 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiDx: A Multi-Source Knowledge Integration Framework towards Diagnostic Reasoning
Apr 27, 2026Diagnostic prediction and clinical reasoning are critical tasks in healthcare applications. While Large Language Models (LLMs) have shown strong capabilities in commonsense reasoning, they still struggle with diagnostic reasoning due to limited domain knowledge. Existing approaches often rely on internal model knowledge or static knowledge bases, resulting in knowledge insufficiency and limited adaptability, which hinder their capacity to perform diagnostic reasoning. Moreover, these methods focus solely on the accuracy of final predictions, overlooking alignment with standard clinical reasoning trajectories. To this end, we propose MultiDx, a two-stage diagnostic reasoning framework that performs differential diagnosis by analyzing evidence collected from multiple knowledge sources. Specifically, it first generates suspected diagnoses and reasoning paths by leveraging knowledge from web search, SOAP-formatted case, and clinical case database. Then it integrates multi-perspective evidence through matching, voting, and differential diagnosis to generate the final prediction.~Extensive experiments on two public benchmarks demonstrate the effectiveness of our approach.
AdapTime: Enabling Adaptive Temporal Reasoning in Large Language Models
Apr 27, 2026Large language models have demonstrated strong reasoning capabilities in general knowledge question answering. However, their ability to handle temporal information remains limited. To address this limitation, existing approaches often involve external tools or manual verification and are tailored to specific scenarios, leading to poor generalizability. Moreover, these methods apply a fixed pipeline to all questions, overlooking the fact that different types of temporal questions require distinct reasoning strategies, which leads to unnecessary processing for simple cases and inadequate reasoning for complex ones. To this end, we propose AdapTime, an adaptive temporal reasoning method that dynamically executes reasoning steps based on the input context. Specifically, it involves three temporal reasoning actions: reformulate, rewrite and review, with an LLM planner guiding the reasoning process. AdapTime integrates seamlessly with state-of-the-art LLMs and significantly enhances their temporal reasoning capabilities without relying on external support. Extensive experiments demonstrate the effectiveness of our approach.
Enhancing Conversational Agents via Task-Oriented Adversarial Memory Adaptation
Jan 29, 2026Conversational agents struggle to handle long conversations due to context window limitations. Therefore, memory systems are developed to leverage essential historical information. Existing memory systems typically follow a pipeline of offline memory construction and update, and online retrieval. Despite the flexible online phase, the offline phase remains fixed and task-independent. In this phase, memory construction operates under a predefined workflow and fails to emphasize task relevant information. Meanwhile, memory updates are guided by generic metrics rather than task specific supervision. This leads to a misalignment between offline memory preparation and task requirements, which undermines downstream task performance. To this end, we propose an Adversarial Memory Adaptation mechanism (AMA) that aligns memory construction and update with task objectives by simulating task execution. Specifically, first, a challenger agent generates question answer pairs based on the original dialogues. The constructed memory is then used to answer these questions, simulating downstream inference. Subsequently, an evaluator agent assesses the responses and performs error analysis. Finally, an adapter agent analyzes the error cases and performs dual level updates on both the construction strategy and the content. Through this process, the memory system receives task aware supervision signals in advance during the offline phase, enhancing its adaptability to downstream tasks. AMA can be integrated into various existing memory systems, and extensive experiments on long dialogue benchmark LoCoMo demonstrate its effectiveness.
Exploring Spectral Characteristics for Single Image Reflection Removal
Sep 16, 2025



Eliminating reflections caused by incident light interacting with reflective medium remains an ill-posed problem in the image restoration area. The primary challenge arises from the overlapping of reflection and transmission components in the captured images, which complicates the task of accurately distinguishing and recovering the clean background. Existing approaches typically address reflection removal solely in the image domain, ignoring the spectral property variations of reflected light, which hinders their ability to effectively discern reflections. In this paper, we start with a new perspective on spectral learning, and propose the Spectral Codebook to reconstruct the optical spectrum of the reflection image. The reflections can be effectively distinguished by perceiving the wavelength differences between different light sources in the spectrum. To leverage the reconstructed spectrum, we design two spectral prior refinement modules to re-distribute pixels in the spatial dimension and adaptively enhance the spectral differences along the wavelength dimension. Furthermore, we present the Spectrum-Aware Transformer to jointly recover the transmitted content in spectral and pixel domains. Experimental results on three different reflection benchmarks demonstrate the superiority and generalization ability of our method compared to state-of-the-art models.
