 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTFormer: Re-parameter TSBN Spiking Transformer
Jun 20, 2024



The Spiking Neural Networks (SNNs), renowned for their bio-inspired operational mechanism and energy efficiency, mirror the human brain's neural activity. Yet, SNNs face challenges in balancing energy efficiency with the computational demands of advanced tasks. Our research introduces the RTFormer, a novel architecture that embeds Re-parameterized Temporal Sliding Batch Normalization (TSBN) within the Spiking Transformer framework. This innovation optimizes energy usage during inference while ensuring robust computational performance. The crux of RTFormer lies in its integration of reparameterized convolutions and TSBN, achieving an equilibrium between computational prowess and energy conservation.
CaLa: Complementary Association Learning for Augmenting Composed Image Retrieval
May 29, 2024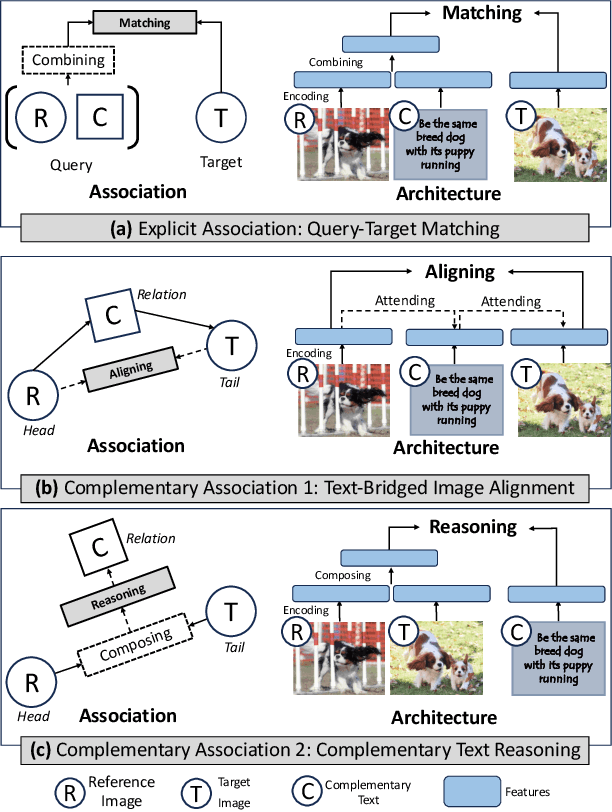
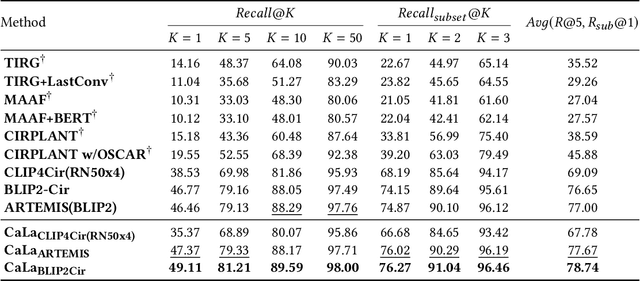
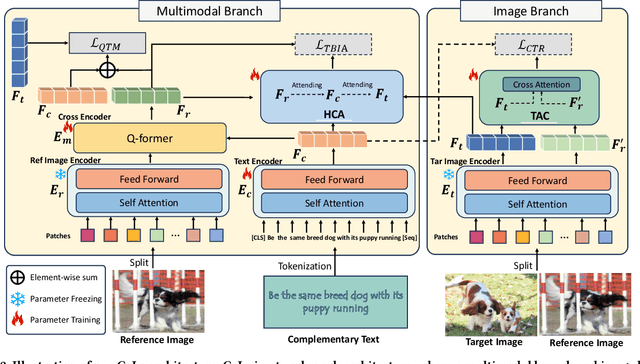
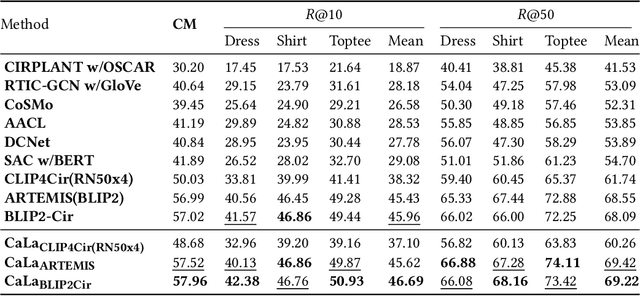
Composed Image Retrieval (CIR) involves searching for target images based on an image-text pair query. While current methods treat this as a query-target matching problem, we argue that CIR triplets contain additional associations beyond this primary relation. In our paper, we identify two new relations within triplets, treating each triplet as a graph node. Firstly, we introduce the concept of text-bridged image alignment, where the query text serves as a bridge between the query image and the target image. We propose a hinge-based cross-attention mechanism to incorporate this relation into network learning. Secondly, we explore complementary text reasoning, considering CIR as a form of cross-modal retrieval where two images compose to reason about complementary text. To integrate these perspectives effectively, we design a twin attention-based compositor. By combining these complementary associations with the explicit query pair-target image relation, we establish a comprehensive set of constraints for CIR. Our framework, CaLa (Complementary Association Learning for Augmenting Composed Image Retrieval), leverages these insights. We evaluate CaLa on CIRR and FashionIQ benchmarks with multiple backbones, demonstrating its superiority in composed image retrieval.
Speech-driven Personalized Gesture Synthetics: Harnessing Automatic Fuzzy Feature Inference
Mar 16, 2024
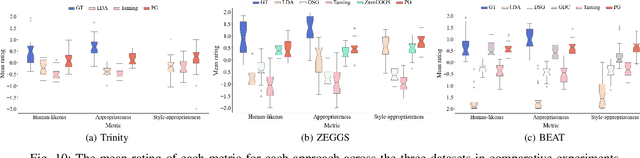
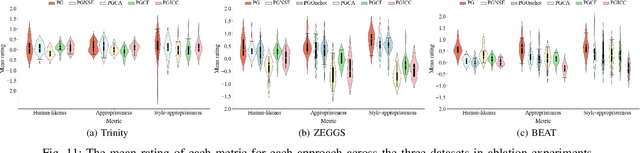
