 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview of domain-specific foundation model: key technologies, applications and challenges
Sep 06, 2024The impressive performance of ChatGPT and other foundation-model-based products in human language understanding has prompted both academia and industry to explore how these models can be tailored for specific industries and application scenarios. This process, known as the customization of domain-specific foundation models, addresses the limitations of general-purpose models, which may not fully capture the unique patterns and requirements of domain-specific data. Despite its importance, there is a notable lack of comprehensive overview papers on building domain-specific foundation models, while numerous resources exist for general-purpose models. To bridge this gap, this article provides a timely and thorough overview of the methodology for customizing domain-specific foundation models. It introduces basic concepts, outlines the general architecture, and surveys key methods for constructing domain-specific models. Furthermore, the article discusses various domains that can benefit from these specialized models and highlights the challenges ahead. Through this overview, we aim to offer valuable guidance and reference for researchers and practitioners from diverse fields to develop their own customized foundation models.
Deep Mutual Learning across Task Towers for Effective Multi-Task Recommender Learning
Sep 19, 2023



Recommender systems usually leverage multi-task learning methods to simultaneously optimize several objectives because of the multi-faceted user behavior data. The typical way of conducting multi-task learning is to establish appropriate parameter sharing across multiple tasks at lower layers while reserving a separate task tower for each task at upper layers. Since the task towers exert direct impact on the prediction results, we argue that the architecture of standalone task towers is sub-optimal for promoting positive knowledge sharing. Accordingly, we propose the framework of Deep Mutual Learning across task towers, which is compatible with various backbone multi-task networks. Extensive offline experiments and online AB tests are conducted to evaluate and verify the proposed approach's effectiveness.
* 6 pages
Integrated Sensing and Communication Signals Towards 5G-A and 6G: A Survey
Jan 10, 2023



Integrated sensing and communication (ISAC) has the advantages of efficient spectrum utilization and low hardware cost. It is promising to be implemented in the fifth-generation-advanced (5G-A) and sixth-generation (6G) mobile communication systems, having the potential to be applied in intelligent applications requiring both communication and high-accurate sensing capabilities. As the fundamental technology of ISAC, ISAC signal directly impacts the performance of sensing and communication. This article systematically reviews the literature on ISAC signals from the perspective of mobile communication systems, including ISAC signal design, ISAC signal processing algorithms and ISAC signal optimization. We first review the ISAC signal design based on 5G, 5G-A and 6G mobile communication systems. Then, radar signal processing methods are reviewed for ISAC signals, mainly including the channel information matrix method, spectrum lines estimator method and super resolution method. In terms of signal optimization, we summarize peak-to-average power ratio (PAPR) optimization, interference management, and adaptive signal optimization for ISAC signals. This article may provide the guidelines for the research of ISAC signals in 5G-A and 6G mobile communication systems.
Rethinking the Performance of ISAC System: From Efficiency and Utility Perspectives
Aug 18, 2022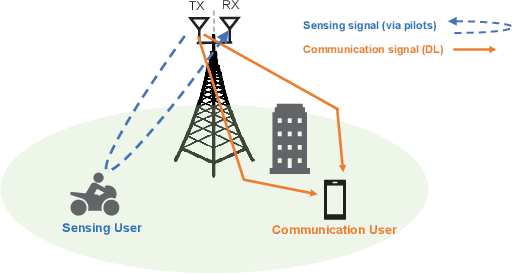
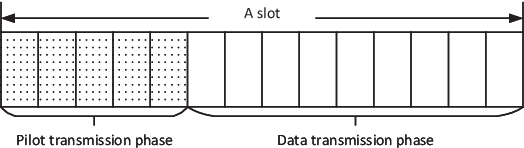
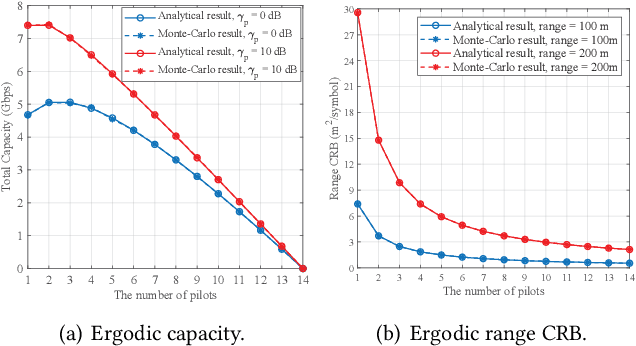
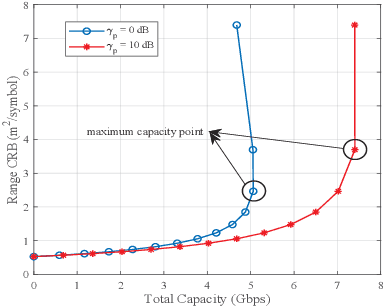
Integrated sensing and communications (ISAC) is an essential technology for the 6G communication system, which enables the conventional wireless communication network capable of sensing targets around. The shared use of pilots is a promising strategy to achieve ISAC. It brings a trade-off between communication and sensing, which is still unclear under the imperfect channel estimation condition. To provide some insights, the trade-off between ergodic capacity with imperfect channel estimation and ergodic Cramer-Rao bound (CRB) of range sensing is investigated. Firstly, the closedform expressions of ergodic capacity and ergodic range CRB are derived, which are associated with the number of pilots. Secondly, two novel metrics named efficiency and utility are firstly proposed to evaluate the joint performance of capacity and range sensing error. Specifically, efficiency is used to evaluate the achievable capacity per unit of the sensing error, and utility is designed to evaluate the utilization degree of ISAC. Moreover, an algorithm of pilot length optimization is designed to achieve the best efficiency. Finally, simulation results are given to verify the accuracy of analytical results, and provide some insights on designing the slot structure.
Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder
May 27, 2022