A Model-agnostic Strategy to Mitigate Embedding Degradation in Personalized Federated Recommendation
Aug 27, 2025Centralized recommender systems encounter privacy leakage due to the need to collect user behavior and other private data. Hence, federated recommender systems (FedRec) have become a promising approach with an aggregated global model on the server. However, this distributed training paradigm suffers from embedding degradation caused by suboptimal personalization and dimensional collapse, due to the existence of sparse interactions and heterogeneous preferences. To this end, we propose a novel model-agnostic strategy for FedRec to strengthen the personalized embedding utility, which is called Personalized Local-Global Collaboration (PLGC). It is the first research in federated recommendation to alleviate the dimensional collapse issue. Particularly, we incorporate the frozen global item embedding table into local devices. Based on a Neural Tangent Kernel strategy that dynamically balances local and global information, PLGC optimizes personalized representations during forward inference, ultimately converging to user-specific preferences. Additionally, PLGC carries on a contrastive objective function to reduce embedding redundancy by dissolving dependencies between dimensions, thereby improving the backward representation learning process. We introduce PLGC as a model-agnostic personalized training strategy for federated recommendations that can be applied to existing baselines to alleviate embedding degradation. Extensive experiments on five real-world datasets have demonstrated the effectiveness and adaptability of PLGC, which outperforms various baseline algorithms.
A Scenario-Oriented Survey of Federated Recommender Systems: Techniques, Challenges, and Future Directions
Aug 27, 2025Extending recommender systems to federated learning (FL) frameworks to protect the privacy of users or platforms while making recommendations has recently gained widespread attention in academia. This is due to the natural coupling of recommender systems and federated learning architectures: the data originates from distributed clients (mostly mobile devices held by users), which are highly related to privacy. In a centralized recommender system (CenRec), the central server collects clients' data, trains the model, and provides the service. Whereas in federated recommender systems (FedRec), the step of data collecting is omitted, and the step of model training is offloaded to each client. The server only aggregates the model and other knowledge, thus avoiding client privacy leakage. Some surveys of federated recommender systems