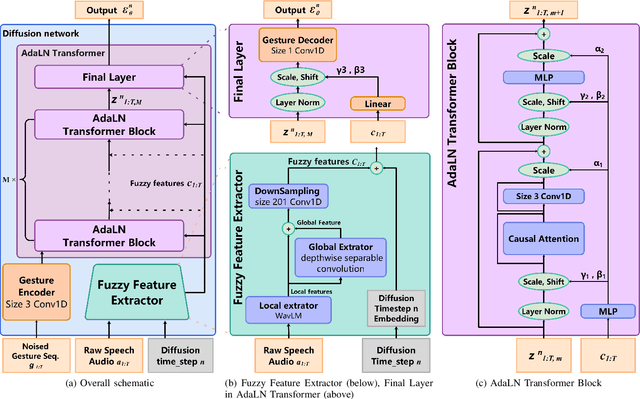
Speech-driven gesture generation is an emerging field within virtual human creation. However, a significant challenge lies in accurately determining and processing the multitude of input features (such as acoustic, semantic, emotional, personality, and even subtle unknown features). Traditional approaches, reliant on various explicit feature inputs and complex multimodal processing, constrain the expressiveness of resulting gestures and limit their applicability. To address these challenges, we present Persona-Gestor, a novel end-to-end generative model designed to generate highly personalized 3D full-body gestures solely relying on raw speech audio. The model combines a fuzzy feature extractor and a non-autoregressive Adaptive Layer Normalization (AdaLN) transformer diffusion architecture. The fuzzy feature extractor harnesses a fuzzy inference strategy that automatically infers implicit, continuous fuzzy features. These fuzzy features, represented as a unified latent feature, are fed into the AdaLN transformer. The AdaLN transformer introduces a conditional mechanism that applies a uniform function across all tokens, thereby effectively modeling the correlation between the fuzzy features and the gesture sequence. This module ensures a high level of gesture-speech synchronization while preserving naturalness. Finally, we employ the diffusion model to train and infer various gestures. Extensive subjective and objective evaluations on the Trinity, ZEGGS, and BEAT datasets confirm our model's superior performance to the current state-of-the-art approaches. Persona-Gestor improves the system's usability and generalization capabilities, setting a new benchmark in speech-driven gesture synthesis and broadening the horizon for virtual human technology. Supplementary videos and code can be accessed at https://zf223669.github.io/Diffmotion-v2-website/
Towards Geometric-Photometric Joint Alignment for Facial Mesh Registration
Mar 05, 2024



This paper presents a Geometric-Photometric Joint Alignment(GPJA) method, for accurately aligning human expressions by combining geometry and photometric information. Common practices for registering human heads typically involve aligning landmarks with facial template meshes using geometry processing approaches, but often overlook photometric consistency. GPJA overcomes this limitation by leveraging differentiable rendering to align vertices with target expressions, achieving joint alignment in geometry and photometric appearances automatically, without