 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Efficient Neural Network for Compression Artifacts Reduction and Super Resolution
Jan 26, 2024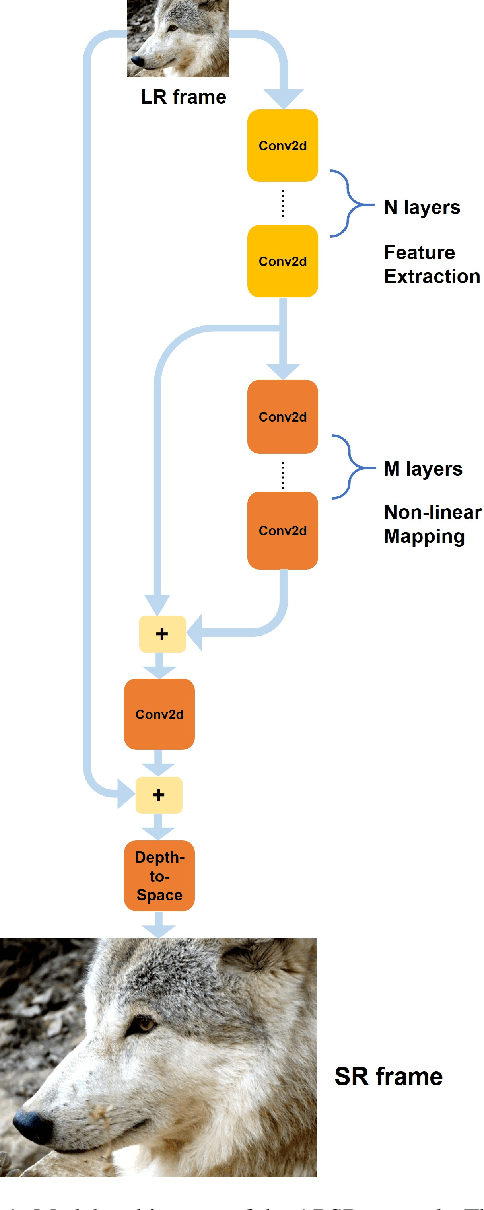
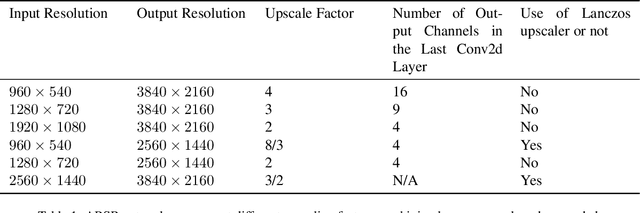
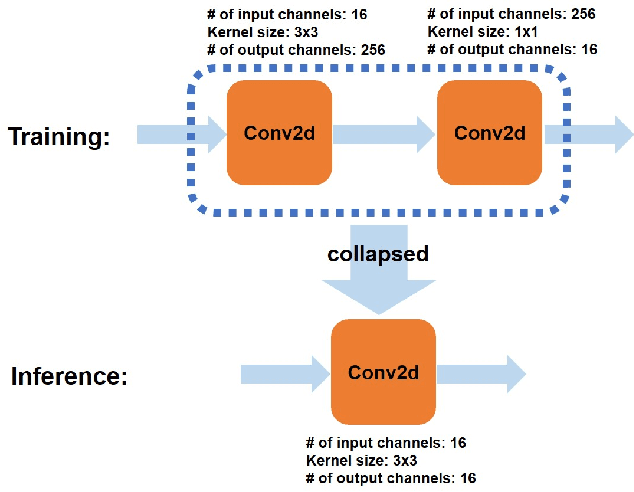

Video quality can suffer from limited internet speed while being streamed by users. Compression artifacts start to appear when the bitrate decreases to match the available bandwidth. Existing algorithms either focus on removing the compression artifacts at the same video resolution, or on upscaling the video resolution but not removing the artifacts. Super resolution-only approaches will amplify the artifacts along with the details by default. We propose a lightweight convolutional neural network (CNN)-based algorithm which simultaneously performs artifacts reduction and super resolution (ARSR) by enhancing the feature extraction layers and designing a custom training dataset. The output of this neural network is evaluated for test streams compressed at low bitrates using variable bitrate (VBR) encoding. The output video quality shows a 4-6 increase in video multi-method assessment fusion (VMAF) score compared to traditional interpolation upscaling approaches such as Lanczos or Bicubic.
