 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Efficient Neural Network for Compression Artifacts Reduction and Super Resolution
Jan 26, 2024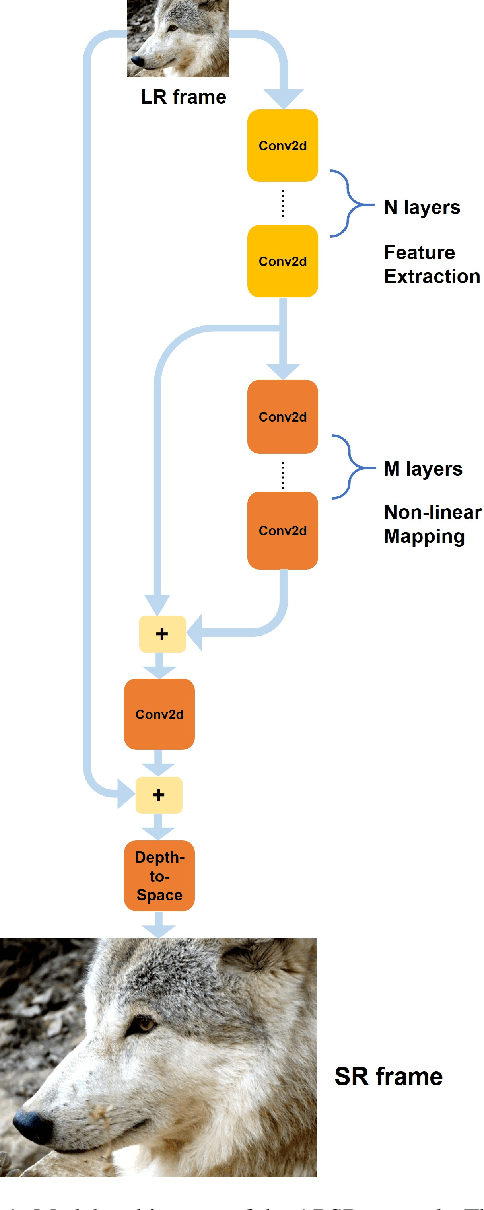
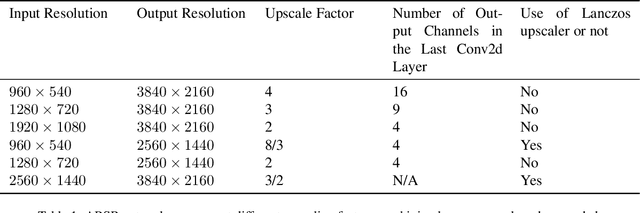
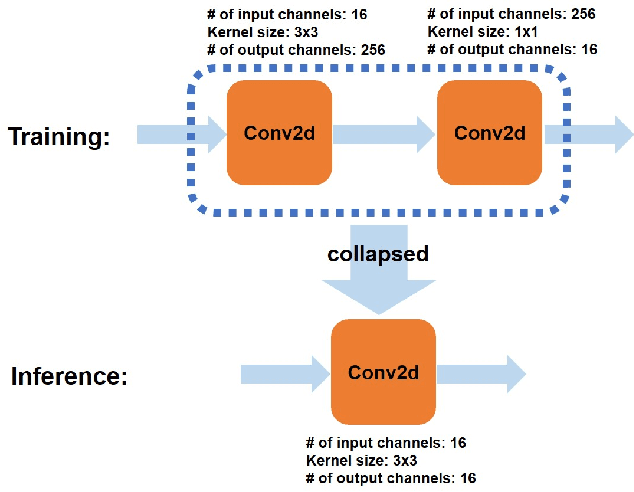

Video quality can suffer from limited internet speed while being streamed by users. Compression artifacts start to appear when the bitrate decreases to match the available bandwidth. Existing algorithms either focus on removing the compression artifacts at the same video resolution, or on upscaling the video resolution but not removing the artifacts. Super resolution-only approaches will amplify the artifacts along with the details by default. We propose a lightweight convolutional neural network (CNN)-based algorithm which simultaneously performs artifacts reduction and super resolution (ARSR) by enhancing the feature extraction layers and designing a custom training dataset. The output of this neural network is evaluated for test streams compressed at low bitrates using variable bitrate (VBR) encoding. The output video quality shows a 4-6 increase in video multi-method assessment fusion (VMAF) score compared to traditional interpolation upscaling approaches such as Lanczos or Bicubic.
