 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Efficient Neural Network for Compression Artifacts Reduction and Super Resolution
Jan 26, 2024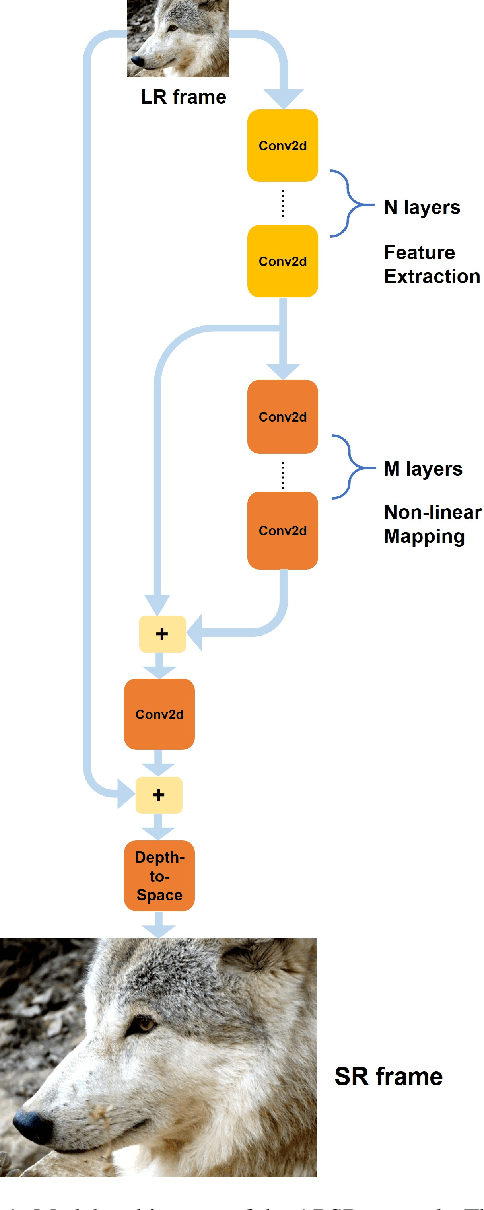
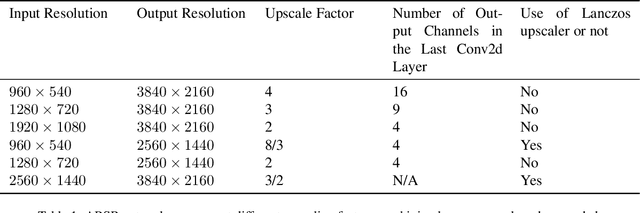
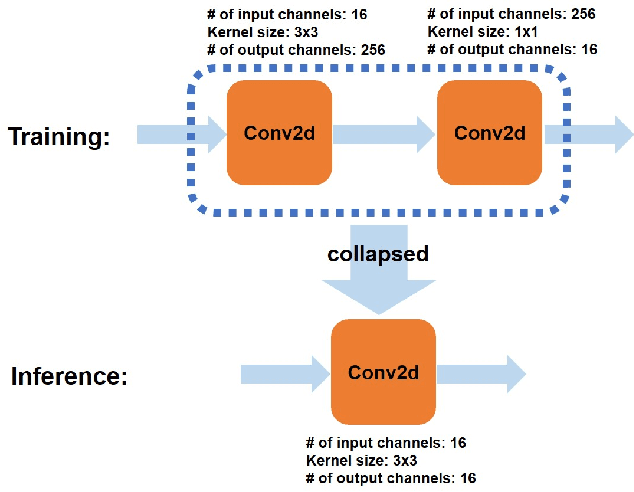

Video quality can suffer from limited internet speed while being streamed by users. Compression artifacts start to appear when the bitrate decreases to match the available bandwidth. Existing algorithms either focus on removing the compression artifacts at the same video resolution, or on upscaling the video resolution but not removing the artifacts. Super resolution-only approaches will amplify the artifacts along with the details by default. We propose a lightweight convolutional neural network (CNN)-based algorithm which simultaneously performs artifacts reduction and super resolution (ARSR) by enhancing the feature extraction layers and designing a custom training dataset. The output of this neural network is evaluated for test streams compressed at low bitrates using variable bitrate (VBR) encoding. The output video quality shows a 4-6 increase in video multi-method assessment fusion (VMAF) score compared to traditional interpolation upscaling approaches such as Lanczos or Bicubic.
