 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-R2: An Adversarial Benchmark for Evidence-Grounded Reasoning in Medical VLMs
May 23, 2026Vision-language models have demonstrated impressive capabilities in general medical visual question answering, yet due to limited interpretability, it remains unclear whether their predictions reflect evidence-grounded clinical reasoning or reliance on spurious priors. We introduce Med-R2 Bench, a hierarchical benchmark aligned with the clinical workflow to evaluate adversarial robustness with visual grounding. We design stepwise QA tasks to assess whether reasoning chains are strictly grounded in visual evidence across the four clinical stages, and employ adversarial perturbations to test robustness against misleading cues. Med-R2 comprises 42,432 images, 31 task categories, and 110,406 QA pairs. Evaluation across 14 VLMs reveals a sequential performance degradation along the four-stage clinical workflow. Adversarial experiments show that models rely heavily on correct prompts to guess answers. Even when provided with explicit visual cues, the models struggle to accurately align textual descriptions. Finally, we demonstrate stepwise fine-tuning using our hierarchical data significantly improves reasoning robustness, highlighting its potential to drive future improvements in evidence-based medical AI.
HICT: High-precision 3D CBCT reconstruction from a single X-ray
Apr 01, 2026Accurate 3D dental imaging is vital for diagnosis and treatment planning, yet CBCT's high radiation dose and cost limit its accessibility. Reconstructing 3D volumes from a single low-dose panoramic X-ray is a promising alternative but remains challenging due to geometric inconsistencies and limited accuracy. We propose HiCT, a two-stage framework that first generates geometrically consistent multi-view projections from a single panoramic image using a video diffusion model, and then reconstructs high-fidelity CBCT from the projections using a ray-based dynamic attention network and an X-ray sampling strategy. To support this, we built XCT, a large-scale dataset combining public CBCT data with 500 paired PX-CBCT cases. Extensive experiments show that HiCT achieves state-of-the-art performance, delivering accurate and geometrically consistent reconstructions for clinical use.
Mitigating Posterior Salience Attenuation in Long-Context LLMs with Positional Contrastive Decoding
Jun 11, 2025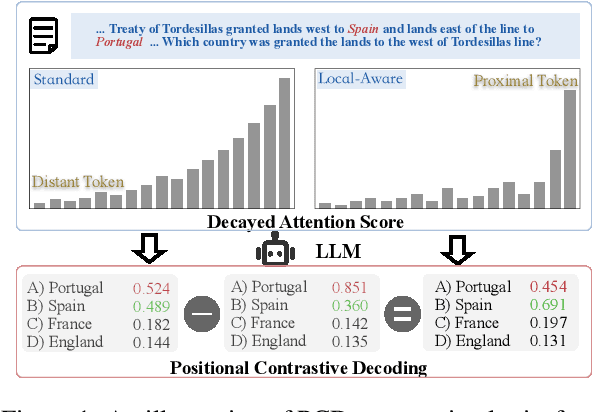
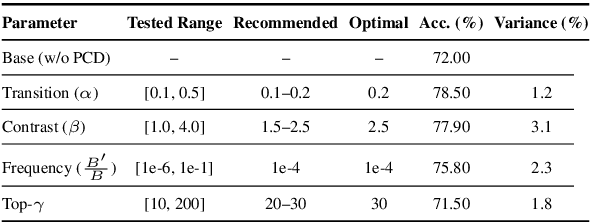
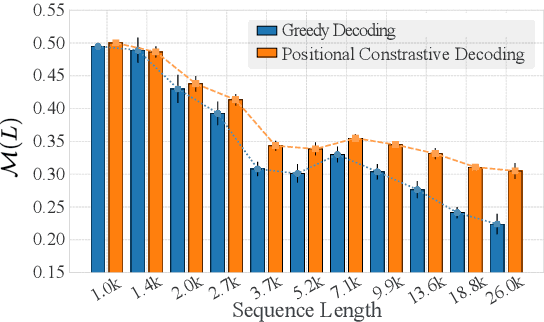
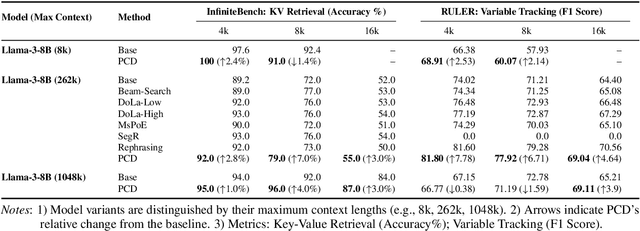
While Large Language Models (LLMs) support long contexts, they struggle with performance degradation within the context window. Current solutions incur prohibitive training costs, leaving statistical behaviors and cost-effective approaches underexplored. From the decoding perspective, we identify the Posterior Salience Attenuation (PSA) phenomenon, where the salience ratio correlates with long-text performance degradation. Notably, despite the attenuation, gold tokens still occupy high-ranking positions in the decoding space. Motivated by it, we propose the training-free Positional Contrastive Decoding (PCD) that contrasts the logits derived from long-aware attention with those from designed local-aware attention, enabling the model to focus on the gains introduced by large-scale short-to-long training. Through the analysis of long-term decay simulation, we demonstrate that PCD effectively alleviates attention score degradation. Experimental results show that PCD achieves state-of-the-art performance on long-context benchmarks.
