 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
Locate-then-Merge: Neuron-Level Parameter Fusion for Mitigating Catastrophic Forgetting in Multimodal LLMs
May 22, 2025Although multimodal large language models (MLLMs) have achieved impressive performance, the multimodal instruction tuning stage often causes catastrophic forgetting of the base LLM's language ability, even in strong models like Llama3. To address this, we propose Locate-then-Merge, a training-free parameter fusion framework that first locates important parameters and then selectively merges them. We further introduce Neuron-Fusion, a neuron-level strategy that preserves the influence of neurons with large parameter shifts--neurons likely responsible for newly acquired visual capabilities--while attenuating the influence of neurons with smaller changes that likely encode general-purpose language skills. This design enables better retention of visual adaptation while mitigating language degradation. Experiments on 13 benchmarks across both language and visual tasks show that Neuron-Fusion consistently outperforms existing model merging methods. Further analysis reveals that our method effectively reduces context hallucination in generation.
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
Jan 24, 2025



Large language models (LLMs) often exhibit gender bias, posing challenges for their safe deployment. Existing methods to mitigate bias lack a comprehensive understanding of its mechanisms or compromise the model's core capabilities. To address these issues, we propose the CommonWords dataset, to systematically evaluate gender bias in LLMs. Our analysis reveals pervasive bias across models and identifies specific neuron circuits, including gender neurons and general neurons, responsible for this behavior. Notably, editing even a small number of general neurons can disrupt the model's overall capabilities due to hierarchical neuron interactions. Based on these insights, we propose an interpretable neuron editing method that combines logit-based and causal-based strategies to selectively target biased neurons. Experiments on five LLMs demonstrate that our method effectively reduces gender bias while preserving the model's original capabilities, outperforming existing fine-tuning and editing approaches. Our findings contribute a novel dataset, a detailed analysis of bias mechanisms, and a practical solution for mitigating gender bias in LLMs.
Understanding Multimodal LLMs: the Mechanistic Interpretability of Llava in Visual Question Answering
Nov 17, 2024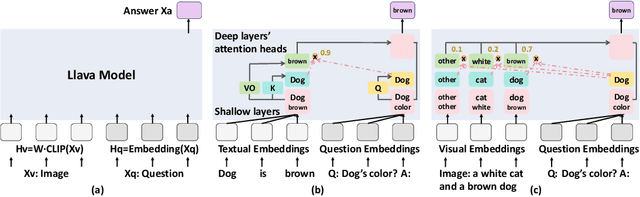



Understanding the mechanisms behind Large Language Models (LLMs) is crucial for designing improved models and strategies. While recent studies have yielded valuable insights into the mechanisms of textual LLMs, the mechanisms of Multi-modal Large Language Models (MLLMs) remain underexplored. In this paper, we apply mechanistic interpretability methods to analyze the visual question answering (VQA) mechanisms in the first MLLM, Llava. We compare the mechanisms between VQA and textual QA (TQA) in color answering tasks and find that: a) VQA exhibits a mechanism similar to the in-context learning mechanism observed in TQA; b) the visual features exhibit significant interpretability when projecting the visual embeddings into the embedding space; and c) Llava enhances the existing capabilities of the corresponding textual LLM Vicuna during visual instruction tuning. Based on these findings, we develop an interpretability tool to help users and researchers identify important visual locations for final predictions, aiding in the understanding of visual hallucination. Our method demonstrates faster and more effective results compared to existing interpretability approaches. Code: \url{https://github.com/zepingyu0512/llava-mechanism}
Interpreting Arithmetic Mechanism in Large Language Models through Comparative Neuron Analysis
Sep 21, 2024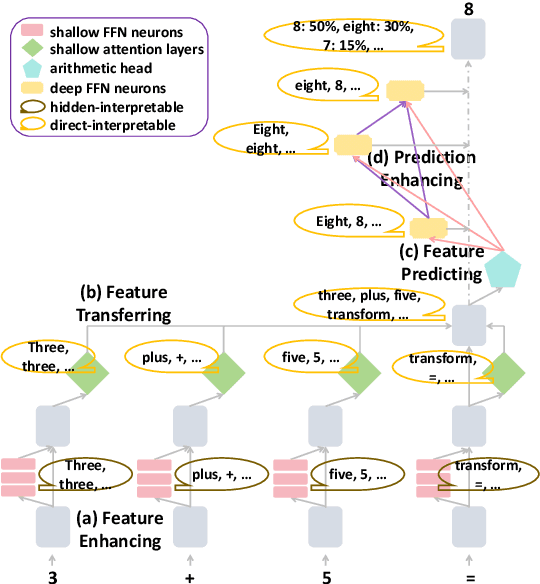