Device-Circuit-Architecture Co-Exploration for Computing-in-Memory Neural Accelerators
Oct 31, 2019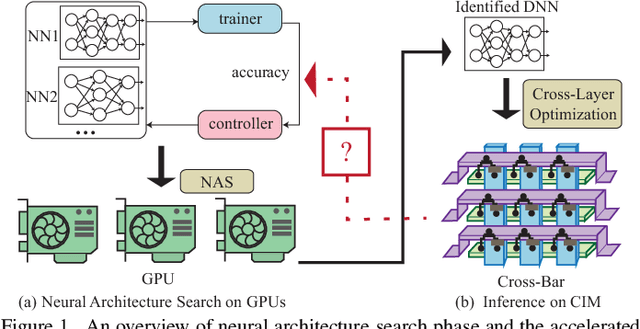
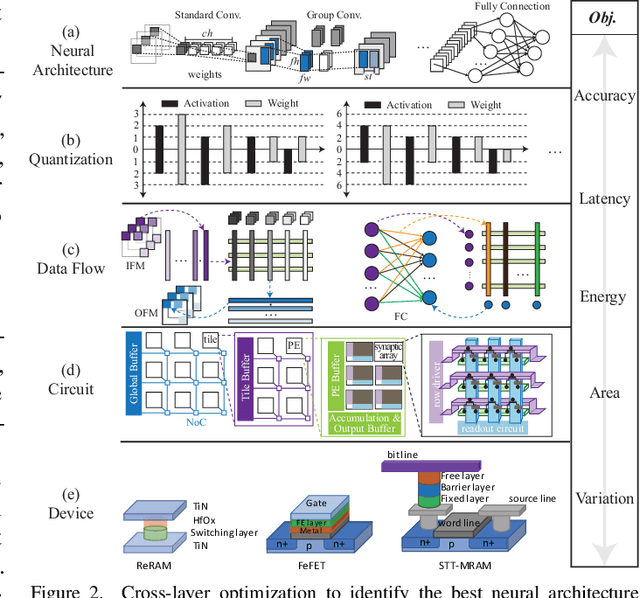
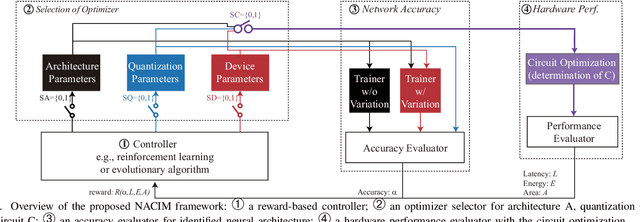
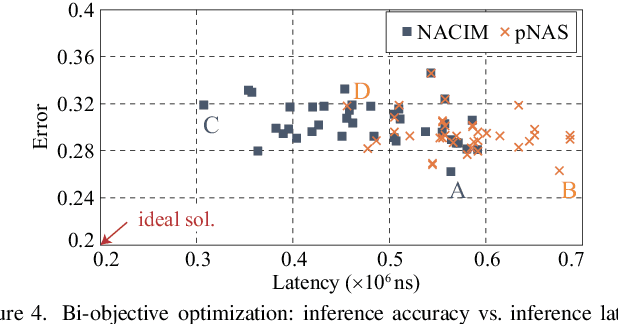
Co-exploration of neural architectures and hardware design is promising to simultaneously optimize network accuracy and hardware efficiency. However, state-of-the-art neural architecture search algorithms for the co-exploration are dedicated for the conventional von-neumann computing architecture, whose performance is heavily limited by the well-known memory wall. In this paper, we are the first to bring the computing-in-memory architecture, which can easily transcend the memory wall, to interplay with the neural architecture search, aiming to find the most efficient neural architectures with high network accuracy and maximized hardware efficiency. Such a novel combination makes opportunities to boost performance, but also brings a bunch of challenges. The design space spans across multiple layers from device type, circuit topology to neural architecture. In addition, the performance may degrade in the presence of device variation. To address these challenges, we propose a cross-layer exploration framework, namely NACIM, which jointly explores device, circuit and architecture design space and takes device variation into consideration to find the most robust neural architectures. Experimental results demonstrate that NACIM can find the robust neural network with 0.45% accuracy loss in the presence of device variation, compared with a 76.44% loss from the state-of-the-art NAS without consideration of variation; in addition, NACIM achieves an energy efficiency up to 16.3 TOPs/W, 3.17X higher than the state-of-the-art NAS.
