 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging MARL to SARL: An Order-Independent Multi-Agent Transformer via Latent Consensus
Apr 15, 2026Cooperative multi-agent reinforcement learning (MARL) is widely used to address large joint observation and action spaces by decomposing a centralized control problem into multiple interacting agents. However, such decomposition often introduces additional challenges, including non-stationarity, unstable training, weak coordination, and limited theoretical guarantees. In this paper, we propose the Consensus Multi-Agent Transformer (CMAT), a centralized framework that bridges cooperative MARL to a hierarchical single-agent reinforcement learning (SARL) formulation. CMAT treats all agents as a unified entity and employs a Transformer encoder to process the large joint observation space. To handle the extensive joint action space, we introduce a hierarchical decision-making mechanism in which a Transformer decoder autoregressively generates a high-level consensus vector, simulating the process by which agents reach agreement on their strategies in latent space. Conditioned on this consensus, all agents generate their actions simultaneously, enabling order-independent joint decision making and avoiding the sensitivity to action-generation order in conventional Multi-Agent Transformers (MAT). This factorization allows the joint policy to be optimized using single-agent PPO while preserving expressive coordination through the latent consensus. To evaluate the proposed method, we conduct experiments on benchmark tasks from StarCraft II, Multi-Agent MuJoCo, and Google Research Football. The results show that CMAT achieves superior performance over recent centralized solutions, sequential MARL methods, and conventional MARL baselines. The code for this paper is available at:https://github.com/RS2002/CMAT .
Pushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
Jan 30, 2026Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.
AutoFed: Manual-Free Federated Traffic Prediction via Personalized Prompt
Dec 31, 2025Accurate traffic prediction is essential for Intelligent Transportation Systems, including ride-hailing, urban road planning, and vehicle fleet management. However, due to significant privacy concerns surrounding traffic data, most existing methods rely on local training, resulting in data silos and limited knowledge sharing. Federated Learning (FL) offers an efficient solution through privacy-preserving collaborative training; however, standard FL struggles with the non-independent and identically distributed (non-IID) problem among clients. This challenge has led to the emergence of Personalized Federated Learning (PFL) as a promising paradigm. Nevertheless, current PFL frameworks require further adaptation for traffic prediction tasks, such as specialized graph feature engineering, data processing, and network architecture design. A notable limitation of many prior studies is their reliance on hyper-parameter optimization across datasets-information that is often unavailable in real-world scenarios-thus impeding practical deployment. To address this challenge, we propose AutoFed, a novel PFL framework for traffic prediction that eliminates the need for manual hyper-parameter tuning. Inspired by prompt learning, AutoFed introduces a federated representor that employs a client-aligned adapter to distill local data into a compact, globally shared prompt matrix. This prompt then conditions a personalized predictor, allowing each client to benefit from cross-client knowledge while maintaining local specificity. Extensive experiments on real-world datasets demonstrate that AutoFed consistently achieves superior performance across diverse scenarios. The code of this paper is provided at https://github.com/RS2002/AutoFed .
Zero-Effort Image-to-Music Generation: An Interpretable RAG-based VLM Approach
Sep 26, 2025Recently, Image-to-Music (I2M) generation has garnered significant attention, with potential applications in fields such as gaming, advertising, and multi-modal art creation. However, due to the ambiguous and subjective nature of I2M tasks, most end-to-end methods lack interpretability, leaving users puzzled about the generation results. Even methods based on emotion mapping face controversy, as emotion represents only a singular aspect of art. Additionally, most learning-based methods require substantial computational resources and large datasets for training, hindering accessibility for common users. To address these challenges, we propose the first Vision Language Model (VLM)-based I2M framework that offers high interpretability and low computational cost. Specifically, we utilize ABC notation to bridge the text and music modalities, enabling the VLM to generate music using natural language. We then apply multi-modal Retrieval-Augmented Generation (RAG) and self-refinement techniques to allow the VLM to produce high-quality music without external training. Furthermore, we leverage the generated motivations in text and the attention maps from the VLM to provide explanations for the generated results in both text and image modalities. To validate our method, we conduct both human studies and machine evaluations, where our method outperforms others in terms of music quality and music-image consistency, indicating promising results. Our code is available at https://github.com/RS2002/Image2Music .
