 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024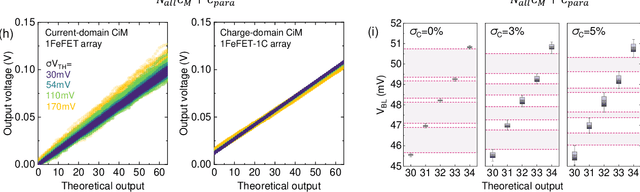
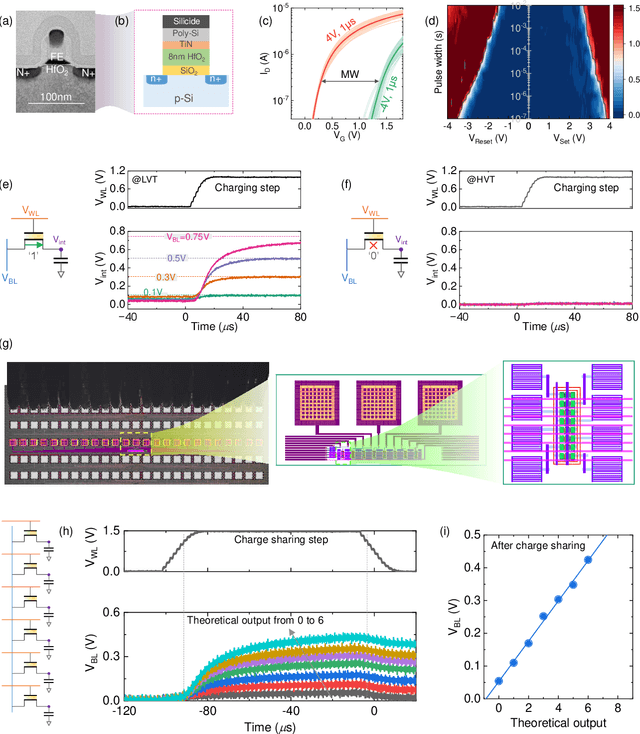
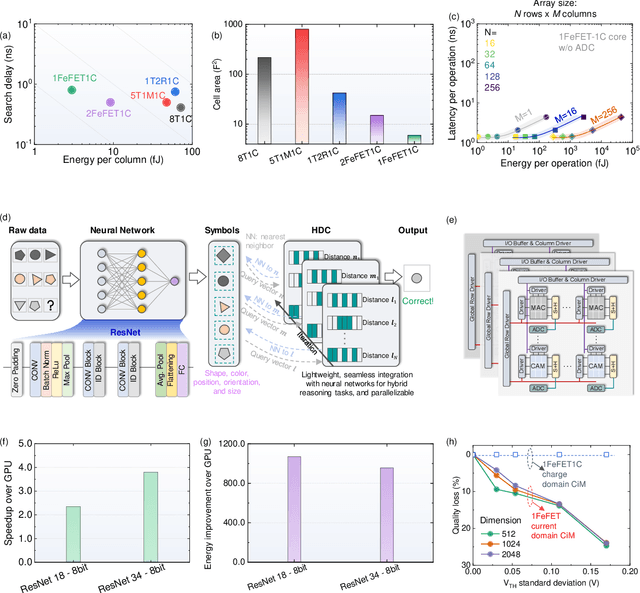
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
Compute-in-Memory based Neural Network Accelerators for Safety-Critical Systems: Worst-Case Scenarios and Protections
Dec 11, 2023



Emerging non-volatile memory (NVM)-based Computing-in-Memory (CiM) architectures show substantial promise in accelerating deep neural networks (DNNs) due to their exceptional energy efficiency. However, NVM devices are prone to device variations. Consequently, the actual DNN weights mapped to NVM devices can differ considerably from their targeted values, inducing significant performance degradation. Many existing solutions aim to optimize average performance amidst device variations, which is a suitable strategy for general-purpose conditions. However, the worst-case performance that is crucial for safety-critical applications is largely overlooked in current research. In this study, we define the problem of pinpointing the worst-case performance of CiM DNN accelerators affected by device variations. Additionally, we introduce a strategy to identify a specific pattern of the device value deviations in the complex, high-dimensional value deviation space, responsible for this worst-case outcome. Our findings reveal that even subtle device variations can precipitate a dramatic decline in DNN accuracy, posing risks for CiM-based platforms in supporting safety-critical applications. Notably, we observe that prevailing techniques to bolster average DNN performance in CiM accelerators fall short in enhancing worst-case scenarios. In light of this issue, we propose a novel worst-case-aware training technique named A-TRICE that efficiently combines adversarial training and noise-injection training with right-censored Gaussian noise to improve the DNN accuracy in the worst-case scenarios. Our experimental results demonstrate that A-TRICE improves the worst-case accuracy under device variations by up to 33%.
