 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational Agents via Task-Oriented Adversarial Memory Adaptation
Jan 29, 2026Conversational agents struggle to handle long conversations due to context window limitations. Therefore, memory systems are developed to leverage essential historical information. Existing memory systems typically follow a pipeline of offline memory construction and update, and online retrieval. Despite the flexible online phase, the offline phase remains fixed and task-independent. In this phase, memory construction operates under a predefined workflow and fails to emphasize task relevant information. Meanwhile, memory updates are guided by generic metrics rather than task specific supervision. This leads to a misalignment between offline memory preparation and task requirements, which undermines downstream task performance. To this end, we propose an Adversarial Memory Adaptation mechanism (AMA) that aligns memory construction and update with task objectives by simulating task execution. Specifically, first, a challenger agent generates question answer pairs based on the original dialogues. The constructed memory is then used to answer these questions, simulating downstream inference. Subsequently, an evaluator agent assesses the responses and performs error analysis. Finally, an adapter agent analyzes the error cases and performs dual level updates on both the construction strategy and the content. Through this process, the memory system receives task aware supervision signals in advance during the offline phase, enhancing its adaptability to downstream tasks. AMA can be integrated into various existing memory systems, and extensive experiments on long dialogue benchmark LoCoMo demonstrate its effectiveness.
Exploring Spectral Characteristics for Single Image Reflection Removal
Sep 16, 2025



Eliminating reflections caused by incident light interacting with reflective medium remains an ill-posed problem in the image restoration area. The primary challenge arises from the overlapping of reflection and transmission components in the captured images, which complicates the task of accurately distinguishing and recovering the clean background. Existing approaches typically address reflection removal solely in the image domain, ignoring the spectral property variations of reflected light, which hinders their ability to effectively discern reflections. In this paper, we start with a new perspective on spectral learning, and propose the Spectral Codebook to reconstruct the optical spectrum of the reflection image. The reflections can be effectively distinguished by perceiving the wavelength differences between different light sources in the spectrum. To leverage the reconstructed spectrum, we design two spectral prior refinement modules to re-distribute pixels in the spatial dimension and adaptively enhance the spectral differences along the wavelength dimension. Furthermore, we present the Spectrum-Aware Transformer to jointly recover the transmitted content in spectral and pixel domains. Experimental results on three different reflection benchmarks demonstrate the superiority and generalization ability of our method compared to state-of-the-art models.
A Scenario-Oriented Survey of Federated Recommender Systems: Techniques, Challenges, and Future Directions
Aug 27, 2025Extending recommender systems to federated learning (FL) frameworks to protect the privacy of users or platforms while making recommendations has recently gained widespread attention in academia. This is due to the natural coupling of recommender systems and federated learning architectures: the data originates from distributed clients (mostly mobile devices held by users), which are highly related to privacy. In a centralized recommender system (CenRec), the central server collects clients' data, trains the model, and provides the service. Whereas in federated recommender systems (FedRec), the step of data collecting is omitted, and the step of model training is offloaded to each client. The server only aggregates the model and other knowledge, thus avoiding client privacy leakage. Some surveys of federated recommender systems discuss and analyze related work from the perspective of designing FL systems. However, their utility drops by ignoring specific recommendation scenarios' unique characteristics and practical challenges. For example, the statistical heterogeneity issue in cross-domain FedRec originates from the label drift of the data held by different platforms, which is mainly caused by the recommender itself, but not the federated architecture. Therefore, it should focus more on solving specific problems in real-world recommendation scenarios to encourage the deployment FedRec. To this end, this review comprehensively analyzes the coupling of recommender systems and federated learning from the perspective of recommendation researchers and practitioners. We establish a clear link between recommendation scenarios and FL frameworks, systematically analyzing scenario-specific approaches, practical challenges, and potential opportunities. We aim to develop guidance for the real-world deployment of FedRec, bridging the gap between existing research and applications.