PX2Tooth: Reconstructing the 3D Point Cloud Teeth from a Single Panoramic X-ray
Nov 06, 2024Reconstructing the 3D anatomical structures of the oral cavity, which originally reside in the cone-beam CT (CBCT), from a single 2D Panoramic X-ray(PX) remains a critical yet challenging task, as it can effectively reduce radiation risks and treatment costs during the diagnostic in digital dentistry. However, current methods are either error-prone or only trained/evaluated on small-scale datasets (less than 50 cases), resulting in compromised trustworthiness. In this paper, we propose PX2Tooth, a novel approach to reconstruct 3D teeth using a single PX image with a two-stage framework. First, we design the PXSegNet to segment the permanent teeth from the PX images, providing clear positional, morphological, and categorical information for each tooth. Subsequently, we design a novel tooth generation network (TGNet) that learns to transform random point clouds into 3D teeth. TGNet integrates the segmented patch information and introduces a Prior Fusion Module (PFM) to enhance the generation quality, especially in the root apex region. Moreover, we construct a dataset comprising 499 pairs of CBCT and Panoramic X-rays. Extensive experiments demonstrate that PX2Tooth can achieve an Intersection over Union (IoU) of 0.793, significantly surpassing previous methods, underscoring the great potential of artificial intelligence in digital dentistry.
Towards the limits: Sensing Capability Measurement for ISAC Through Channel Encoder
May 15, 2024



Integrated Sensing and Communication (ISAC) is gradually becoming a reality due to the significant increase in frequency and bandwidth of next-generation wireless communication technologies. Therefore it becomes crucial to evaluate the communication and sensing performance using appropriate channel models to address resource competition from each other. Existing work only models the sensing capability based on the mutual information between the channel response and the received signal, and its theoretical resolution is difficult to support the high-precision requirements of ISAC for sensing tasks, and may even affect its communication optimal. In this paper, we propose a sensing channel encoder model to measure the sensing capacity with higher resolution by discrete task mutual information. For the first time, derive upper and lower bounds on the sensing accuracy for a given channel. This model not only provides the possibility of optimizing the ISAC systems at a finer granularity and balancing communication and sensing resources, but also provides theoretical explanations for classical intuitive feelings (like more modalities more accuracy) in wireless sensing. Furthermore, we validate the effectiveness of the proposed channel model through real-case studies, including person identification, displacement detection, direction estimation, and device recognition. The evaluation results indicate a Pearson correlation coefficient exceeding 0.9 between our task mutual information and conventional experimental metrics (e.g., accuracy).