MRQ:Support Multiple Quantization Schemes through Model Re-Quantization
Aug 04, 2023



Despite the proliferation of diverse hardware accelerators (e.g., NPU, TPU, DPU), deploying deep learning models on edge devices with fixed-point hardware is still challenging due to complex model quantization and conversion. Existing model quantization frameworks like Tensorflow QAT [1], TFLite PTQ [2], and Qualcomm AIMET [3] supports only a limited set of quantization schemes (e.g., only asymmetric per-tensor quantization in TF1.x QAT [4]). Accordingly, deep learning models cannot be easily quantized for diverse fixed-point hardwares, mainly due to slightly different quantization requirements. In this paper, we envision a new type of model quantization approach called MRQ (model re-quantization), which takes existing quantized models and quickly transforms the models to meet different quantization requirements (e.g., asymmetric -> symmetric, non-power-of-2 scale -> power-of-2 scale). Re-quantization is much simpler than quantizing from scratch because it avoids costly re-training and provides support for multiple quantization schemes simultaneously. To minimize re-quantization error, we developed a new set of re-quantization algorithms including weight correction and rounding error folding. We have demonstrated that MobileNetV2 QAT model [7] can be quickly re-quantized into two different quantization schemes (i.e., symmetric and symmetric+power-of-2 scale) with less than 0.64 units of accuracy loss. We believe our work is the first to leverage this concept of re-quantization for model quantization and models obtained from the re-quantization process have been successfully deployed on NNA in the Echo Show devices.
Accelerator-Aware Training for Transducer-Based Speech Recognition
May 12, 2023



Machine learning model weights and activations are represented in full-precision during training. This leads to performance degradation in runtime when deployed on neural network accelerator (NNA) chips, which leverage highly parallelized fixed-point arithmetic to improve runtime memory and latency. In this work, we replicate the NNA operators during the training phase, accounting for the degradation due to low-precision inference on the NNA in back-propagation. Our proposed method efficiently