A Model-agnostic Strategy to Mitigate Embedding Degradation in Personalized Federated Recommendation
Aug 27, 2025Centralized recommender systems encounter privacy leakage due to the need to collect user behavior and other private data. Hence, federated recommender systems (FedRec) have become a promising approach with an aggregated global model on the server. However, this distributed training paradigm suffers from embedding degradation caused by suboptimal personalization and dimensional collapse, due to the existence of sparse interactions and heterogeneous preferences. To this end, we propose a novel model-agnostic strategy for FedRec to strengthen the personalized embedding utility, which is called Personalized Local-Global Collaboration (PLGC). It is the first research in federated recommendation to alleviate the dimensional collapse issue. Particularly, we incorporate the frozen global item embedding table into local devices. Based on a Neural Tangent Kernel strategy that dynamically balances local and global information, PLGC optimizes personalized representations during forward inference, ultimately converging to user-specific preferences. Additionally, PLGC carries on a contrastive objective function to reduce embedding redundancy by dissolving dependencies between dimensions, thereby improving the backward representation learning process. We introduce PLGC as a model-agnostic personalized training strategy for federated recommendations that can be applied to existing baselines to alleviate embedding degradation. Extensive experiments on five real-world datasets have demonstrated the effectiveness and adaptability of PLGC, which outperforms various baseline algorithms.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Optimizing Large Language Model Training Using FP4 Quantization
Jan 28, 2025



The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operations to reduce these costs. While FP8 precision has demonstrated feasibility, leveraging FP4 remains a challenge due to significant quantization errors and limited representational capacity. This work introduces the first FP4 training framework for LLMs, addressing these challenges with two key innovations: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B tokens. With the emergence of next-generation hardware supporting FP4, our framework sets a foundation for efficient ultra-low precision training.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Neighborhood Commonality-aware Evolution Network for Continuous Generalized Category Discovery
Dec 07, 2024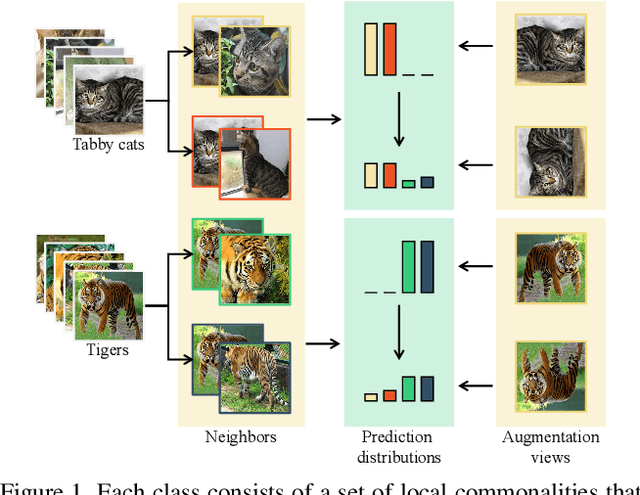
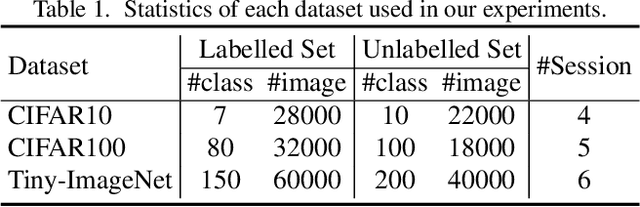
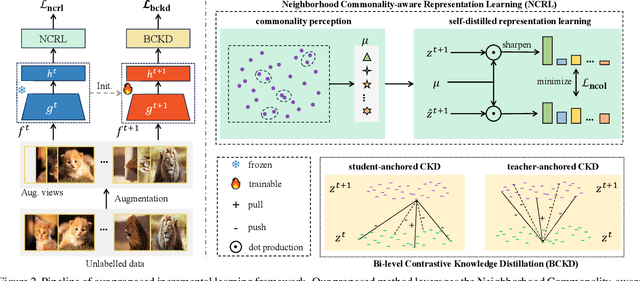
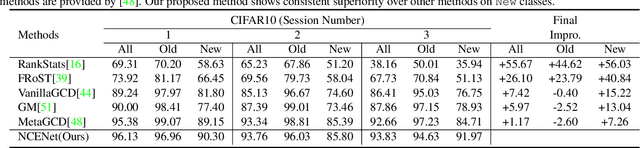
Continuous Generalized Category Discovery (C-GCD) aims to continually discover novel classes from unlabelled image sets while maintaining performance on old classes. In this paper, we propose a novel learning framework, dubbed Neighborhood Commonality-aware Evolution Network (NCENet) that conquers this task from the perspective of representation learning. Concretely, to learn discriminative representations for novel classes, a Neighborhood Commonality-aware Representation Learning (NCRL) is designed, which exploits local commonalities derived neighborhoods to guide the learning of representational differences between instances of different classes. To maintain the representation ability for old classes, a Bi-level Contrastive Knowledge Distillation (BCKD) module is designed, which leverages contrastive learning to perceive the learning and learned knowledge and conducts knowledge distillation. Extensive experiments conducted on CIFAR10, CIFAR100, and Tiny-ImageNet demonstrate the superior performance of NCENet compared to the previous state-of-the-art method. Particularly, in the last incremental learning session on CIFAR100, the clustering accuracy of NCENet outperforms the second-best method by a margin of 3.09\% on old classes and by a margin of 6.32\% on new classes. Our code will be publicly available at \href{https://github.com/xjtuYW/NCENet.git}{https://github.com/xjtuYW/NCENet.git}. \end{abstract}
Pseudo-Label Enhanced Prototypical Contrastive Learning for Uniformed Intent Discovery
Oct 26, 2024



New intent discovery is a crucial capability for task-oriented dialogue systems. Existing methods focus on transferring in-domain (IND) prior knowledge to out-of-domain (OOD) data through pre-training and clustering stages. They either handle the two processes in a pipeline manner, which exhibits a gap between intent representation and clustering process or use typical contrastive clustering that overlooks the potential supervised signals from the whole data. Besides, they often individually deal with open intent discovery or OOD settings. To this end, we propose a Pseudo-Label enhanced Prototypical Contrastive Learning (PLPCL) model for uniformed intent discovery. We iteratively utilize pseudo-labels to explore potential positive/negative samples for contrastive learning and bridge the gap between representation and clustering. To enable better knowledge transfer, we design a prototype learning method integrating the supervised and pseudo signals from IND and OOD samples. In addition, our method has been proven effective in two different settings of discovering new intents. Experiments on three benchmark datasets and two task settings demonstrate the effectiveness of our approach.