Super Efficient Neural Network for Compression Artifacts Reduction and Super Resolution
Jan 26, 2024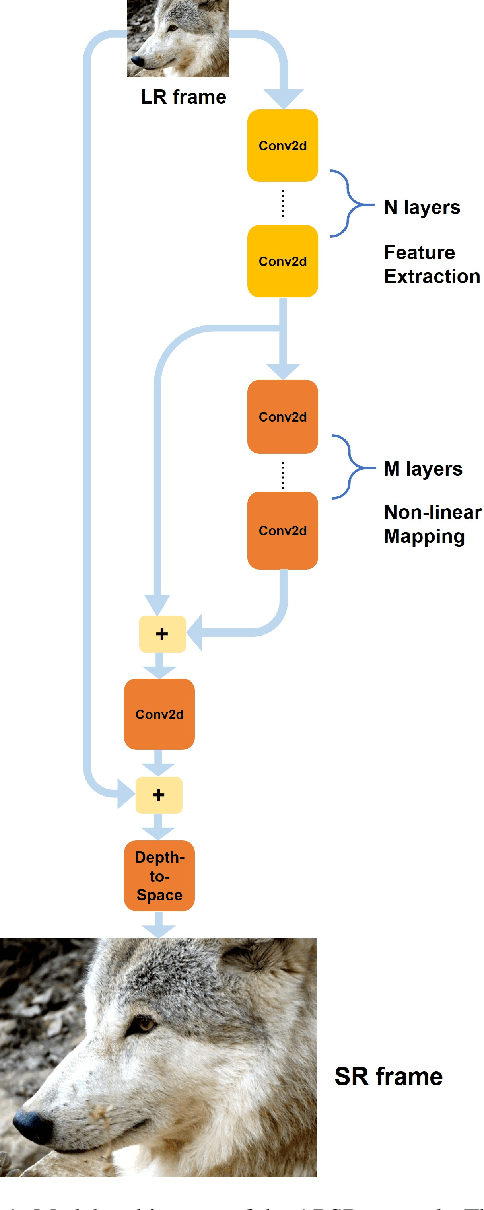
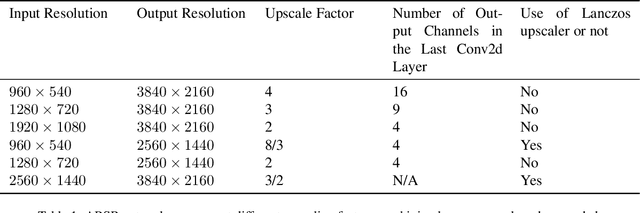
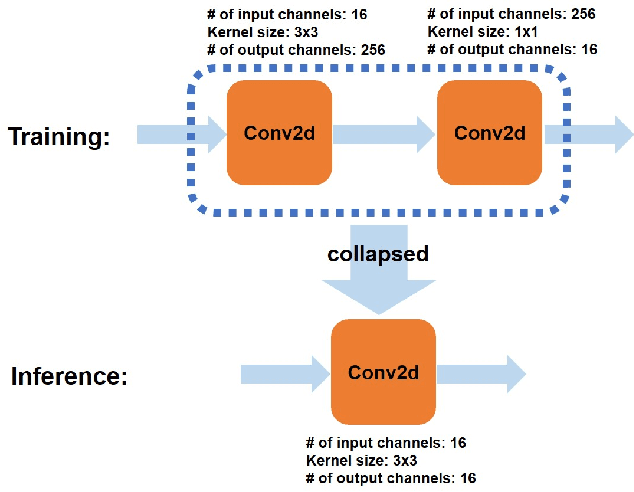

Video quality can suffer from limited internet speed while being streamed by users. Compression artifacts start to appear when the bitrate decreases to match the available bandwidth. Existing algorithms either focus on removing the compression artifacts at the same video resolution, or on upscaling the video resolution but not removing the artifacts. Super resolution-only approaches will amplify the artifacts along with the details by default. We propose a lightweight convolutional neural network (CNN)-based algorithm which simultaneously performs artifacts reduction and super resolution (ARSR) by enhancing the feature extraction layers and designing a custom training dataset. The output of this neural network is evaluated for test streams compressed at low bitrates using variable bitrate (VBR) encoding. The output video quality shows a 4-6 increase in video multi-method assessment fusion (VMAF) score compared to traditional interpolation upscaling approaches such as Lanczos or Bicubic.