the need for semantic annotation or aligned meshes for training. It features a holistic rendering alignment strategy and a multiscale regularized optimization for robust and fast convergence. The method utilizes derivatives at vertex positions for supervision and employs a gradient-based algorithm which guarantees smoothness and avoids topological defects during the geometry evolution. Experimental results demonstrate faithful alignment under various expressions, surpassing the conventional ICP-based methods and the state-of-the-art deep learning based method. In practical, our method enhances the efficiency of obtaining topology-consistent face models from multi-view stereo facial scanning.
Optimal Noise pursuit for Augmenting Text-to-Video Generation
Nov 02, 2023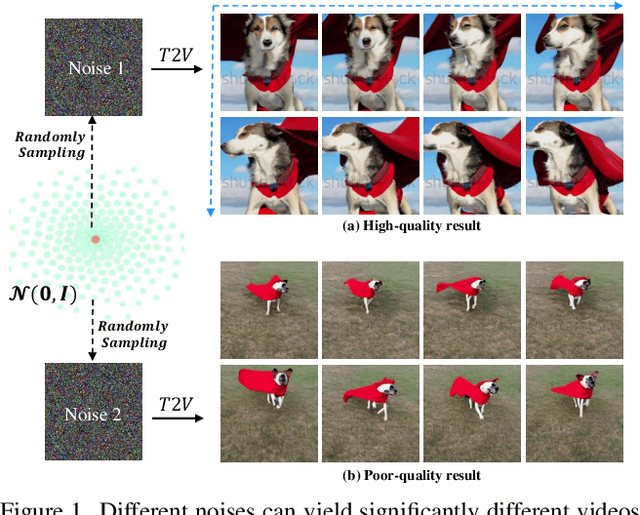



Despite the remarkable progress in text-to-video generation, existing diffusion-based models often exhibit instability in terms of noise during inference. Specifically, when different noises are fed for the given text, these models produce videos that differ significantly in terms of both frame quality and temporal consistency. With this observation, we posit that there exists an optimal noise matched to each textual input; however, the widely adopted strategies of random noise sampling often fail to capture it. In this paper, we argue that the optimal noise can be approached through inverting the groundtruth video using the established noise-video mapping derived from the diffusion model. Nevertheless, the groundtruth video for the text prompt is not available during inference. To address this challenge, we propose to approximate the optimal noise via a search and inversion pipeline. Given a text prompt, we initially search for a video from a predefined candidate pool that closely relates to the text prompt. Subsequently, we invert the searched video into the noise space, which serves as an improved noise prompt for the textual input. In addition to addressing noise, we also observe that the text prompt with richer details often leads to higher-quality videos. Motivated by this, we further design a semantic-preserving rewriter to enrich the text prompt, where a reference-guided rewriting is devised for reasonable details compensation, and a denoising with a hybrid semantics strategy is proposed to preserve the semantic consistency. Extensive experiments on the WebVid-10M benchmark show that our proposed method can improve the text-to-video models with a clear margin, while introducing no optimization burden.
