 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafactory: A Scalable Agent Factory for Trustworthy Autonomous Intelligence
May 07, 2026As large models evolve from conversational assistants into autonomous agents, challenges increasingly arise from long-horizon decision making, tool use, and real environment interaction. Existing agenticinfrastructure remain fragmented across evaluation, data management, and agent evolution, making it difficult to discover risks systematically and improve models in a continuous closed loop. In this report, we present \textbf{Safactory}, a scalable agent factory for trustworthy autonomous intelligence. Safactory integrates three tightly coupled platforms: a \textbf{Parallel Simulation Platform} for trajectory generation, a \textbf{Trustworthy Data Platform} for trajectory storage and experience extraction, and an \textbf{Autonomous Evolution Platform} for asynchronous reinforcement learning and on-policy distillation. As far as we know, Safactory is the first framework to propose a unified evolutionary pipeline for next-generation trustworthy autonomous intelligence.
DailyArt: Discovering Articulation from Single Static Images via Latent Dynamics
Apr 09, 2026Articulated objects are essential for embodied AI and world models, yet inferring their kinematics from a single closed-state image remains challenging because crucial motion cues are often occluded. Existing methods either require multi-state observations or rely on explicit part priors, retrieval, or other auxiliary inputs that partially expose the structure to be inferred. In this work, we present DailyArt, which formulates articulated joint estimation from a single static image as a synthesis-mediated reasoning problem. Instead of directly regressing joints from a heavily occluded observation, DailyArt first synthesizes a maximally articulated opened state under the same camera view to expose articulation cues, and then estimates the full set of joint parameters from the discrepancy between the observed and synthesized states. Using a set-prediction formulation, DailyArt recovers all joints simultaneously without requiring object-specific templates, multi-view inputs, or explicit part annotations at test time. Taking estimated joints as conditions, the framework further supports part-level novel state synthesis as a downstream capability. Extensive experiments show that DailyArt achieves strong performance in articulated joint estimation and supports part-level novel state synthesis conditioned on joints. Project page is available at https://rangooo123.github.io/DaliyArt.github.io/.
Towards Trustworthy Report Generation: A Deep Research Agent with Progressive Confidence Estimation and Calibration
Apr 07, 2026As agent-based systems continue to evolve, deep research agents are capable of automatically generating research-style reports across diverse domains. While these agents promise to streamline information synthesis and knowledge exploration, existing evaluation frameworks-typically based on subjective dimensions-fail to capture a critical aspect of report quality: trustworthiness. In open-ended research scenarios where ground-truth answers are unavailable, current evaluation methods cannot effectively measure the epistemic confidence of generated content, making calibration difficult and leaving users susceptible to misleading or hallucinated information. To address this limitation, we propose a novel deep research agent that incorporates progressive confidence estimation and calibration within the report generation pipeline. Our system leverages a deliberative search model, featuring deep retrieval and multi-hop reasoning to ground outputs in verifiable evidence while assigning confidence scores to individual claims. Combined with a carefully designed workflow, this approach produces trustworthy reports with enhanced transparency. Experimental results and case studies demonstrate that our method substantially improves interpretability and significantly increases user trust.
Decoupled Reasoning with Implicit Fact Tokens (DRIFT): A Dual-Model Framework for Efficient Long-Context Inference
Feb 10, 2026The integration of extensive, dynamic knowledge into Large Language Models (LLMs) remains a significant challenge due to the inherent entanglement of factual data and reasoning patterns. Existing solutions, ranging from non-parametric Retrieval-Augmented Generation (RAG) to parametric knowledge editing, are often constrained in practice by finite context windows, retriever noise, or the risk of catastrophic forgetting. In this paper, we propose DRIFT, a novel dual-model architecture designed to explicitly decouple knowledge extraction from the reasoning process. Unlike static prompt compression, DRIFT employs a lightweight knowledge model to dynamically compress document chunks into implicit fact tokens conditioned on the query. These dense representations are projected into the reasoning model's embedding space, replacing raw, redundant text while maintaining inference accuracy. Extensive experiments show that DRIFT significantly improves performance on long-context tasks, outperforming strong baselines among comparably sized models. Our approach provides a scalable and efficient paradigm for extending the effective context window and reasoning capabilities of LLMs. Our code is available at https://github.com/Lancelot-Xie/DRIFT.
Explore with Long-term Memory: A Benchmark and Multimodal LLM-based Reinforcement Learning Framework for Embodied Exploration
Jan 11, 2026An ideal embodied agent should possess lifelong learning capabilities to handle long-horizon and complex tasks, enabling continuous operation in general environments. This not only requires the agent to accurately accomplish given tasks but also to leverage long-term episodic memory to optimize decision-making. However, existing mainstream one-shot embodied tasks primarily focus on task completion results, neglecting the crucial process of exploration and memory utilization. To address this, we propose Long-term Memory Embodied Exploration (LMEE), which aims to unify the agent's exploratory cognition and decision-making behaviors to promote lifelong learning.We further construct a corresponding dataset and benchmark, LMEE-Bench, incorporating multi-goal navigation and memory-based question answering to comprehensively evaluate both the process and outcome of embodied exploration. To enhance the agent's memory recall and proactive exploration capabilities, we propose MemoryExplorer, a novel method that fine-tunes a multimodal large language model through reinforcement learning to encourage active memory querying. By incorporating a multi-task reward function that includes action prediction, frontier selection, and question answering, our model achieves proactive exploration. Extensive experiments against state-of-the-art embodied exploration models demonstrate that our approach achieves significant advantages in long-horizon embodied tasks.