Nonvolatile Spintronic Memory Cells for Neural Networks
May 29, 2019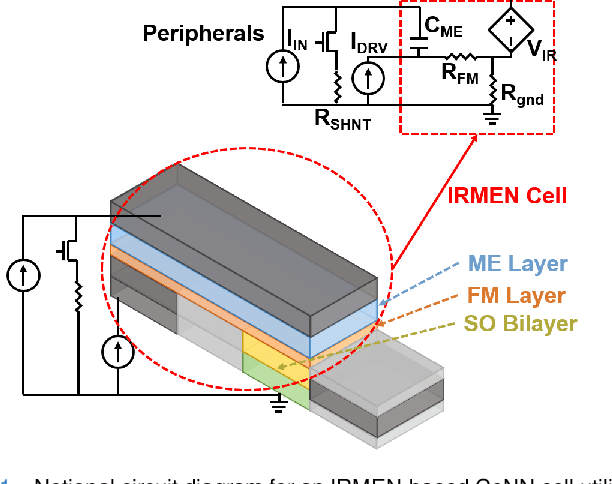
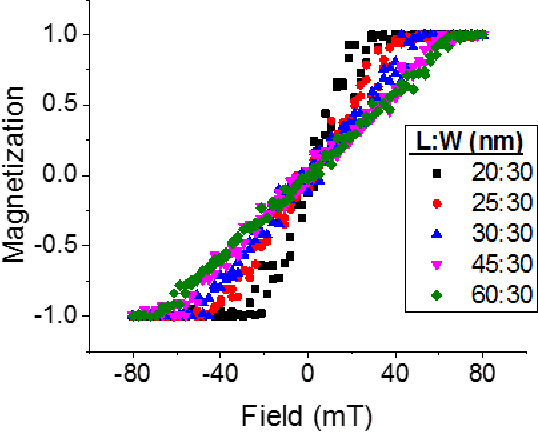
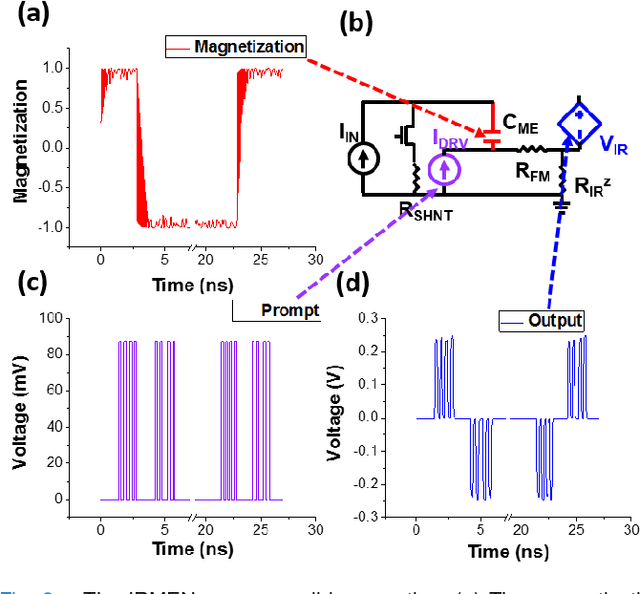
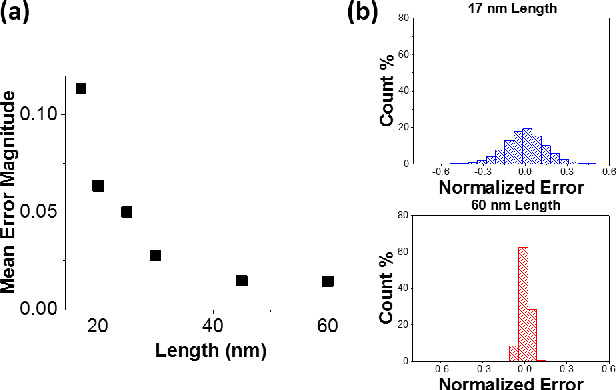
A new spintronic nonvolatile memory cell analogous to 1T DRAM with non-destructive read is proposed. The cells can be used as neural computing units. A dual-circuit neural network architecture is proposed to leverage these devices against the complex operations involved in convolutional networks. Simulations based on HSPICE and Matlab were performed to study the performance of this architecture when classifying images as well as the effect of varying the size and stability of the nanomagnets. The spintronic cells outperform a purely charge-based implementation of the same network, consuming about 100 pJ total per image processed.