Each to Their Own: Exploring the Optimal Embedding in RAG
Jul 23, 2025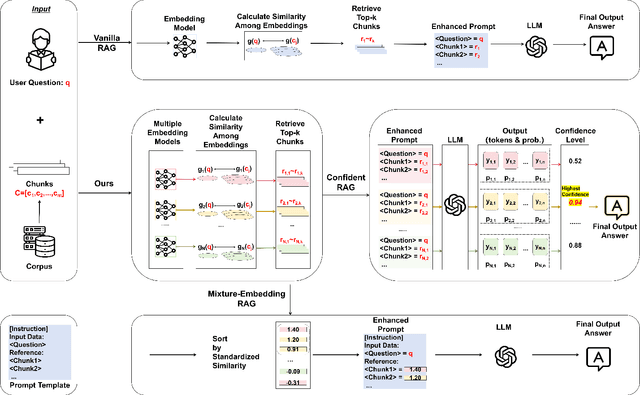
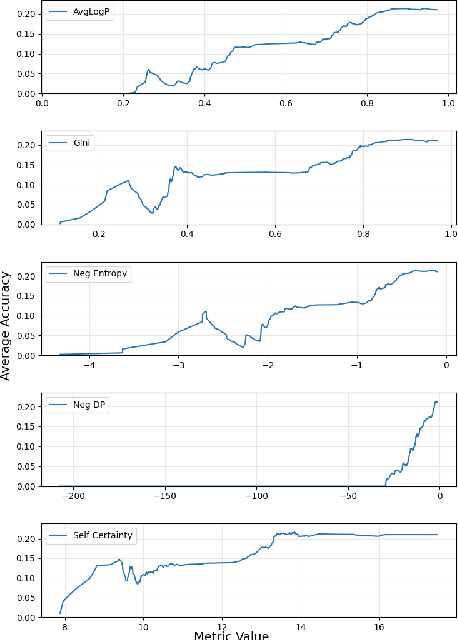
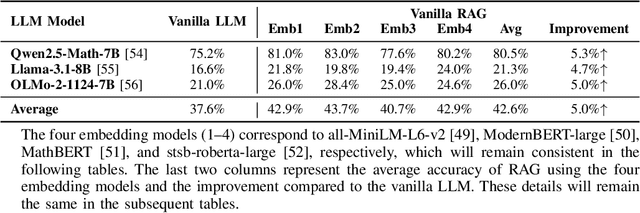
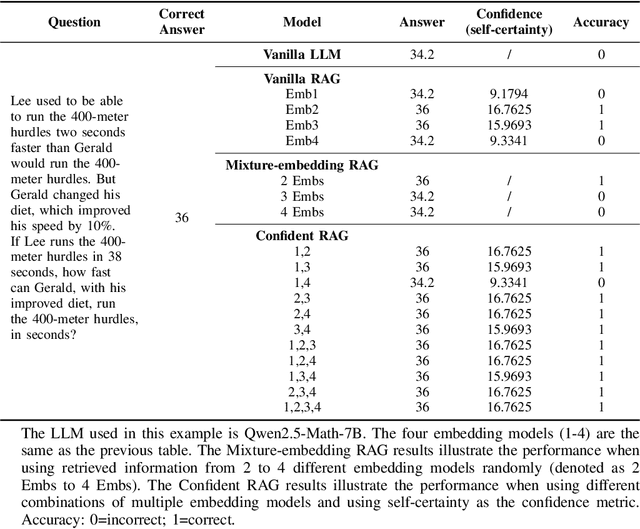
Recently, as Large Language Models (LLMs) have fundamentally impacted various fields, the methods for incorporating up-to-date information into LLMs or adding external knowledge to construct domain-specific models have garnered wide attention. Retrieval-Augmented Generation (RAG), serving as an inference-time scaling method, is notable for its low cost and minimal effort for parameter tuning. However, due to heterogeneous training data and model architecture, the variant embedding models used in RAG exhibit different benefits across various areas, often leading to different similarity calculation results and, consequently, varying response quality from LLMs. To address this problem, we propose and examine two approaches to enhance RAG by combining the benefits of multiple embedding models, named Mixture-Embedding RAG and Confident RAG. Mixture-Embedding RAG simply sorts and selects retrievals from multiple embedding models based on standardized similarity; however, it does not outperform vanilla RAG. In contrast, Confident RAG generates responses multiple times using different embedding models and then selects the responses with the highest confidence level, demonstrating average improvements of approximately 10% and 5% over vanilla LLMs and RAG, respectively. The consistent results across different LLMs and embedding models indicate that Confident RAG is an efficient plug-and-play approach for various domains. We will release our code upon publication.
