 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorHD: A Hyperdimensional Computing Model for Multi-Object Multi-Class Representation and Factorization
Jul 16, 2025Neuro-symbolic artificial intelligence (neuro-symbolic AI) excels in logical analysis and reasoning. Hyperdimensional Computing (HDC), a promising brain-inspired computational model, is integral to neuro-symbolic AI. Various HDC models have been proposed to represent class-instance and class-class relations, but when representing the more complex class-subclass relation, where multiple objects associate different levels of classes and subclasses, they face challenges for factorization, a crucial task for neuro-symbolic AI systems. In this article, we propose FactorHD, a novel HDC model capable of representing and factorizing the complex class-subclass relation efficiently. FactorHD features a symbolic encoding method that embeds an extra memorization clause, preserving more information for multiple objects. In addition, it employs an efficient factorization algorithm that selectively eliminates redundant classes by identifying the memorization clause of the target class. Such model significantly enhances computing efficiency and accuracy in representing and factorizing multiple objects with class-subclass relation, overcoming limitations of existing HDC models such as "superposition catastrophe" and "the problem of 2". Evaluations show that FactorHD achieves approximately 5667x speedup at a representation size of 10^9 compared to existing HDC models. When integrated with the ResNet-18 neural network, FactorHD achieves 92.48% factorization accuracy on the Cifar-10 dataset.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024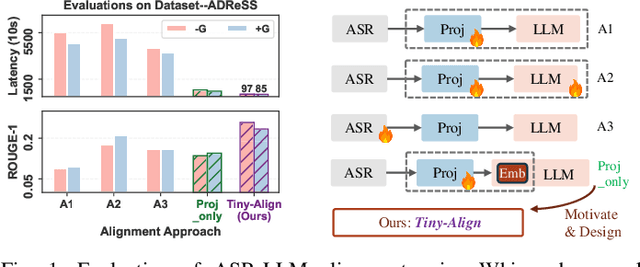
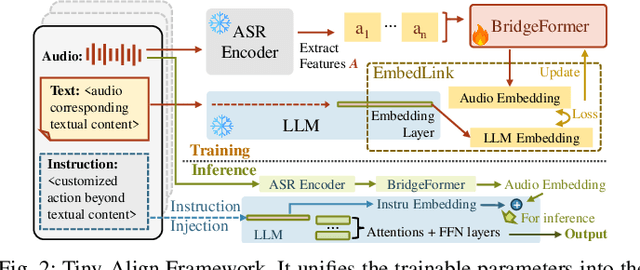
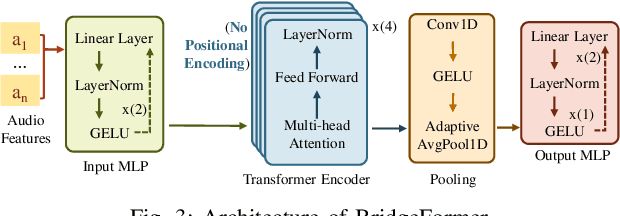
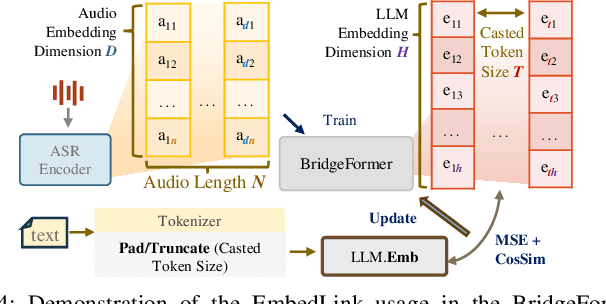
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
NVCiM-PT: An NVCiM-assisted Prompt Tuning Framework for Edge LLMs
Nov 12, 2024



Large Language Models (LLMs) deployed on edge devices, known as edge LLMs, need to continuously fine-tune their model parameters from user-generated data under limited resource constraints. However, most existing learning methods are not applicable for edge LLMs because of their reliance on high resources and low learning capacity. Prompt tuning (PT) has recently emerged as an effective fine-tuning method for edge LLMs by only modifying a small portion of LLM parameters, but it suffers from user domain shifts, resulting in repetitive training and losing resource efficiency. Conventional techniques to address domain shift issues often involve complex neural networks and sophisticated training, which are incompatible for PT for edge LLMs. Therefore, an open research question is how to address domain shift issues for edge LLMs with limited resources. In this paper, we propose a prompt tuning framework for edge LLMs, exploiting the benefits offered by non-volatile computing-in-memory (NVCiM) architectures. We introduce a novel NVCiM-assisted PT framework, where we narrow down the core operations to matrix-matrix multiplication, which can then be accelerated by performing in-situ computation on NVCiM. To the best of our knowledge, this is the first work employing NVCiM to improve the edge LLM PT performance.
A 10.60 $μ$W 150 GOPS Mixed-Bit-Width Sparse CNN Accelerator for Life-Threatening Ventricular Arrhythmia Detection
Oct 22, 2024