Application-level Studies of Cellular Neural Network-based Hardware Accelerators
Feb 28, 2019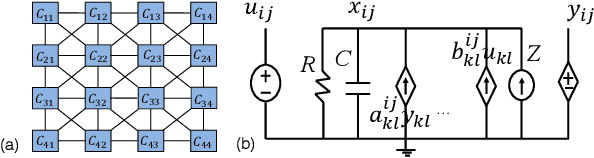
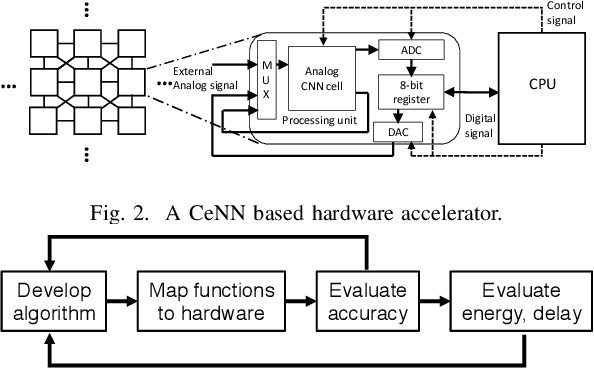
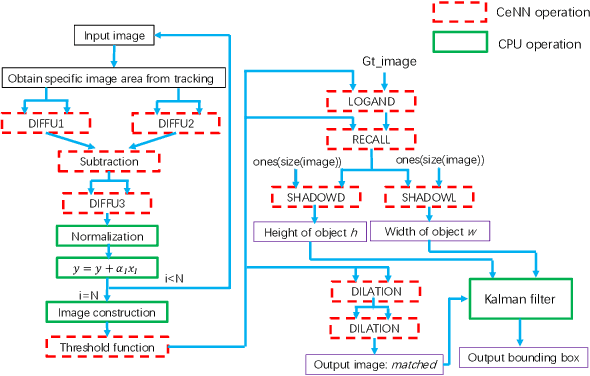
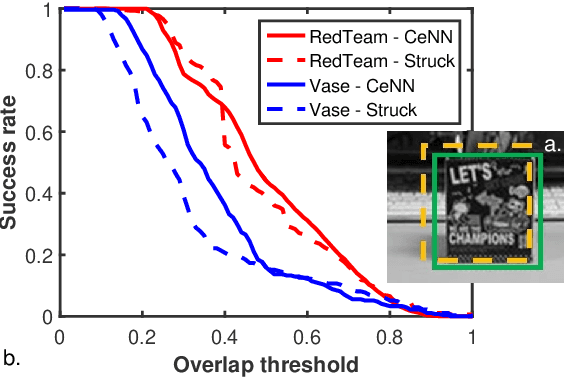
As cost and performance benefits associated with Moore's Law scaling slow, researchers are studying alternative architectures (e.g., based on analog and/or spiking circuits) and/or computational models (e.g., convolutional and recurrent neural networks) to perform application-level tasks faster, more energy efficiently, and/or more accurately. We investigate cellular neural network (CeNN)-based co-processors at the application-level for these metrics. While it is well-known that CeNNs can be well-suited for spatio-temporal information processing, few (if any) studies have quantified the energy/delay/accuracy of a CeNN-friendly algorithm and compared the CeNN-based approach to the best von Neumann algorithm at the application level. We present an evaluation framework for such studies. As a case study, a CeNN-friendly target-tracking algorithm was developed and mapped to an array architecture developed in conjunction with the algorithm. We compare the energy, delay, and accuracy of our architecture/algorithm (assuming all overheads) to the most accurate von Neumann algorithm (Struck). Von Neumann CPU data is measured on an Intel i5 chip. The CeNN approach is capable of matching the accuracy of Struck, and can offer approximately 1000x improvements in energy-delay product.