A Short Overview of Multi-Modal Wi-Fi Sensing
May 10, 2025Wi-Fi sensing has emerged as a significant technology in wireless sensing and Integrated Sensing and Communication (ISAC), offering benefits such as low cost, high penetration, and enhanced privacy. Currently, it is widely utilized in various applications, including action recognition, human localization, and crowd counting. However, Wi-Fi sensing also faces challenges, such as low robustness and difficulties in data collection. Recently, there has been an increasing focus on multi-modal Wi-Fi sensing, where other modalities can act as teachers, providing ground truth or robust features for Wi-Fi sensing models to learn from, or can be directly fused with Wi-Fi for enhanced sensing capabilities. Although these methods have demonstrated promising results and substantial value in practical applications, there is a lack of comprehensive surveys reviewing them. To address this gap, this paper reviews the multi-modal Wi-Fi sensing literature \textbf{from the past 24 months} and highlights the current limitations, challenges and future directions in this field.
Label Unbalance in High-frequency Trading
Mar 13, 2025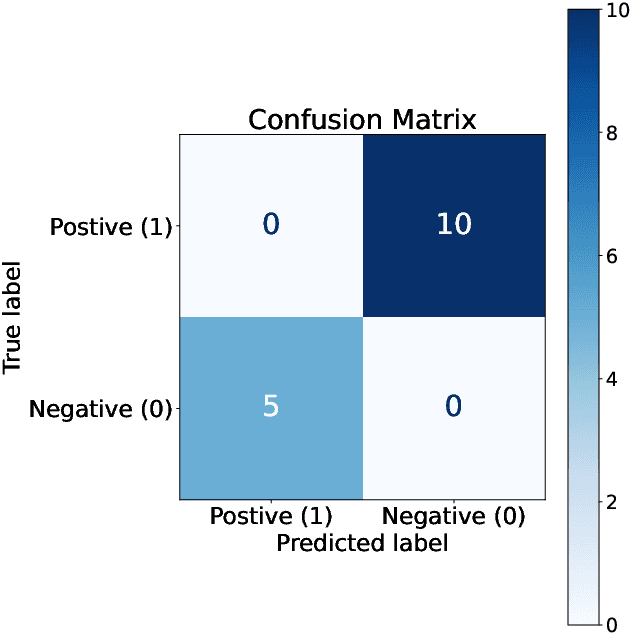
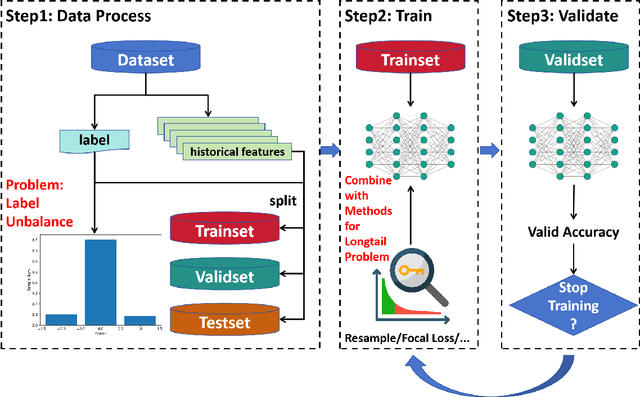
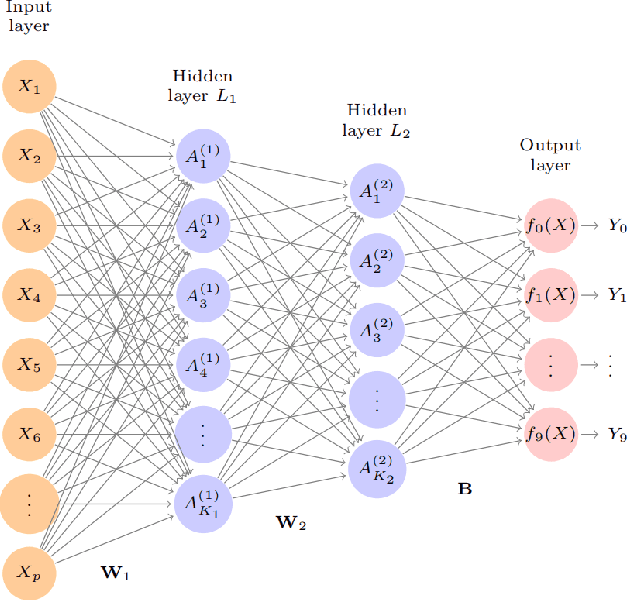
In financial trading, return prediction is one of the foundation for a successful trading system. By the fast development of the deep learning in various areas such as graphical processing, natural language, it has also demonstrate significant edge in handling with financial data. While the success of the deep learning relies on huge amount of labeled sample, labeling each time/event as profitable or unprofitable, under the transaction cost, especially in the high-frequency trading world, suffers from serious label imbalance issue.In this paper, we adopts rigurious end-to-end deep learning framework with comprehensive label imbalance adjustment methods and succeed in predicting in high-frequency return in the Chinese future market. The code for our method is publicly available at https://github.com/RS2002/Label-Unbalance-in-High-Frequency-Trading .