Improving Realistic Worst-Case Performance of NVCiM DNN Accelerators through Training with Right-Censored Gaussian Noise
Jul 29, 2023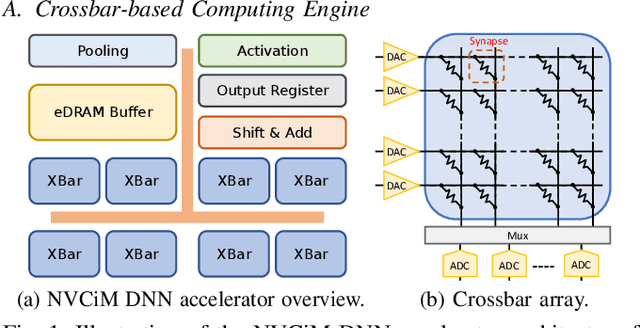
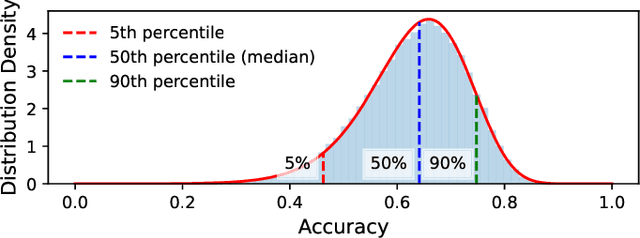
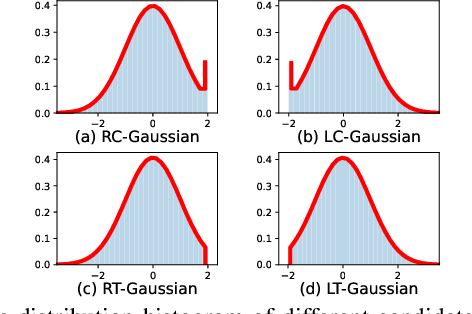
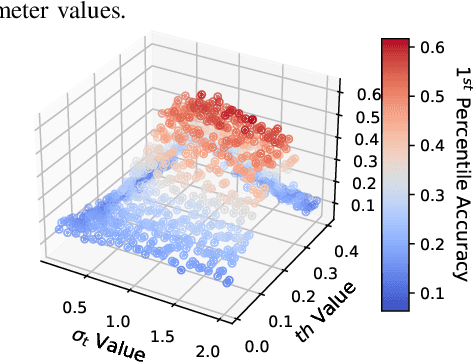
Compute-in-Memory (CiM), built upon non-volatile memory (NVM) devices, is promising for accelerating deep neural networks (DNNs) owing to its in-situ data processing capability and superior energy efficiency. Unfortunately, the well-trained model parameters, after being mapped to NVM devices, can often exhibit large deviations from their intended values due to device variations, resulting in notable performance degradation in these CiM-based DNN accelerators. There exists a long list of solutions to address this issue. However, they mainly focus on improving the mean performance of CiM DNN accelerators. How to guarantee the worst-case performance under the impact of device variations, which is crucial for many safety-critical applications such as self-driving cars, has been far less explored. In this work, we propose to use the k-th percentile performance (KPP) to capture the realistic worst-case performance of DNN models executing on CiM accelerators. Through a formal analysis of the properties of KPP and the noise injection-based DNN training, we demonstrate that injecting a novel right-censored Gaussian noise, as opposed to the conventional Gaussian noise, significantly improves the KPP of DNNs. We further propose an automated method to determine the optimal hyperparameters for injecting this right-censored Gaussian noise during the training process. Our method achieves up to a 26% improvement in KPP compared to the state-of-the-art methods employed to enhance DNN robustness under the impact of device variations.