emulates NNA operations, thus foregoing the need to transfer quantization error-prone data to the Central Processing Unit (CPU), ultimately reducing the user perceived latency (UPL). We apply our approach to Recurrent Neural Network-Transducer (RNN-T), an attractive architecture for on-device streaming speech recognition tasks. We train and evaluate models on 270K hours of English data and show a 5-7% improvement in engine latency while saving up to 10% relative degradation in WER.
* Accepted to SLT 2022
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022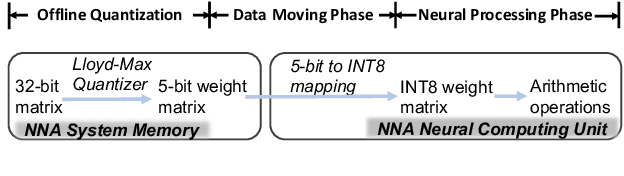
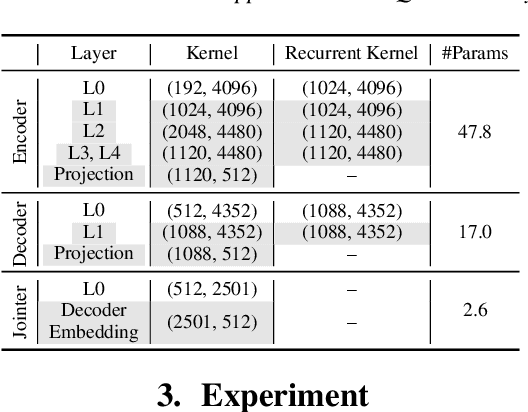
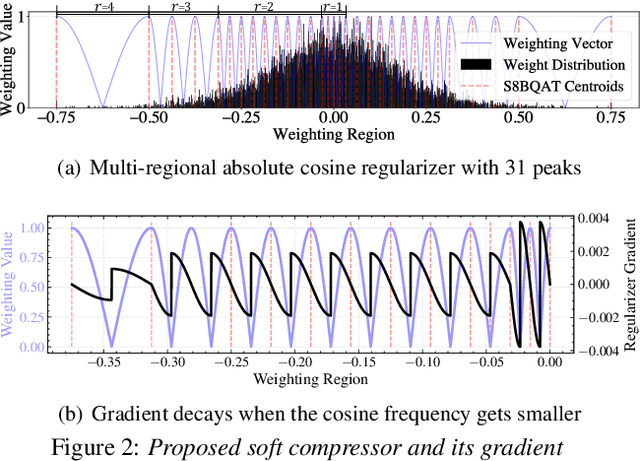
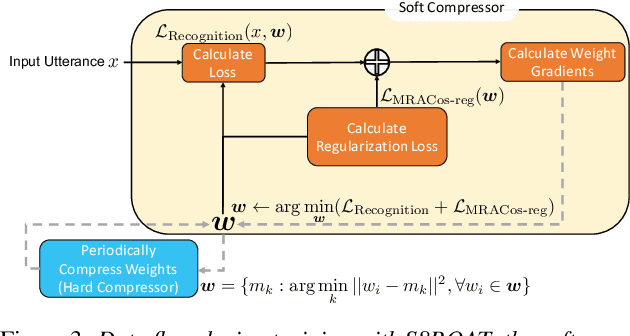
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
Apr 03, 2017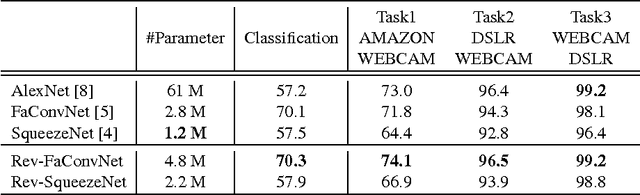
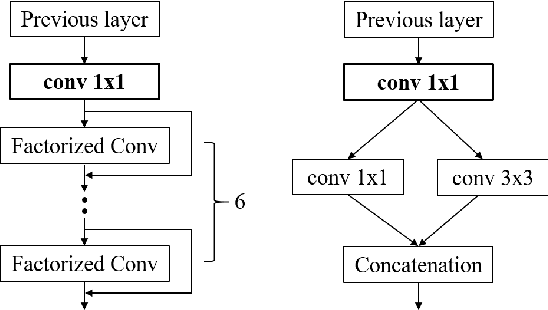
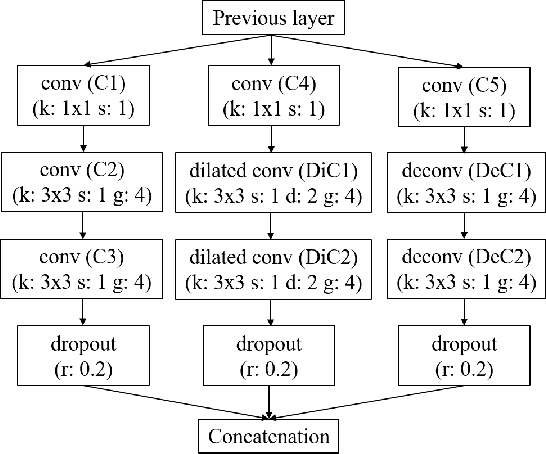
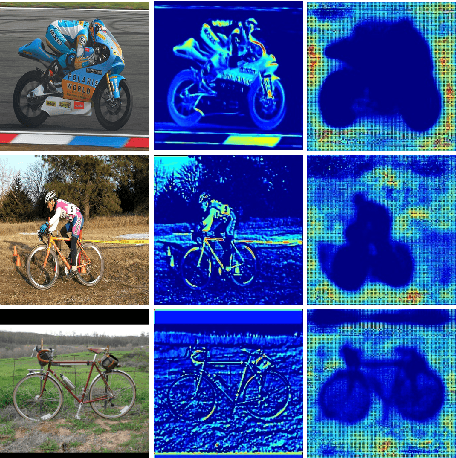
Recently, DNN model compression based on network architecture design, e.g., SqueezeNet, attracted a lot attention. No accuracy drop on image classification is observed on these extremely compact networks, compared to well-known models. An emerging question, however, is whether these model compression techniques hurt DNN's learning ability other than classifying images on a single dataset. Our preliminary experiment shows that these compression methods could degrade domain adaptation (DA) ability, though the classification performance is preserved. Therefore, we propose a new compact network architecture and unsupervised DA method in this paper. The DNN is built on a new basic module Conv-M which provides more diverse feature extractors without significantly increasing parameters. The unified framework of our DA method will simultaneously learn invariance across domains, reduce divergence of feature representations, and adapt label prediction. Our DNN has 4.1M parameters, which is only 6.7% of AlexNet or 59% of GoogLeNet. Experiments show that our DNN obtains GoogLeNet-level accuracy both on classification and DA, and our DA method slightly outperforms previous competitive ones. Put all together, our DA strategy based on our DNN achieves state-of-the-art on sixteen of total eighteen DA tasks on popular Office-31 and Office-Caltech datasets.