First Token Probability Guided RAG for Telecom Question Answering
Jan 11, 2025Large Language Models (LLMs) have garnered significant attention for their impressive general-purpose capabilities. For applications requiring intricate domain knowledge, Retrieval-Augmented Generation (RAG) has shown a distinct advantage in incorporating domain-specific information into LLMs. However, existing RAG research has not fully addressed the challenges of Multiple Choice Question Answering (MCQA) in telecommunications, particularly in terms of retrieval quality and mitigating hallucinations. To tackle these challenges, we propose a novel first token probability guided RAG framework. This framework leverages confidence scores to optimize key hyperparameters, such as chunk number and chunk window size, while dynamically adjusting the context. Our method starts by retrieving the most relevant chunks and generates a single token as the potential answer. The probabilities of all options are then normalized to serve as confidence scores, which guide the dynamic adjustment of the context. By iteratively optimizing the hyperparameters based on these confidence scores, we can continuously improve RAG performance. We conducted experiments to validate the effectiveness of our framework, demonstrating its potential to enhance accuracy in domain-specific MCQA tasks.
Mining Limited Data Sufficiently: A BERT-inspired Approach for CSI Time Series Application in Wireless Communication and Sensing
Dec 09, 2024



Channel State Information (CSI) is the cornerstone in both wireless communication and sensing systems. In wireless communication systems, CSI provides essential insights into channel conditions, enabling system optimizations like channel compensation and dynamic resource allocation. However, the high computational complexity of CSI estimation algorithms necessitates the development of fast deep learning methods for CSI prediction. In wireless sensing systems, CSI can be leveraged to infer environmental changes, facilitating various functions, including gesture recognition and people identification. Deep learning methods have demonstrated significant advantages over model-based approaches in these fine-grained CSI classification tasks, particularly when classes vary across different scenarios. However, a major challenge in training deep learning networks for wireless systems is the limited availability of data, further complicated by the diverse formats of many public datasets, which hinder integration. Additionally, collecting CSI data can be resource-intensive, requiring considerable time and manpower. To address these challenges, we propose CSI-BERT2 for CSI prediction and classification tasks, effectively utilizing limited data through a pre-training and fine-tuning approach. Building on CSI-BERT1, we enhance the model architecture by introducing an Adaptive Re-Weighting Layer (ARL) and a Multi-Layer Perceptron (MLP) to better capture sub-carrier and timestamp information, effectively addressing the permutation-invariance problem. Furthermore, we propose a Mask Prediction Model (MPM) fine-tuning method to improve the model's adaptability for CSI prediction tasks. Experimental results demonstrate that CSI-BERT2 achieves state-of-the-art performance across all tasks.
KNN-MMD: Cross Domain Wi-Fi Sensing Based on Local Distribution Alignment
Dec 06, 2024



As a key technology in Integrated Sensing and Communications (ISAC), Wi-Fi sensing has gained widespread application in various settings such as homes, offices, and public spaces. By analyzing the patterns of Channel State Information (CSI), we can obtain information about people's actions for tasks like person identification, gesture recognition, and fall detection. However, the CSI is heavily influenced by the environment, such that even minor environmental changes can significantly alter the CSI patterns. This will cause the performance deterioration and even failure when applying the Wi-Fi sensing model trained in one environment to another. To address this problem, we introduce a K-Nearest Neighbors Maximum Mean Discrepancy (KNN-MMD) model, a few-shot method for cross-domain Wi-Fi sensing. We propose a local distribution alignment method within each category, which outperforms traditional Domain Adaptation (DA) methods based on global alignment. Besides, our method can determine when to stop training, which cannot be realized by most DA methods. As a result, our method is more stable and can be better used in practice. The effectiveness of our method are evaluated in several cross-domain Wi-Fi sensing tasks, including gesture recognition, person identification, fall detection, and action recognition, using both a public dataset and a self-collected dataset. In one-shot scenario, our method achieves accuracy of 93.26%, 81.84%, 77.62%, and 75.30% in the four tasks respectively. To facilitate future research, we will make our code and dataset publicly available upon publication.