AddNet: Deep Neural Networks Using FPGA-Optimized Multipliers
Nov 19, 2019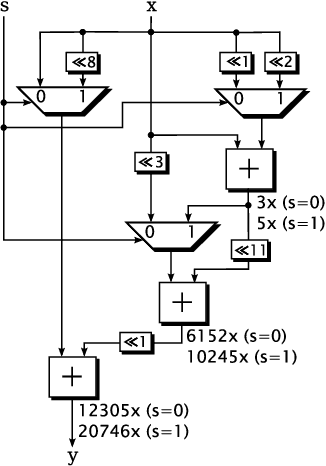
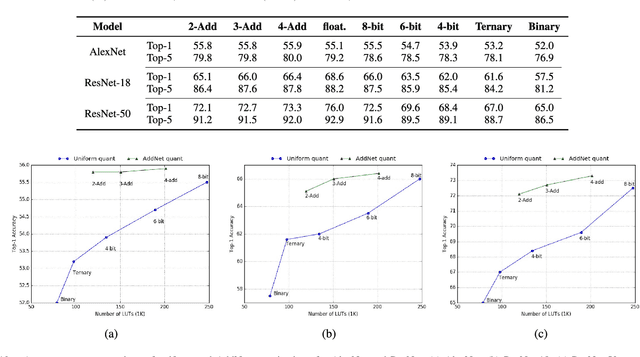
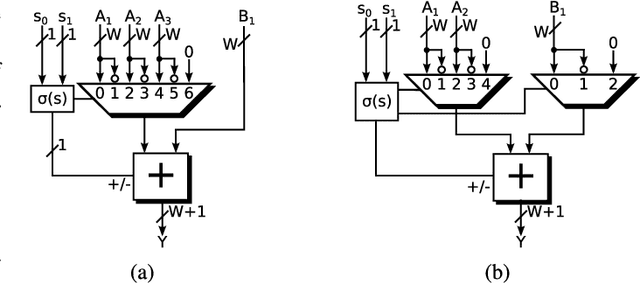
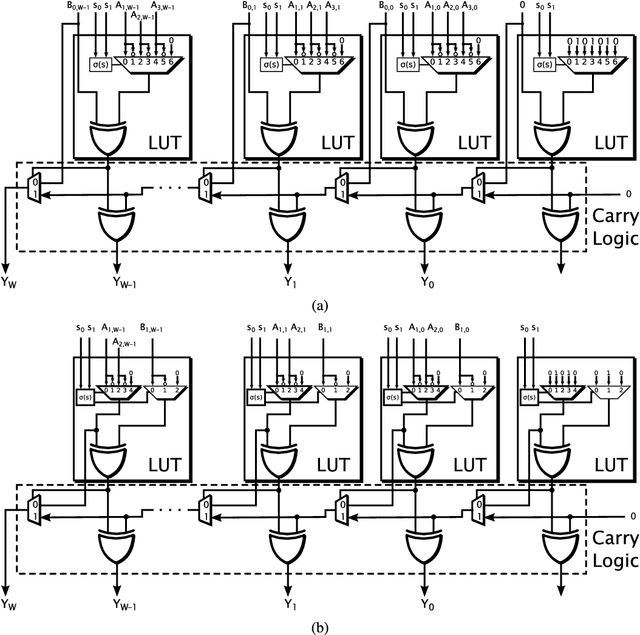
Low-precision arithmetic operations to accelerate deep-learning applications on field-programmable gate arrays (FPGAs) have been studied extensively, because they offer the potential to save silicon area or increase throughput. However, these benefits come at the cost of a decrease in accuracy. In this article, we demonstrate that reconfigurable constant coefficient multipliers (RCCMs) offer a better alternative for saving the silicon area than utilizing low-precision arithmetic. RCCMs multiply input values by a restricted choice of coefficients using only adders, subtractors, bit shifts, and multiplexers (MUXes), meaning that they can be heavily optimized for FPGAs. We propose a family of RCCMs tailored to FPGA logic elements to ensure their efficient utilization. To minimize information loss from quantization, we then develop novel training techniques that map the possible coefficient representations of the RCCMs to neural network weight parameter distributions. This enables the usage of the RCCMs in hardware, while maintaining high accuracy. We demonstrate the benefits of these techniques using AlexNet, ResNet-18, and ResNet-50 networks. The resulting implementations achieve up to 50% resource savings over traditional 8-bit quantized networks, translating to significant speedups and power savings. Our RCCM with the lowest resource requirements exceeds 6-bit fixed point accuracy, while all other implementations with RCCMs achieve at least similar accuracy to an 8-bit uniformly quantized design, while achieving significant resource savings.
