of ISAC for sensing tasks, and may even affect its communication optimal. In this paper, we propose a sensing channel encoder model to measure the sensing capacity with higher resolution by discrete task mutual information. For the first time, derive upper and lower bounds on the sensing accuracy for a given channel. This model not only provides the possibility of optimizing the ISAC systems at a finer granularity and balancing communication and sensing resources, but also provides theoretical explanations for classical intuitive feelings (like more modalities more accuracy) in wireless sensing. Furthermore, we validate the effectiveness of the proposed channel model through real-case studies, including person identification, displacement detection, direction estimation, and device recognition. The evaluation results indicate a Pearson correlation coefficient exceeding 0.9 between our task mutual information and conventional experimental metrics (e.g., accuracy).
RCoCo: Contrastive Collective Link Prediction across Multiplex Network in Riemannian Space
Mar 04, 2024Link prediction typically studies the probability of future interconnection among nodes with the observation in a single social network. More often than not, real scenario is presented as a multiplex network with common (anchor) users active in multiple social networks. In the literature, most existing works study either the intra-link prediction in a single network or inter-link prediction among networks (a.k.a. network alignment), and consider two learning tasks are independent from each other, which is still away from the fact. On the representation space, the vast majority of existing methods are built upon the traditional Euclidean space, unaware of the inherent geometry of social networks. The third issue is on the scarce anchor users. Annotating anchor users is laborious and expensive, and thus it is impractical to work with quantities of anchor users. Herein, in light of the issues above, we propose to study a challenging yet practical problem of Geometry-aware Collective Link Prediction across Multiplex Network. To address this problem, we present a novel contrastive model, RCoCo, which collaborates intra- and inter-network behaviors in Riemannian spaces. In RCoCo, we design a curvature-aware graph attention network ($\kappa-$GAT), conducting attention mechanism in Riemannian manifold whose curvature is estimated by the Ricci curvatures over the network. Thereafter, we formulate intra- and inter-contrastive loss in the manifolds, in which we augment graphs by exploring the high-order structure of community and information transfer on anchor users. Finally, we conduct extensive experiments with 14 strong baselines on 8 real-world datasets, and show the effectiveness of RCoCo.