Non-Volatile Memory Array Based Quantization- and Noise-Resilient LSTM Neural Networks
Feb 25, 2020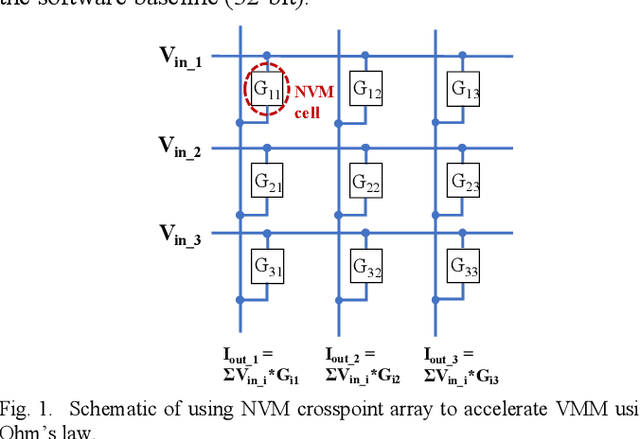
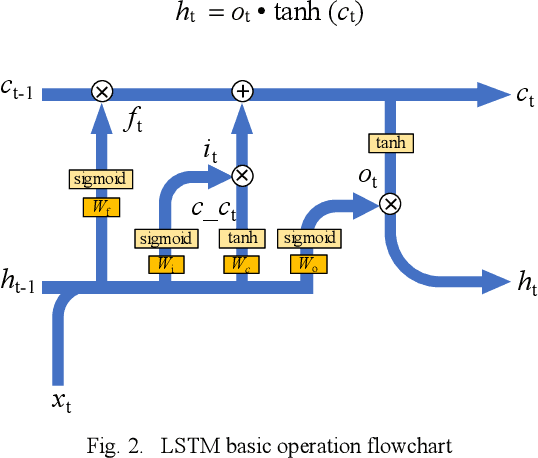
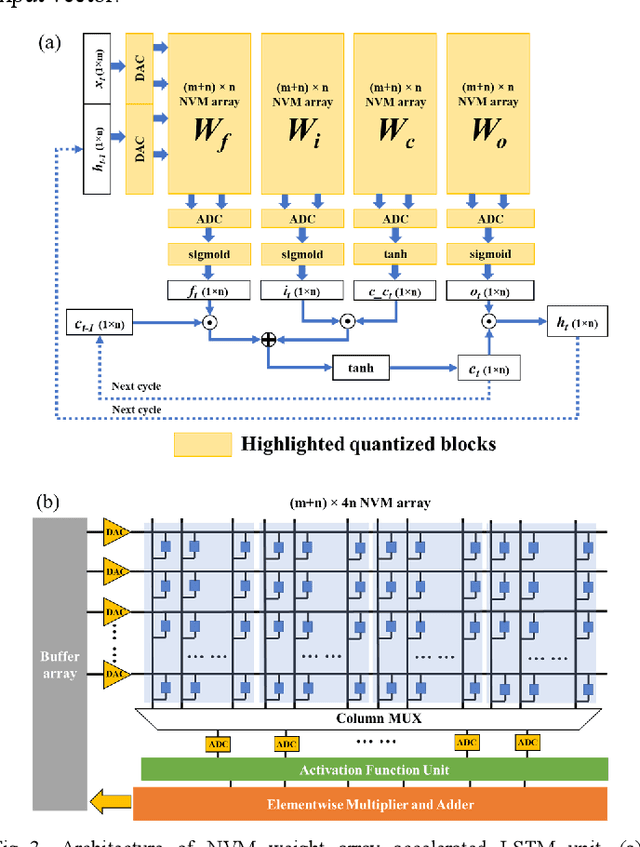
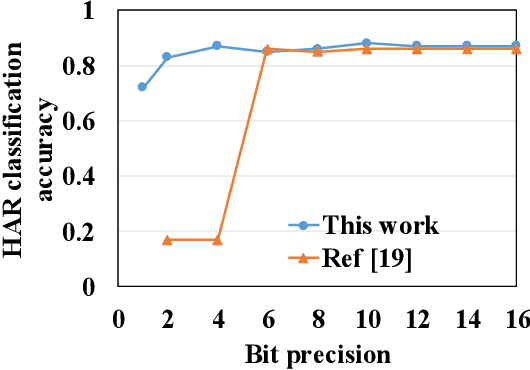
In cloud and edge computing models, it is important that compute devices at the edge be as power efficient as possible. Long short-term memory (LSTM) neural networks have been widely used for natural language processing, time series prediction and many other sequential data tasks. Thus, for these applications there is increasing need for low-power accelerators for LSTM model inference at the edge. In order to reduce power dissipation due to data transfers within inference devices, there has been significant interest in accelerating vector-matrix multiplication (VMM) operations using non-volatile memory (NVM) weight arrays. In NVM array-based hardware, reduced bit-widths also significantly increases the power efficiency. In this paper, we focus on the application of quantization-aware training algorithm to LSTM models, and the benefits these models bring in terms of resilience against both quantization error and analog device noise. We have shown that only 4-bit NVM weights and 4-bit ADC/DACs are needed to produce equivalent LSTM network performance as floating-point baseline. Reasonable levels of ADC quantization noise and weight noise can be naturally tolerated within our NVMbased quantized LSTM network. Benchmark analysis of our proposed LSTM accelerator for inference has shown at least 2.4x better computing efficiency and 40x higher area efficiency than traditional digital approaches (GPU, FPGA, and ASIC). Some other novel approaches based on NVM promise to deliver higher computing efficiency (up to 4.7x) but require larger arrays with potential higher error rates.