Knowledge Adaptation Network for Few-Shot Class-Incremental Learning
Sep 18, 2024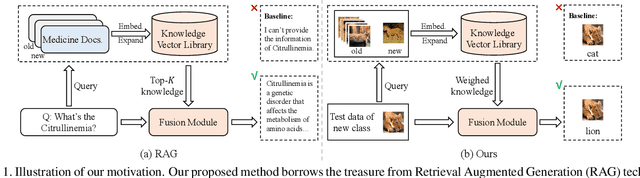
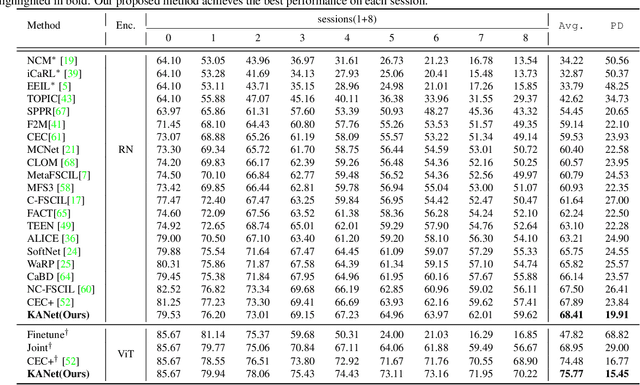
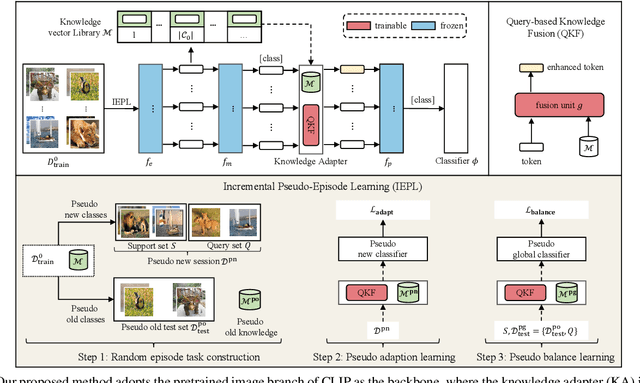
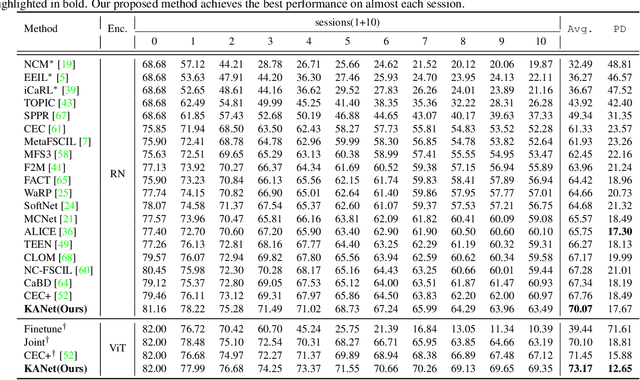
Few-shot class-incremental learning (FSCIL) aims to incrementally recognize new classes using a few samples while maintaining the performance on previously learned classes. One of the effective methods to solve this challenge is to construct prototypical evolution classifiers. Despite the advancement achieved by most existing methods, the classifier weights are simply initialized using mean features. Because representations for new classes are weak and biased, we argue such a strategy is suboptimal. In this paper, we tackle this issue from two aspects. Firstly, thanks to the development of foundation models, we employ a foundation model, the CLIP, as the network pedestal to provide a general representation for each class. Secondly, to generate a more reliable and comprehensive instance representation, we propose a Knowledge Adapter (KA) module that summarizes the data-specific knowledge from training data and fuses it into the general representation. Additionally, to tune the knowledge learned from the base classes to the upcoming classes, we propose a mechanism of Incremental Pseudo Episode Learning (IPEL) by simulating the actual FSCIL. Taken together, our proposed method, dubbed as Knowledge Adaptation Network (KANet), achieves competitive performance on a wide range of datasets, including CIFAR100, CUB200, and ImageNet-R.