 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Graph, Explicit Retrieval: Towards Efficient and Interpretable Long-horizon Memory for Large Language Models
Jan 06, 2026Long-horizon applications increasingly require large language models (LLMs) to answer queries when relevant evidence is sparse and dispersed across very long contexts. Existing memory systems largely follow two paradigms: explicit structured memories offer interpretability but often become brittle under long-context overload, while latent memory mechanisms are efficient and stable yet difficult to inspect. We propose LatentGraphMem, a memory framework that combines implicit graph memory with explicit subgraph retrieval. LatentGraphMem stores a graph-structured memory in latent space for stability and efficiency, and exposes a task-specific subgraph retrieval interface that returns a compact symbolic subgraph under a fixed budget for downstream reasoning and human inspection. During training, an explicit graph view is materialized to interface with a frozen reasoner for question-answering supervision. At inference time, retrieval is performed in latent space and only the retrieved subgraph is externalized. Experiments on long-horizon benchmarks across multiple model scales show that LatentGraphMem consistently outperforms representative explicit-graph and latent-memory baselines, while enabling parameter-efficient adaptation and flexible scaling to larger reasoners without introducing large symbolic artifacts.
MentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
Exploring Safety Alignment Evaluation of LLMs in Chinese Mental Health Dialogues via LLM-as-Judge
Aug 11, 2025Evaluating the safety alignment of LLM responses in high-risk mental health dialogues is particularly difficult due to missing gold-standard answers and the ethically sensitive nature of these interactions. To address this challenge, we propose PsyCrisis-Bench, a reference-free evaluation benchmark based on real-world Chinese mental health dialogues. It evaluates whether the model responses align with the safety principles defined by experts. Specifically designed for settings without standard references, our method adopts a prompt-based LLM-as-Judge approach that conducts in-context evaluation using expert-defined reasoning chains grounded in psychological intervention principles. We employ binary point-wise scoring across multiple safety dimensions to enhance the explainability and traceability of the evaluation. Additionally, we present a manually curated, high-quality Chinese-language dataset covering self-harm, suicidal ideation, and existential distress, derived from real-world online discourse. Experiments on 3600 judgments show that our method achieves the highest agreement with expert assessments and produces more interpretable evaluation rationales compared to existing approaches. Our dataset and evaluation tool are publicly available to facilitate further research.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025


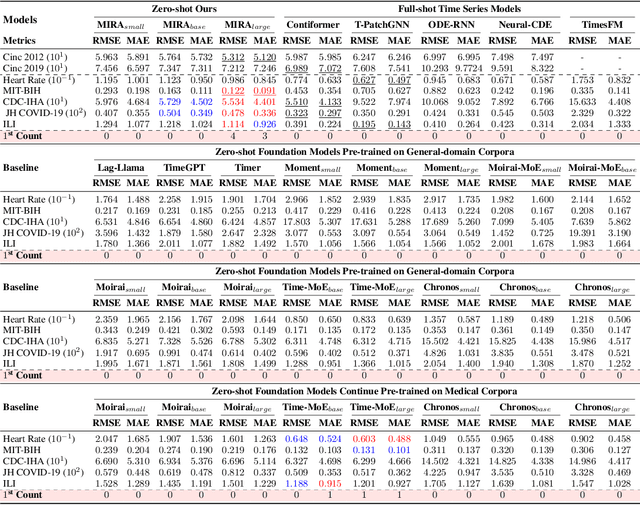
A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
MMAFFBen: A Multilingual and Multimodal Affective Analysis Benchmark for Evaluating LLMs and VLMs
May 30, 2025



Large language models and vision-language models (which we jointly call LMs) have transformed NLP and CV, demonstrating remarkable potential across various fields. However, their capabilities in affective analysis (i.e. sentiment analysis and emotion detection) remain underexplored. This gap is largely due to the absence of comprehensive evaluation benchmarks, and the inherent complexity of affective analysis tasks. In this paper, we introduce MMAFFBen, the first extensive open-source benchmark for multilingual multimodal affective analysis. MMAFFBen encompasses text, image, and video modalities across 35 languages, covering four key affective analysis tasks: sentiment polarity, sentiment intensity, emotion classification, and emotion intensity. Moreover, we construct the MMAFFIn dataset for fine-tuning LMs on affective analysis tasks, and further develop MMAFFLM-3b and MMAFFLM-7b based on it. We evaluate various representative LMs, including GPT-4o-mini, providing a systematic comparison of their affective understanding capabilities. This project is available at https://github.com/lzw108/MMAFFBen.
Rumor Detection by Multi-task Suffix Learning based on Time-series Dual Sentiments
Feb 20, 2025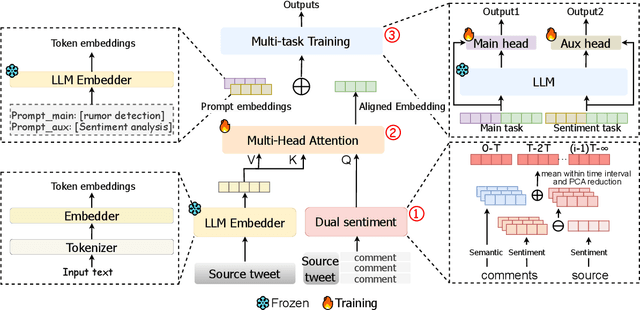