APAN: Asynchronous Propagation Attention Network for Real-time Temporal Graph Embedding
Dec 16, 2020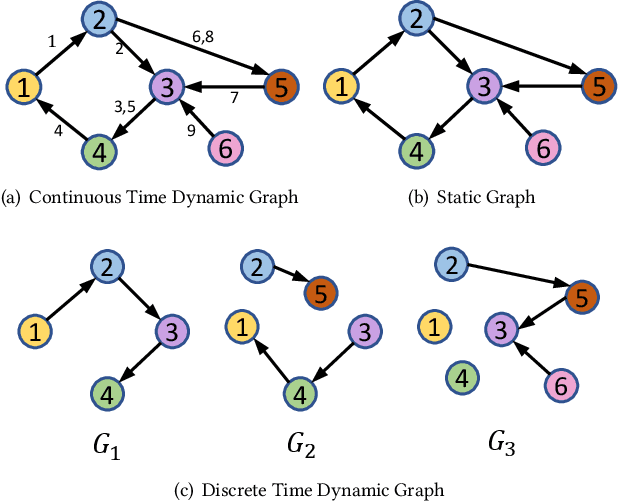
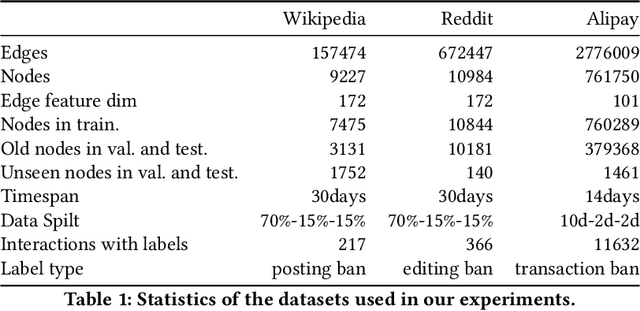
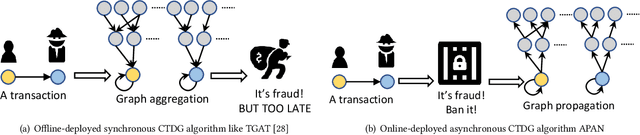
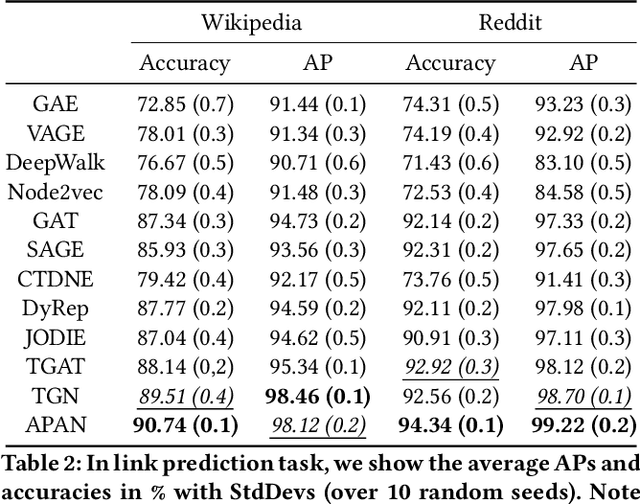
Limited by the time complexity of querying k-hop neighbors in a graph database, most graph algorithms cannot be deployed online and execute millisecond-level inference. This problem dramatically limits the potential of applying graph algorithms in certain areas, such as financial fraud detection. Therefore, we propose Asynchronous Propagation Attention Network, an asynchronous continuous time dynamic graph algorithm for real-time temporal graph embedding. Traditional graph models usually execute two serial operations: first graph computation and then model inference. We decouple model inference and graph computation step so that the heavy graph query operations will not damage the speed of model inference. Extensive experiments demonstrate that the proposed method can achieve competitive performance and 8.7 times inference speed improvement in the meantime.