 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024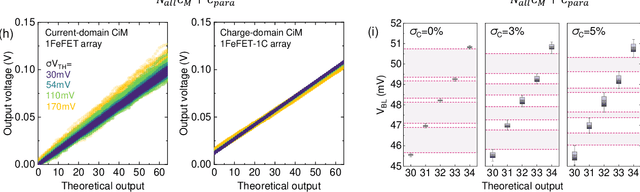
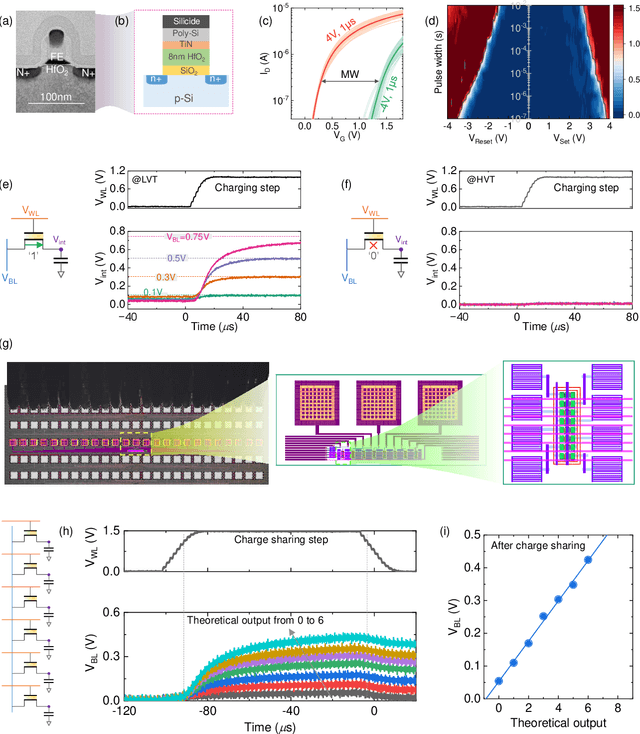
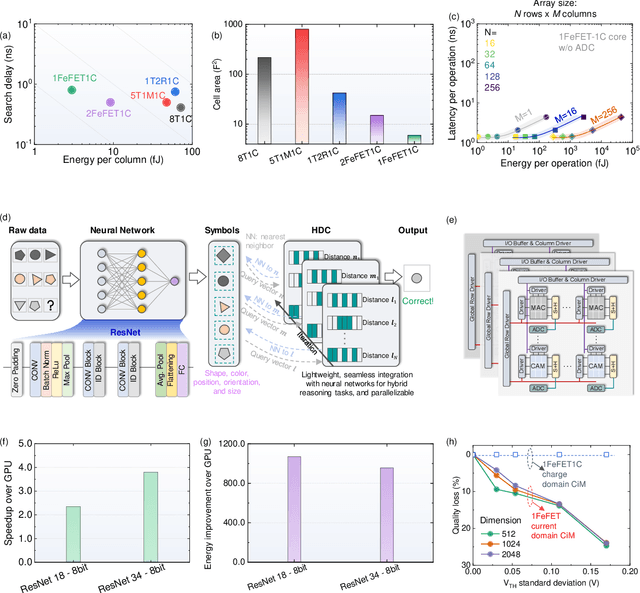
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
A Homogeneous Processing Fabric for Matrix-Vector Multiplication and Associative Search Using Ferroelectric Time-Domain Compute-in-Memory
Sep 24, 2022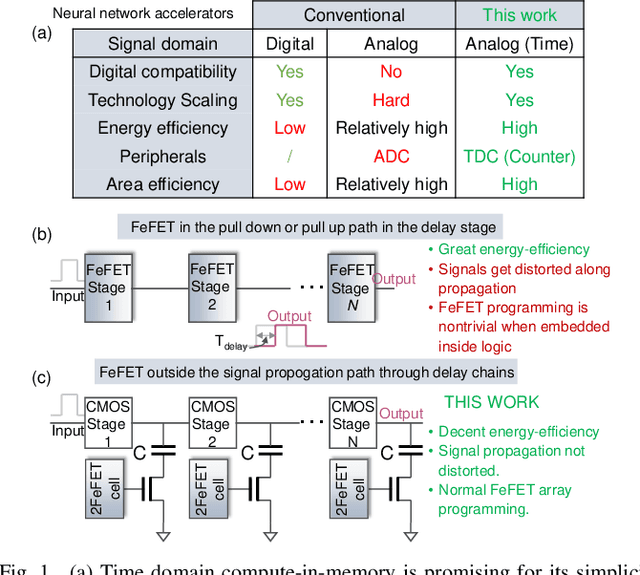
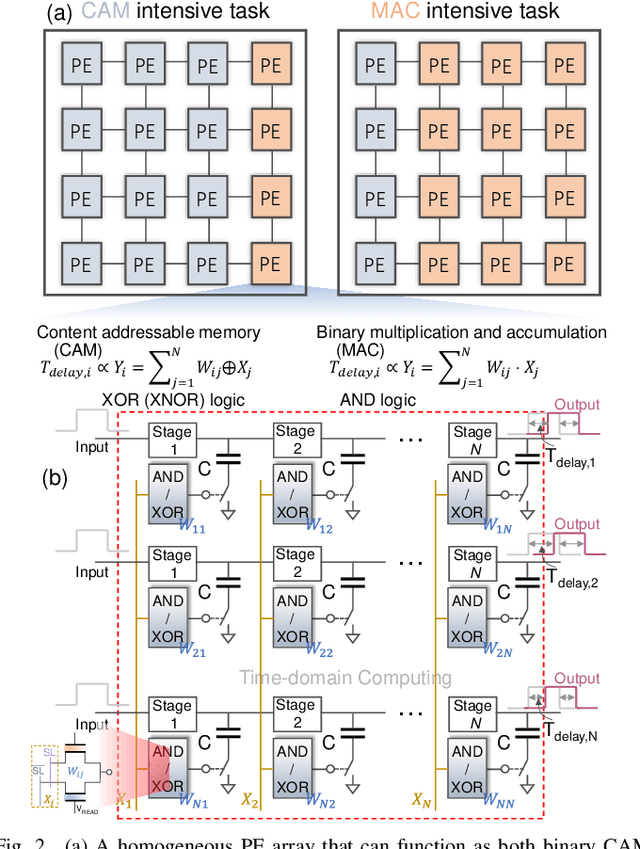
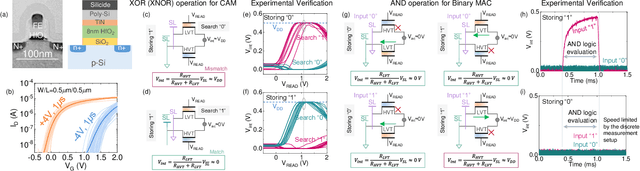
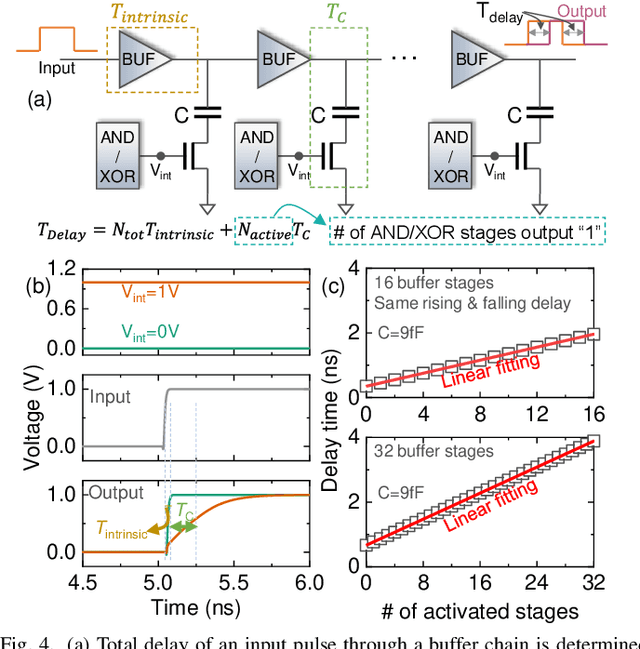
In this work, we propose a ferroelectric FET(FeFET) time-domain compute-in-memory (TD-CiM) array as a homogeneous processing fabric for binary multiplication-accumulation (MAC) and content addressable memory (CAM). We demonstrate that: i) the XOR(XNOR)/AND logic function can be realized using a single cell composed of 2FeFETs connected in series; ii) a two-phase computation in an inverter chain with each stage featuring the XOR/AND cell to control the associated capacitor loading and the computation results of binary MAC and CAM are reflected in the chain output signal delay, illustrating full digital compatibility; iii) comprehensive theoretical and experimental validation of the proposed 2FeFET cell and inverter delay chains and their robustness against FeFET variation; iv) the homogeneous processing fabric is applied in hyperdimensional computing to show dynamic and fine-grain resource allocation to accommodate different tasks requiring varying demands over the binary MAC and CAM resources.