On the Viability of using LLMs for SW/HW Co-Design: An Example in Designing CiM DNN Accelerators
Jun 12, 2023
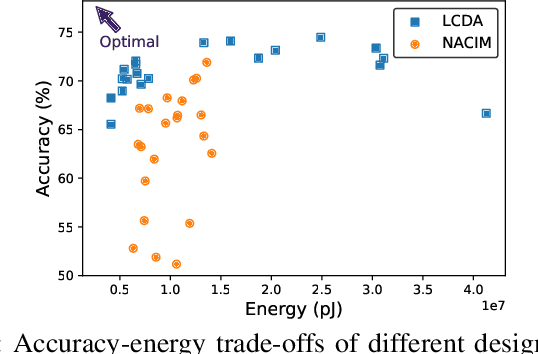


Deep Neural Networks (DNNs) have demonstrated impressive performance across a wide range of tasks. However, deploying DNNs on edge devices poses significant challenges due to stringent power and computational budgets. An effective solution to this issue is software-hardware (SW-HW) co-design, which allows for the tailored creation of DNN models and hardware architectures that optimally utilize available resources. However, SW-HW co-design traditionally suffers from slow optimization speeds because their optimizers do not make use of heuristic knowledge, also known as the ``cold start'' problem. In this study, we present a novel approach that leverages Large Language Models (LLMs) to address this issue. By utilizing the abundant knowledge of pre-trained LLMs in the co-design optimization process, we effectively bypass the cold start problem, substantially accelerating the design process. The proposed method achieves a significant speedup of 25x. This advancement paves the way for the rapid and efficient deployment of DNNs on edge devices.
Negative Feedback Training: A Novel Concept to Improve Robustness of NVCiM DNN Accelerators
May 23, 2023Compute-in-Memory (CiM) utilizing non-volatile memory (NVM) devices presents a highly promising and efficient approach for accelerating deep neural networks (DNNs). By concurrently storing network weights and performing matrix operations within the same crossbar structure, CiM accelerators offer DNN inference acceleration with minimal area requirements and exceptional energy efficiency. However, the stochasticity and intrinsic variations of NVM devices often lead to performance degradation, such as reduced classification accuracy, compared to expected outcomes. Although several methods have been proposed to mitigate device variation and enhance robustness, most of them rely on overall modulation and lack constraints on the training process. Drawing inspiration from the negative feedback mechanism, we introduce a novel training approach that uses a multi-exit mechanism as negative feedback to enhance the performance of DNN models in the presence of device variation. Our negative feedback training method surpasses state-of-the-art techniques by achieving an impressive improvement of up to 12.49% in addressing DNN robustness against device variation.