This paper proposes an ultra-low power, mixed-bit-width sparse convolutional neural network (CNN) accelerator to accelerate ventricular arrhythmia (VA) detection. The chip achieves 50% sparsity in a quantized 1D CNN using a sparse processing element (SPE) architecture. Measurement on the prototype chip TSMC 40nm CMOS low-power (LP) process for the VA classification task demonstrates that it consumes 10.60 $\mu$W of power while achieving a performance of 150 GOPS and a diagnostic accuracy of 99.95%. The computation power density is only 0.57 $\mu$W/mm$^2$, which is 14.23X smaller than state-of-the-art works, making it highly suitable for implantable and wearable medical devices.
Rethinking Medical Anomaly Detection in Brain MRI: An Image Quality Assessment Perspective
Aug 15, 2024



Reconstruction-based methods, particularly those leveraging autoencoders, have been widely adopted to perform anomaly detection in brain MRI. While most existing works try to improve detection accuracy by proposing new model structures or algorithms, we tackle the problem through image quality assessment, an underexplored perspective in the field. We propose a fusion quality loss function that combines Structural Similarity Index Measure loss with l1 loss, offering a more comprehensive evaluation of reconstruction quality. Additionally, we introduce a data pre-processing strategy that enhances the average intensity ratio (AIR) between normal and abnormal regions, further improving the distinction of anomalies. By fusing the aforementioned two methods, we devise the image quality assessment (IQA) approach. The proposed IQA approach achieves significant improvements (>10%) in terms of Dice coefficient (DICE) and Area Under the Precision-Recall Curve (AUPRC) on the BraTS21 (T2, FLAIR) and MSULB datasets when compared with state-of-the-art methods. These results highlight the importance of invoking the comprehensive image quality assessment in medical anomaly detection and provide a new perspective for future research in this field.
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Jun 06, 2024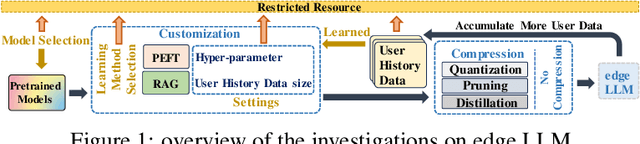
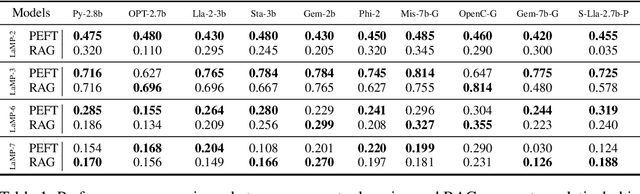
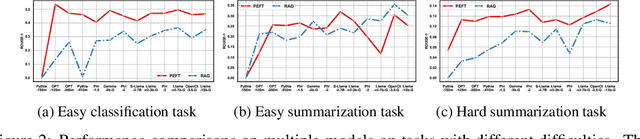

The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024



Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
FL-NAS: Towards Fairness of NAS for Resource Constrained Devices via Large Language Models
Feb 09, 2024Neural Architecture Search (NAS) has become the de fecto tools in the industry in automating the design of deep neural networks for various applications, especially those driven by mobile and edge devices with limited computing resources. The emerging large language models (LLMs), due to their prowess, have also been incorporated into NAS recently and show some promising results. This paper conducts further exploration in this direction by considering three important design metrics simultaneously, i.e., model accuracy, fairness, and hardware deployment efficiency. We propose a novel LLM-based NAS framework, FL-NAS, in this paper, and show experimentally that FL-NAS can indeed find high-performing DNNs, beating state-of-the-art DNN models by orders-of-magnitude across almost all design considerations.
Compute-in-Memory based Neural Network Accelerators for Safety-Critical Systems: Worst-Case Scenarios and Protections
Dec 11, 2023



Emerging non-volatile memory (NVM)-based Computing-in-Memory (CiM) architectures show substantial promise in accelerating deep neural networks (DNNs) due to their exceptional energy efficiency. However, NVM devices are prone to device variations. Consequently, the actual DNN weights mapped to NVM devices can differ considerably from their targeted values, inducing significant performance degradation. Many existing solutions aim to optimize average performance amidst device variations, which is a suitable strategy for general-purpose conditions. However, the worst-case performance that is crucial for safety-critical applications is largely overlooked in current research. In this study, we define the problem of pinpointing the worst-case performance of CiM DNN accelerators affected by device variations. Additionally, we introduce a strategy to identify a specific pattern of the device value deviations in the complex, high-dimensional value deviation space, responsible for this worst-case outcome. Our findings reveal that even subtle device variations can precipitate a dramatic decline in DNN accuracy, posing risks for CiM-based platforms in supporting safety-critical applications. Notably, we observe that prevailing techniques to bolster average DNN performance in CiM accelerators fall short in enhancing worst-case scenarios. In light of this issue, we propose a novel worst-case-aware training technique named A-TRICE that efficiently combines adversarial training and noise-injection training with right-censored Gaussian noise to improve the DNN accuracy in the worst-case scenarios. Our experimental results demonstrate that A-TRICE improves the worst-case accuracy under device variations by up to 33%.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.