discuss and analyze related work from the perspective of designing FL systems. However, their utility drops by ignoring specific recommendation scenarios' unique characteristics and practical challenges. For example, the statistical heterogeneity issue in cross-domain FedRec originates from the label drift of the data held by different platforms, which is mainly caused by the recommender itself, but not the federated architecture. Therefore, it should focus more on solving specific problems in real-world recommendation scenarios to encourage the deployment FedRec. To this end, this review comprehensively analyzes the coupling of recommender systems and federated learning from the perspective of recommendation researchers and practitioners. We establish a clear link between recommendation scenarios and FL frameworks, systematically analyzing scenario-specific approaches, practical challenges, and potential opportunities. We aim to develop guidance for the real-world deployment of FedRec, bridging the gap between existing research and applications.
Learning Deblurring Texture Prior from Unpaired Data with Diffusion Model
Jul 18, 2025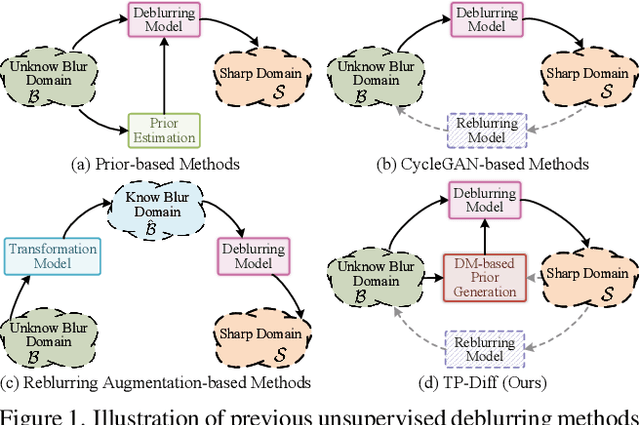
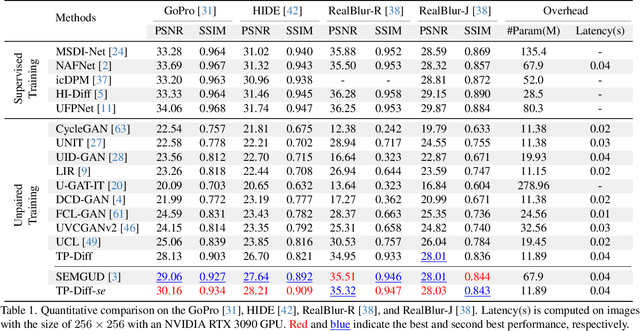
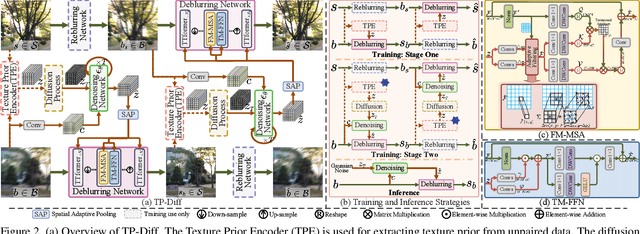
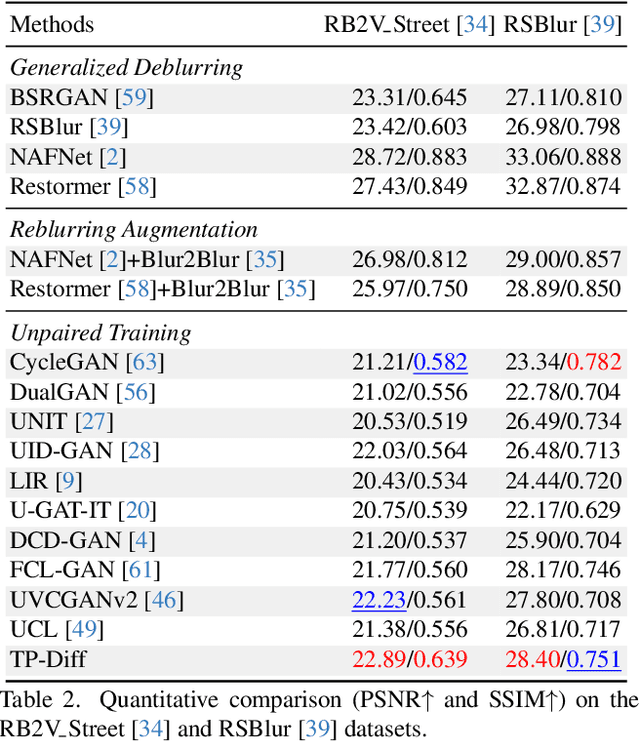
Since acquiring large amounts of realistic blurry-sharp image pairs is difficult and expensive, learning blind image deblurring from unpaired data is a more practical and promising solution. Unfortunately, dominant approaches rely heavily on adversarial learning to bridge the gap from blurry domains to sharp domains, ignoring the complex and unpredictable nature of real-world blur patterns. In this paper, we propose a novel diffusion model (DM)-based framework, dubbed \ours, for image deblurring by learning spatially varying texture prior from unpaired data. In particular, \ours performs DM to generate the prior knowledge that aids in recovering the textures of blurry images. To implement this, we propose a Texture Prior Encoder (TPE) that introduces a memory mechanism to represent the image textures and provides supervision for DM training. To fully exploit the generated texture priors, we present the Texture Transfer Transformer layer (TTformer), in which a novel Filter-Modulated Multi-head Self-Attention (FM-MSA) efficiently removes spatially varying blurring through adaptive filtering. Furthermore, we implement a wavelet-based adversarial loss to preserve high-frequency texture details. Extensive evaluations show that \ours provides a promising unsupervised deblurring solution and outperforms SOTA methods in widely-used benchmarks.