Embedding & MLP has become a paradigm for modern large-scale recommendation system. However, this paradigm suffers from the cold-start problem which will seriously compromise the ecological health of recommendation systems. This paper attempts to tackle the item cold-start problem by generating enhanced warmed-up ID embeddings for cold items with historical data and limited interaction records. From the aspect of industrial practice, we mainly focus on the following three points of item cold-start: 1) How to conduct cold-start without additional data requirements and make strategy easy to be deployed in online recommendation scenarios. 2) How to leverage both historical records and constantly emerging interaction data of new items. 3) How to model the relationship between item ID and side information stably from interaction data. To address these problems, we propose a model-agnostic Conditional Variational Autoencoder based Recommendation(CVAR) framework with some advantages including compatibility on various backbones, no extra requirements for data, utilization of both historical data and recent emerging interactions. CVAR uses latent variables to learn a distribution over item side information and generates desirable item ID embeddings using a conditional decoder. The proposed method is evaluated by extensive offline experiments on public datasets and online A/B tests on Tencent News recommendation platform, which further illustrate the advantages and robustness of CVAR.
Fast sensor placement by enlarging principle submatrix for large-scale linear inverse problems
Oct 07, 2021
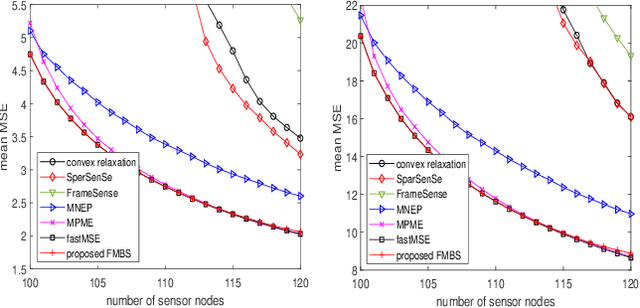
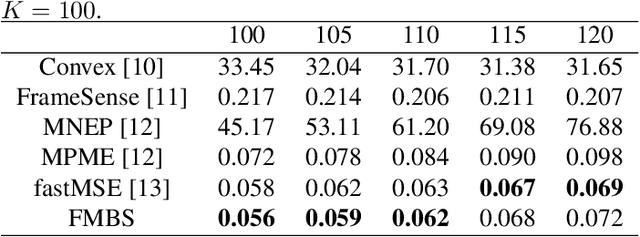
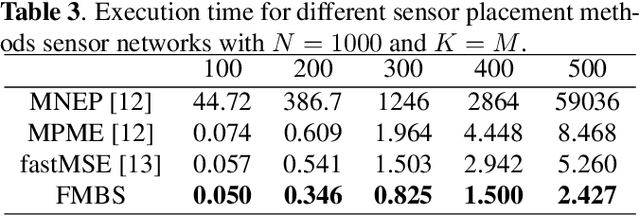
Sensor placement for linear inverse problems is the selection of locations to assign sensors so that the entire physical signal can be well recovered from partial observations. In this paper, we propose a fast sampling algorithm to place sensors. Specifically, assuming that the field signal $\mathbf{f}$ is represented by a linear model $\mathbf{f}=\pmb{\phi}\mathbf{g}$, it can be estimated from partial noisy samples via an unbiased least-squares (LS) method, whose expected mean square error (MSE) depends on chosen samples. First, we formulate an approximate MSE problem, and then prove it is equivalent to a problem related to a principle submatrix of $\pmb{\phi}\pmb{\phi}^\top$ indexed by sample set. To solve the formulated problem, we devise a fast greedy algorithm with simple matrix-vector multiplications, leveraging a matrix inverse formula. To further reduce complexity, we reuse results in the previous greedy step for warm start, so that candidates can be evaluated via lightweight vector-vector multiplications. Extensive experiments show that our proposed sensor placement method achieved the lowest sensor sampling time and the best performance compared to state-of-the-art schemes.
OCGNN: One-class Classification with Graph Neural Networks
Feb 22, 2020