FLEG: Feed-Forward Language Embedded Gaussian Splatting from Any Views
Dec 19, 2025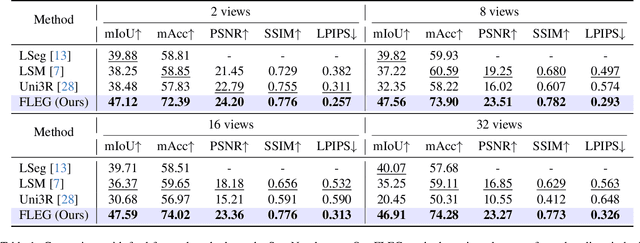
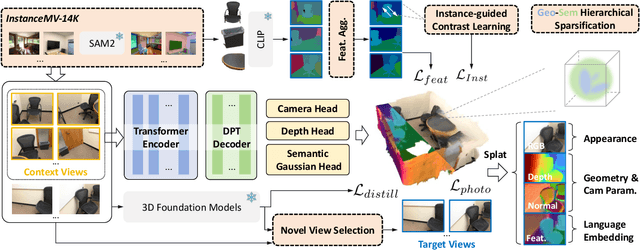
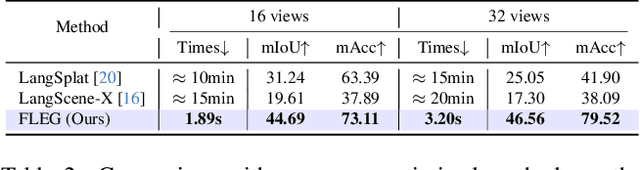

We present FLEG, a feed-forward network that reconstructs language-embedded 3D Gaussians from any views. Previous straightforward solutions combine feed-forward reconstruction with Gaussian heads but suffer from fixed input views and insufficient 3D training data. In contrast, we propose a 3D-annotation-free training framework for 2D-to-3D lifting from arbitrary uncalibrated and unposed multi-view images. Since the framework does not require 3D annotations, we can leverage large-scale video data with easily obtained 2D instance information to enrich semantic embedding. We also propose an instance-guided contrastive learning to align 2D semantics with the 3D representations. In addition, to mitigate the high memory and computational cost of dense views, we further propose a geometry-semantic hierarchical sparsification strategy. Our FLEG efficiently reconstructs language-embedded 3D Gaussian representation in a feed-forward manner from arbitrary sparse or dense views, jointly producing accurate geometry, high-fidelity appearance, and language-aligned semantics. Extensive experiments show that it outperforms existing methods on various related tasks. Project page: https://fangzhou2000.github.io/projects/fleg.
UniMark: Artificial Intelligence Generated Content Identification Toolkit
Dec 13, 2025The rapid proliferation of Artificial Intelligence Generated Content has precipitated a crisis of trust and urgent regulatory demands. However, existing identification tools suffer from fragmentation and a lack of support for visible compliance marking. To address these gaps, we introduce the \textbf{UniMark}, an open-source, unified framework for multimodal content governance. Our system features a modular unified engine that abstracts complexities across text, image, audio, and video modalities. Crucially, we propose a novel dual-operation strategy, natively supporting both \emph{Hidden Watermarking} for copyright protection and \emph{Visible Marking} for regulatory compliance. Furthermore, we establish a standardized evaluation framework with three specialized benchmarks (Image/Video/Audio-Bench) to ensure rigorous performance assessment. This toolkit bridges the gap between advanced algorithms and engineering implementation, fostering a more transparent and secure digital ecosystem.
Beyond Correctness: Confidence-Aware Reward Modeling for Enhancing Large Language Model Reasoning
Nov 09, 2025Recent advancements in large language models (LLMs) have shifted the post-training paradigm from traditional instruction tuning and human preference alignment toward reinforcement learning (RL) focused on reasoning capabilities. However, numerous technical reports indicate that purely rule-based reward RL frequently results in poor-quality reasoning chains or inconsistencies between reasoning processes and final answers, particularly when the base model is of smaller scale. During the RL exploration process, models might employ low-quality reasoning chains due to the lack of knowledge, occasionally producing correct answers randomly and receiving rewards based on established rule-based judges. This constrains the potential for resource-limited organizations to conduct direct reinforcement learning training on smaller-scale models. We propose a novel confidence-based reward model tailored for enhancing STEM reasoning capabilities. Unlike conventional approaches, our model penalizes not only incorrect answers but also low-confidence correct responses, thereby promoting more robust and logically consistent reasoning. We validate the effectiveness of our approach through static evaluations, Best-of-N inference tests, and PPO-based RL training. Our method outperforms several state-of-the-art open-source reward models across diverse STEM benchmarks. We release our codes and model in https://github.com/qianxiHe147/C2RM.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Deliberative Searcher: Improving LLM Reliability via Reinforcement Learning with constraints
Jul 23, 2025Improving the reliability of large language models (LLMs) is critical for deploying them in real-world scenarios. In this paper, we propose \textbf{Deliberative Searcher}, the first framework to integrate certainty calibration with retrieval-based search for open-domain question answering. The agent performs multi-step reflection and verification over Wikipedia data and is trained with a reinforcement learning algorithm that optimizes for accuracy under a soft reliability constraint. Empirical results show that proposed method improves alignment between model confidence and correctness, leading to more trustworthy outputs. This paper will be continuously updated.