SYQ: Learning Symmetric Quantization For Efficient Deep Neural Networks
Jul 01, 2018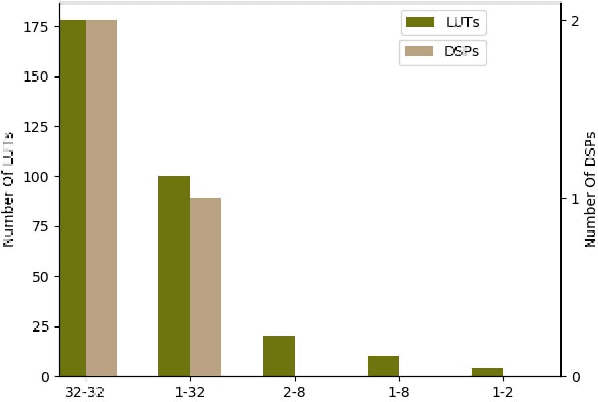
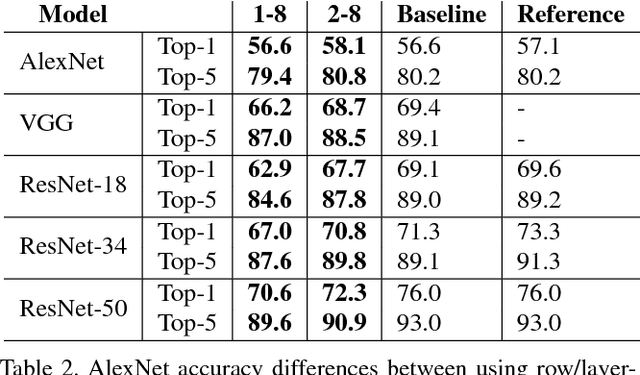
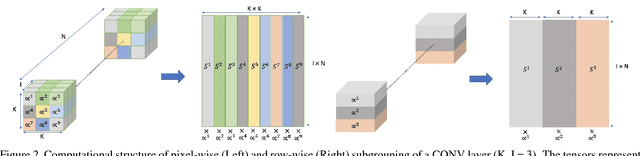
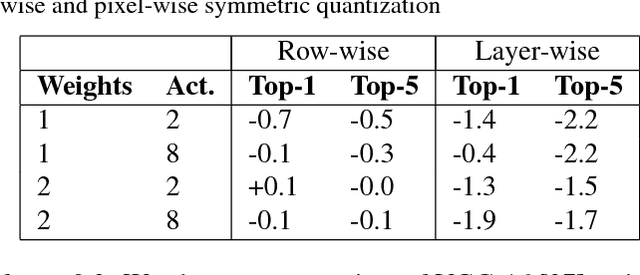
Inference for state-of-the-art deep neural networks is computationally expensive, making them difficult to deploy on constrained hardware environments. An efficient way to reduce this complexity is to quantize the weight parameters and/or activations during training by approximating their distributions with a limited entry codebook. For very low-precisions, such as binary or ternary networks with 1-8-bit activations, the information loss from quantization leads to significant accuracy degradation due to large gradient mismatches between the forward and backward functions. In this paper, we introduce a quantization method to reduce this loss by learning a symmetric codebook for particular weight subgroups. These subgroups are determined based on their locality in the weight matrix, such that the hardware simplicity of the low-precision representations is preserved. Empirically, we show that symmetric quantization can substantially improve accuracy for networks with extremely low-precision weights and activations. We also demonstrate that this representation imposes minimal or no hardware implications to more coarse-grained approaches. Source code is available at https://www.github.com/julianfaraone/SYQ.
Compressing Low Precision Deep Neural Networks Using Sparsity-Induced Regularization in Ternary Networks
Oct 10, 2017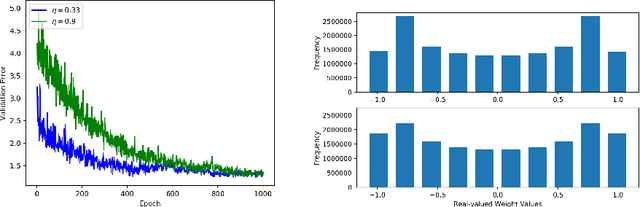
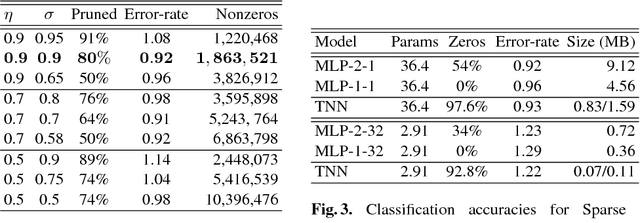
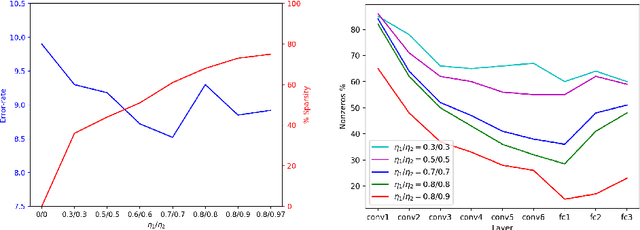
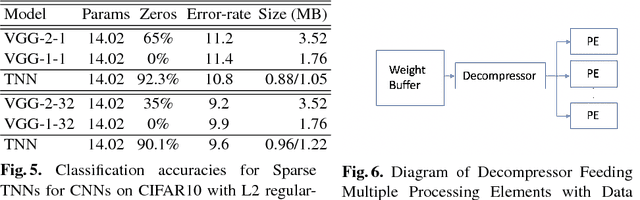
A low precision deep neural network training technique for producing sparse, ternary neural networks is presented. The technique incorporates hard- ware implementation costs during training to achieve significant model compression for inference. Training involves three stages: network training using L2 regularization and a quantization threshold regularizer, quantization pruning, and finally retraining. Resulting networks achieve improved accuracy, reduced memory footprint and reduced computational complexity compared with conventional methods, on MNIST and CIFAR10 datasets. Our networks are up to 98% sparse and 5 & 11 times smaller than equivalent binary and ternary models, translating to significant resource and speed benefits for hardware implementations.