ApproxTrain: Fast Simulation of Approximate Multipliers for DNN Training and Inference
Sep 13, 2022

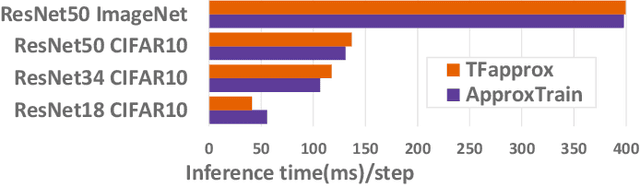
Edge training of Deep Neural Networks (DNNs) is a desirable goal for continuous learning; however, it is hindered by the enormous computational power required by training. Hardware approximate multipliers have shown their effectiveness for gaining resource-efficiency in DNN inference accelerators; however, training with approximate multipliers is largely unexplored. To build resource efficient accelerators with approximate multipliers supporting DNN training, a thorough evaluation of training convergence and accuracy for different DNN architectures and different approximate multipliers is needed. This paper presents ApproxTrain, an open-source framework that allows fast evaluation of DNN training and inference using simulated approximate multipliers. ApproxTrain is as user-friendly as TensorFlow (TF) and requires only a high-level description of a DNN architecture along with C/C++ functional models of the approximate multiplier. We improve the speed of the simulation at the multiplier level by using a novel LUT-based approximate floating-point (FP) multiplier simulator on GPU (AMSim). ApproxTrain leverages CUDA and efficiently integrates AMSim into the TensorFlow library, in order to overcome the absence of native hardware approximate multiplier in commercial GPUs. We use ApproxTrain to evaluate the convergence and accuracy of DNN training with approximate multipliers for small and large datasets (including ImageNet) using LeNets and ResNets architectures. The evaluations demonstrate similar convergence behavior and negligible change in test accuracy compared to FP32 and bfloat16 multipliers. Compared to CPU-based approximate multiplier simulations in training and inference, the GPU-accelerated ApproxTrain is more than 2500x faster. Based on highly optimized closed-source cuDNN/cuBLAS libraries with native hardware multipliers, the original TensorFlow is only 8x faster than ApproxTrain.
Computing-In-Memory Neural Network Accelerators for Safety-Critical Systems: Can Small Device Variations Be Disastrous?
Jul 15, 2022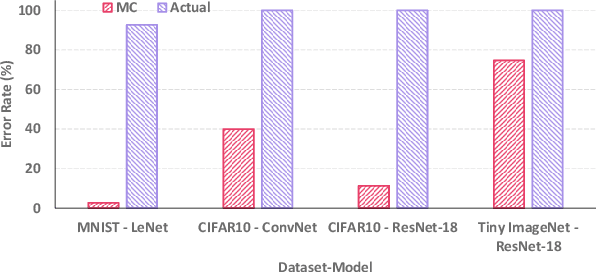
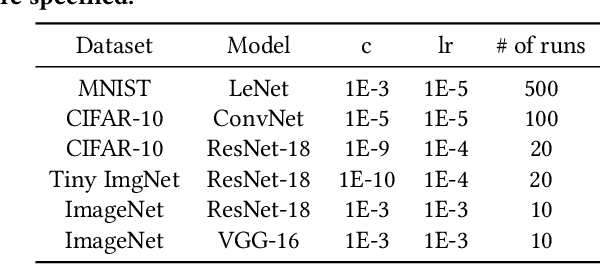

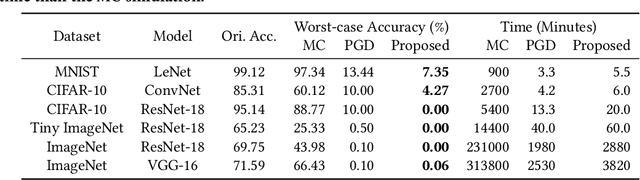
Computing-in-Memory (CiM) architectures based on emerging non-volatile memory (NVM) devices have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, NVM devices suffer from various non-idealities, especially device-to-device variations due to fabrication defects and cycle-to-cycle variations due to the stochastic behavior of devices. As such, the DNN weights actually mapped to NVM devices could deviate significantly from the expected values, leading to large performance degradation. To address this issue, most existing works focus on maximizing average performance under device variations. This objective would work well for general-purpose scenarios. But for safety-critical applications, the worst-case performance must also be considered. Unfortunately, this has been rarely explored in the literature. In this work, we formulate the problem of determining the worst-case performance of CiM DNN accelerators under the impact of device variations. We further propose a method to effectively find the specific combination of device variation in the high-dimensional space that leads to the worst-case performance. We find that even with very small device variations, the accuracy of a DNN can drop drastically, causing concerns when deploying CiM accelerators in safety-critical applications. Finally, we show that surprisingly none of the existing methods used to enhance average DNN performance in CiM accelerators are very effective when extended to enhance the worst-case performance, and further research down the road is needed to address this problem.