The widespread dissemination of rumors on social media has a significant impact on people's lives, potentially leading to public panic and fear. Rumors often evoke specific sentiments, resonating with readers and prompting sharing. To effectively detect and track rumors, it is essential to observe the fine-grained sentiments of both source and response message pairs as the rumor evolves over time. However, current rumor detection methods fail to account for this aspect. In this paper, we propose MSuf, the first multi-task suffix learning framework for rumor detection and tracking using time series dual (coupled) sentiments. MSuf includes three modules: (1) an LLM to extract sentiment intensity features and sort them chronologically; (2) a module that fuses the sorted sentiment features with their source text word embeddings to obtain an aligned embedding; (3) two hard prompts are combined with the aligned vector to perform rumor detection and sentiment analysis using one frozen LLM. MSuf effectively enhances the performance of LLMs for rumor detection with only minimal parameter fine-tuning. Evaluating MSuf on four rumor detection benchmarks, we find significant improvements compared to other emotion-based methods.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
FMDLlama: Financial Misinformation Detection based on Large Language Models
Sep 24, 2024The emergence of social media has made the spread of misinformation easier. In the financial domain, the accuracy of information is crucial for various aspects of financial market, which has made financial misinformation detection (FMD) an urgent problem that needs to be addressed. Large language models (LLMs) have demonstrated outstanding performance in various fields. However, current studies mostly rely on traditional methods and have not explored the application of LLMs in the field of FMD. The main reason is the lack of FMD instruction tuning datasets and evaluation benchmarks. In this paper, we propose FMDLlama, the first open-sourced instruction-following LLMs for FMD task based on fine-tuning Llama3.1 with instruction data, the first multi-task FMD instruction dataset (FMDID) to support LLM instruction tuning, and a comprehensive FMD evaluation benchmark (FMD-B) with classification and explanation generation tasks to test the FMD ability of LLMs. We compare our models with a variety of LLMs on FMD-B, where our model outperforms all other open-sourced LLMs as well as ChatGPT.
Selective Preference Optimization via Token-Level Reward Function Estimation
Aug 24, 2024



Recent advancements in large language model alignment leverage token-level supervisions to perform fine-grained preference optimization. However, existing token-level alignment methods either optimize on all available tokens, which can be noisy and inefficient, or perform selective training with complex and expensive key token selection strategies. In this work, we propose Selective Preference Optimization (SePO), a novel selective alignment strategy that centers on efficient key token selection. SePO proposes the first token selection method based on Direct Preference Optimization (DPO), which trains an oracle model to estimate a token-level reward function on the target data. This method applies to any existing alignment datasets with response-level annotations and enables cost-efficient token selection with small-scale oracle models and training data. The estimated reward function is then utilized to score all tokens within the target dataset, where only the key tokens are selected to supervise the target policy model with a reference model-free contrastive objective function. Extensive experiments on three public evaluation benchmarks show that SePO significantly outperforms competitive baseline methods by only optimizing 30% key tokens on the target dataset. SePO applications on weak-to-strong generalization show that weak oracle models effectively supervise strong policy models with up to 16.8x more parameters. SePO also effectively selects key tokens from out-of-distribution data to enhance strong policy models and alleviate the over-optimization problem.
RAEmoLLM: Retrieval Augmented LLMs for Cross-Domain Misinformation Detection Using In-Context Learning based on Emotional Information
Jun 16, 2024Misinformation is prevalent in various fields such as education, politics, health, etc., causing significant harm to society. However, current methods for cross-domain misinformation detection rely on time and resources consuming fine-tuning and complex model structures. With the outstanding performance of LLMs, many studies have employed them for misinformation detection. Unfortunately, they focus on in-domain tasks and do not incorporate significant sentiment and emotion features (which we jointly call affect). In this paper, we propose RAEmoLLM, the first retrieval augmented (RAG) LLMs framework to address cross-domain misinformation detection using in-context learning based on affective information. It accomplishes this by applying an emotion-aware LLM to construct a retrieval database of affective embeddings. This database is used by our retrieval module to obtain source-domain samples, which are subsequently used for the inference module's in-context few-shot learning to detect target domain misinformation. We evaluate our framework on three misinformation benchmarks. Results show that RAEmoLLM achieves significant improvements compared to the zero-shot method on three datasets, with the highest increases of 20.69%, 23.94%, and 39.11% respectively. This work will be released on https://github.com/lzw108/RAEmoLLM.