Design Flow of Accelerating Hybrid Extremely Low Bit-width Neural Network in Embedded FPGA
Oct 25, 2018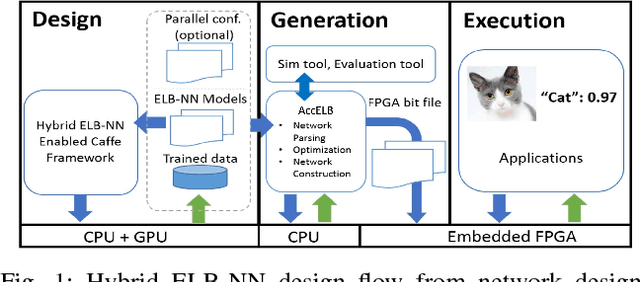
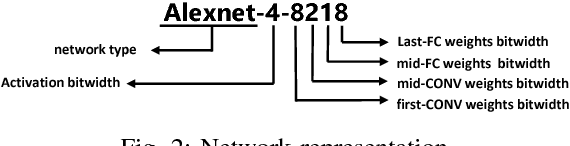
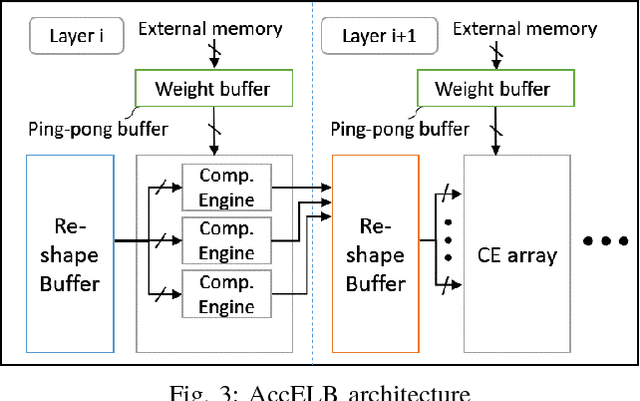
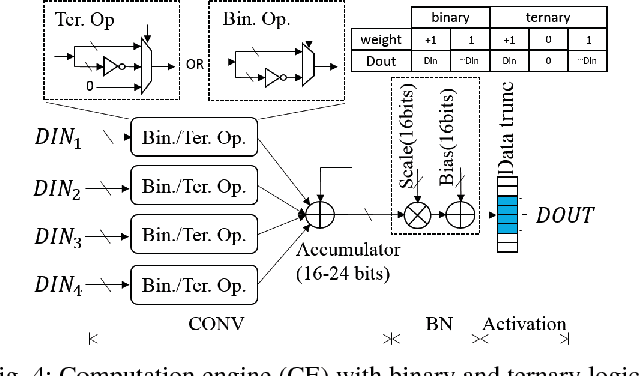
Neural network accelerators with low latency and low energy consumption are desirable for edge computing. To create such accelerators, we propose a design flow for accelerating the extremely low bit-width neural network (ELB-NN) in embedded FPGAs with hybrid quantization schemes. This flow covers both network training and FPGA-based network deployment, which facilitates the design space exploration and simplifies the tradeoff between network accuracy and computation efficiency. Using this flow helps hardware designers to deliver a network accelerator in edge devices under strict resource and power constraints. We present the proposed flow by supporting hybrid ELB settings within a neural network. Results show that our design can deliver very high performance peaking at 10.3 TOPS and classify up to 325.3 image/s/watt while running large-scale neural networks for less than 5W using embedded FPGA. To the best of our knowledge, it is the most energy efficient solution in comparison to GPU or other FPGA implementations reported so far in the literature.