SWIM: Selective Write-Verify for Computing-in-Memory Neural Accelerators
Feb 17, 2022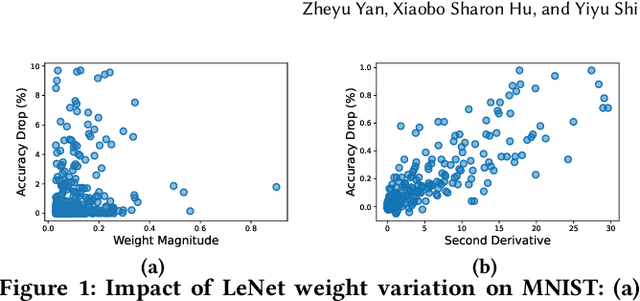

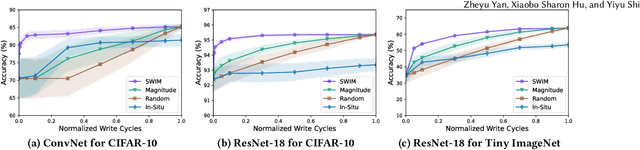
Computing-in-Memory architectures based on non-volatile emerging memories have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, these emerging devices can suffer from significant variations during the mapping process i.e., programming weights to the devices), and if left undealt with, can cause significant accuracy degradation. The non-ideality of weight mapping can be compensated by iterative programming with a write-verify scheme, i.e., reading the conductance and rewriting if necessary. In all existing works, such a practice is applied to every single weight of a DNN as it is being mapped, which requires extensive programming time. In this work, we show that it is only necessary to select a small portion of the weights for write-verify to maintain the DNN accuracy, thus achieving significant speedup. We further introduce a second derivative based technique SWIM, which only requires a single pass of forward and backpropagation, to efficiently select the weights that need write-verify. Experimental results on various DNN architectures for different datasets show that SWIM can achieve up to 10x programming speedup compared with conventional full-blown write-verify while attaining a comparable accuracy.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021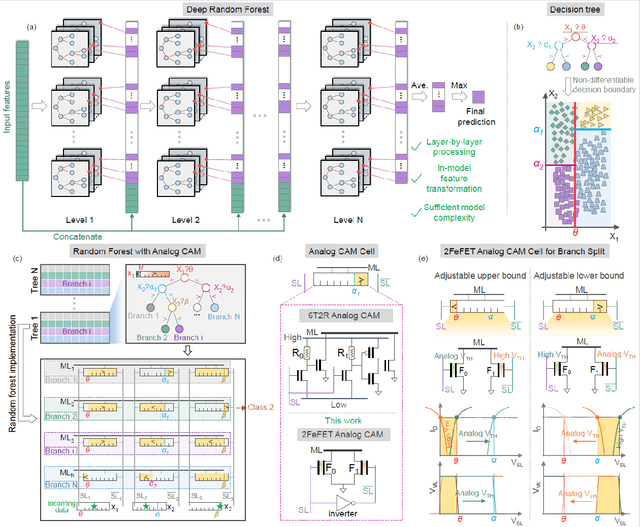
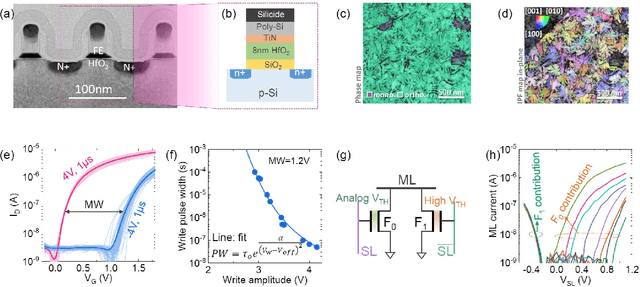