Nowadays, graph-structured data are increasingly used to model complex systems. Meanwhile, detecting anomalies from graph has become a vital research problem of pressing societal concerns. Anomaly detection is an unsupervised learning task of identifying rare data that differ from the majority. As one of the dominant anomaly detection algorithms, One Class Support Vector Machine has been widely used to detect outliers. However, those traditional anomaly detection methods lost their effectiveness in graph data. Since traditional anomaly detection methods are stable, robust and easy to use, it is vitally important to generalize them to graph data. In this work, we propose One Class Graph Neural Network (OCGNN), a one-class classification framework for graph anomaly detection. OCGNN is designed to combine the powerful representation ability of Graph Neural Networks along with the classical one-class objective. Compared with other baselines, OCGNN achieves significant improvements in extensive experiments.
Self-adversarial Variational Autoencoder with Gaussian Anomaly Prior Distribution for Anomaly Detection
Mar 03, 2019



Recently, deep generative models have become increasingly popular in unsupervised anomaly detection. However, deep generative models aim at recovering the data distribution rather than detecting anomalies. Besides, deep generative models have the risk of overfitting training samples, which has disastrous effects on anomaly detection performance. To solve the above two problems, we propose a Self-adversarial Variational Autoencoder with a Gaussian anomaly prior assumption. We assume that both the anomalous and the normal prior distribution are Gaussian and have overlaps in the latent space. Therefore, a Gaussian transformer net T is trained to synthesize anomalous but near-normal latent variables. Keeping the original training objective of Variational Autoencoder, besides, the generator G tries to distinguish between the normal latent variables and the anomalous ones synthesized by T, and the encoder E is trained to discriminate whether the output of G is real. These new objectives we added not only give both G and E the ability to discriminate but also introduce additional regularization to prevent overfitting. Compared with the SOTA baselines, the proposed model achieves significant improvements in extensive experiments. Datasets and our model are available at a Github repository.