Frequency Domain-Based Diffusion Model for Unpaired Image Dehazing
Jul 02, 2025Unpaired image dehazing has attracted increasing attention due to its flexible data requirements during model training. Dominant methods based on contrastive learning not only introduce haze-unrelated content information, but also ignore haze-specific properties in the frequency domain (\ie,~haze-related degradation is mainly manifested in the amplitude spectrum). To address these issues, we propose a novel frequency domain-based diffusion model, named \ours, for fully exploiting the beneficial knowledge in unpaired clear data. In particular, inspired by the strong generative ability shown by Diffusion Models (DMs), we tackle the dehazing task from the perspective of frequency domain reconstruction and perform the DMs to yield the amplitude spectrum consistent with the distribution of clear images. To implement it, we propose an Amplitude Residual Encoder (ARE) to extract the amplitude residuals, which effectively compensates for the amplitude gap from the hazy to clear domains, as well as provide supervision for the DMs training. In addition, we propose a Phase Correction Module (PCM) to eliminate artifacts by further refining the phase spectrum during dehazing with a simple attention mechanism. Experimental results demonstrate that our \ours outperforms other state-of-the-art methods on both synthetic and real-world datasets.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
TSAL: Few-shot Text Segmentation Based on Attribute Learning
Apr 15, 2025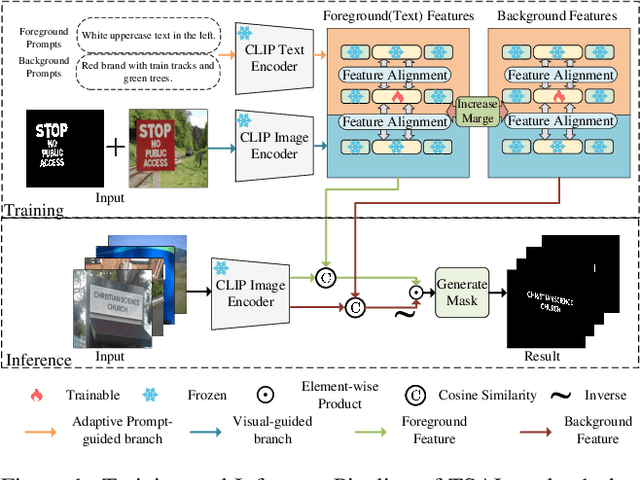
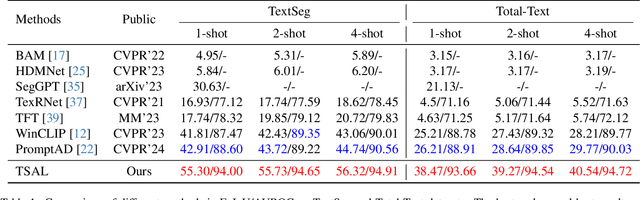
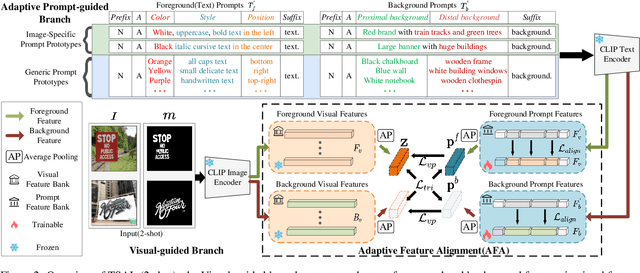
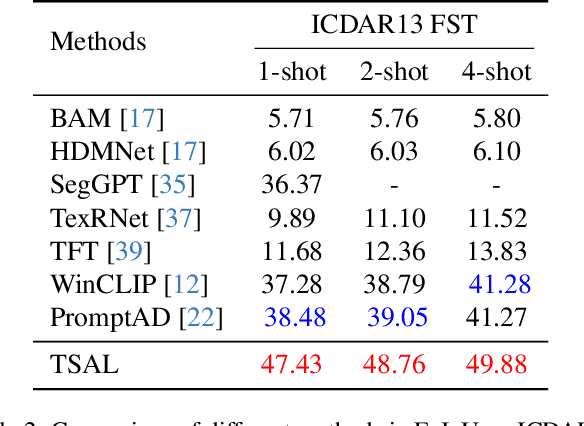
Recently supervised learning rapidly develops in scene text segmentation. However, the lack of high-quality datasets and the high cost of pixel annotation greatly limit the development of them. Considering the well-performed few-shot learning methods for downstream tasks, we investigate the application of the few-shot learning method to scene text segmentation. We propose TSAL, which leverages CLIP's prior knowledge to learn text attributes for segmentation. To fully utilize the semantic and texture information in the image, a visual-guided branch is proposed to separately extract text and background features. To reduce data dependency and improve text detection accuracy, the adaptive prompt-guided branch employs effective adaptive prompt templates to capture various text attributes. To enable adaptive prompts capture distinctive text features and complex background distribution, we propose Adaptive Feature Alignment module(AFA). By aligning learnable tokens of different attributes with visual features and prompt prototypes, AFA enables adaptive prompts to capture both general and distinctive attribute information. TSAL can capture the unique attributes of text and achieve precise segmentation using only few images. Experiments demonstrate that our method achieves SOTA performance on multiple text segmentation datasets under few-shot settings and show great potential in text-related domains.