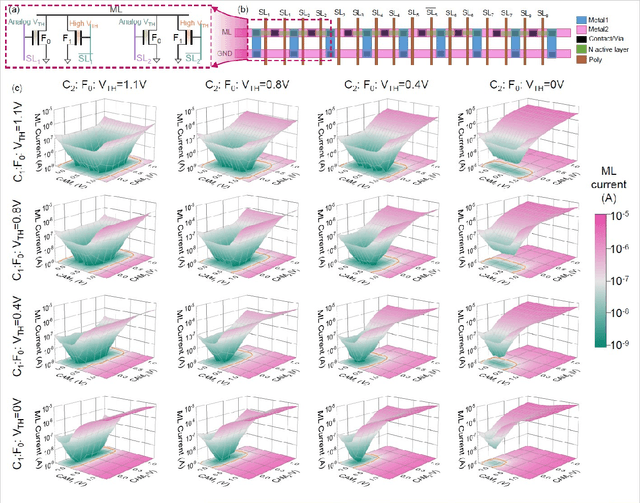
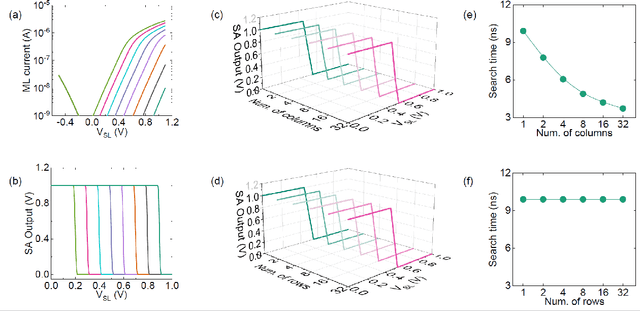
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
RADARS: Memory Efficient Reinforcement Learning Aided Differentiable Neural Architecture Search
Sep 13, 2021

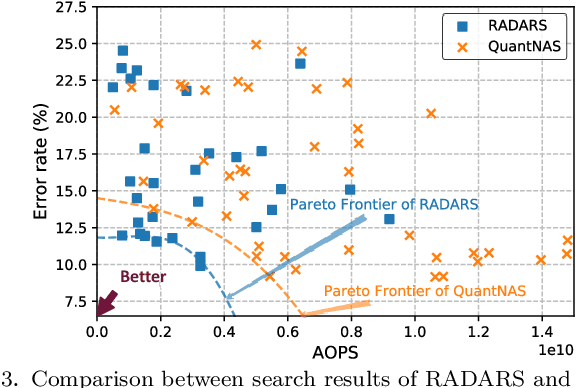
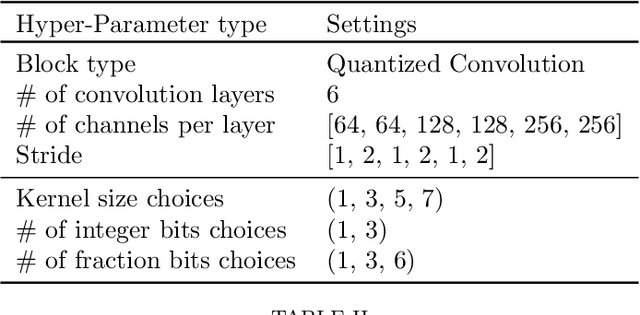
Differentiable neural architecture search (DNAS) is known for its capacity in the automatic generation of superior neural networks. However, DNAS based methods suffer from memory usage explosion when the search space expands, which may prevent them from running successfully on even advanced GPU platforms. On the other hand, reinforcement learning (RL) based methods, while being memory efficient, are extremely time-consuming. Combining the advantages of both types of methods, this paper presents RADARS, a scalable RL-aided DNAS framework that can explore large search spaces in a fast and memory-efficient manner. RADARS iteratively applies RL to prune undesired architecture candidates and identifies a promising subspace to carry out DNAS. Experiments using a workstation with 12 GB GPU memory show that on CIFAR-10 and ImageNet datasets, RADARS can achieve up to 3.41% higher accuracy with 2.5X search time reduction compared with a state-of-the-art RL-based method, while the two DNAS baselines cannot complete due to excessive memory usage or search time. To the best of the authors' knowledge, this is the first DNAS framework that can handle large search spaces with bounded memory usage.