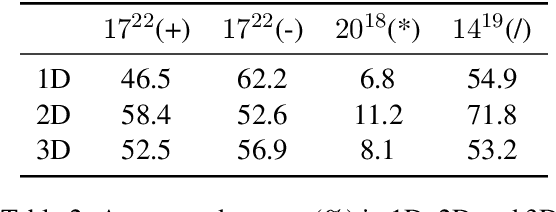
We find arithmetic ability resides within a limited number of attention heads, with each head specializing in distinct operations. To delve into the reason, we introduce the Comparative Neuron Analysis (CNA) method, which identifies an internal logic chain consisting of four distinct stages from input to prediction: feature enhancing with shallow FFN neurons, feature transferring by shallow attention layers, feature predicting by arithmetic heads, and prediction enhancing among deep FFN neurons. Moreover, we identify the human-interpretable FFN neurons within both feature-enhancing and feature-predicting stages. These findings lead us to investigate the mechanism of LoRA, revealing that it enhances prediction probabilities by amplifying the coefficient scores of FFN neurons related to predictions. Finally, we apply our method in model pruning for arithmetic tasks and model editing for reducing gender bias. Code is on https://github.com/zepingyu0512/arithmetic-mechanism.
How do Large Language Models Learn In-Context? Query and Key Matrices of In-Context Heads are Two Towers for Metric Learning
Feb 05, 2024We explore the mechanism of in-context learning and propose a hypothesis using locate-and-project method. In shallow layers, the features of demonstrations are merged into their corresponding labels, and the features of the input text are aggregated into the last token. In deep layers, in-context heads make great contributions. In each in-context head, the value-output matrix extracts the labels' features. Query and key matrices compute the attention weights between the input text and each demonstration. The larger the attention weight is, the more label information is transferred into the last token for predicting the next word. Query and key matrices can be regarded as two towers for learning the similarity metric between the input text and each demonstration. Based on this hypothesis, we explain why imbalanced labels and demonstration order affect predictions. We conduct experiments on GPT2 large, Llama 7B, 13B and 30B. The results can support our analysis. Overall, our study provides a new method and a reasonable hypothesis for understanding the mechanism of in-context learning. Our code will be released on github.
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Jan 16, 2024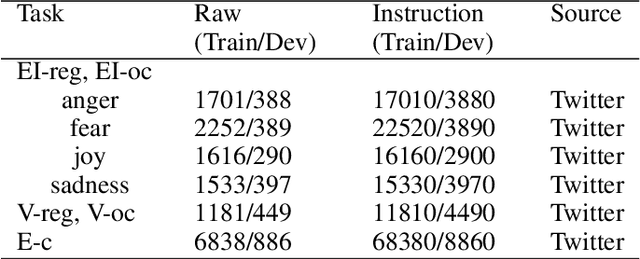
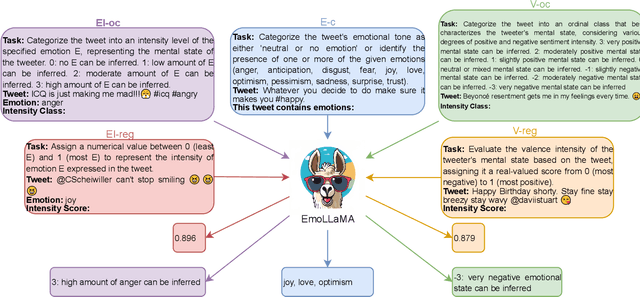


Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
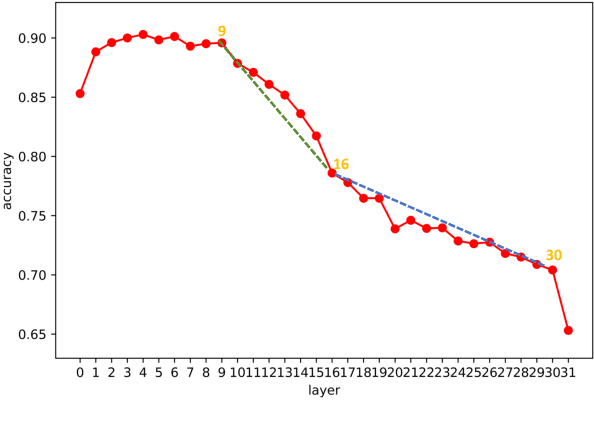
Exploring the Residual Stream of Transformers
Dec 19, 2023



Transformer-based models have achieved great breakthroughs in recent years. However, there are many significant questions that have not been answered in the field of explaining the reason why the models have powerful outputs. We do not know how to locate the models' important parameters storing the knowledge for predicting the next word, and whether these parameters are stored on the same layer/module or different ones. Moreover, we do not understand the mechanism to merge the knowledge into the final embedding for next word prediction. In this paper, we explore the residual stream of transformers to increase the interpretability. We find the mechanism behind residual connection is a direct addition function on before-softmax values, so the probabilities of tokens with larger before-softmax values will increase. Moreover, we prove that using log probability increase as contribution scores is reasonable, and based on this we can locate important parameters. Besides, we propose a method to analyze how previous layers affect upper layers by comparing the inner products. The experimental results and case study show that our research can increase the interpretability of transformer-based models. We will release our code on https://github.com/zepingyu0512/residualstream.
Emotion Detection for Misinformation: A Review
Nov 01, 2023
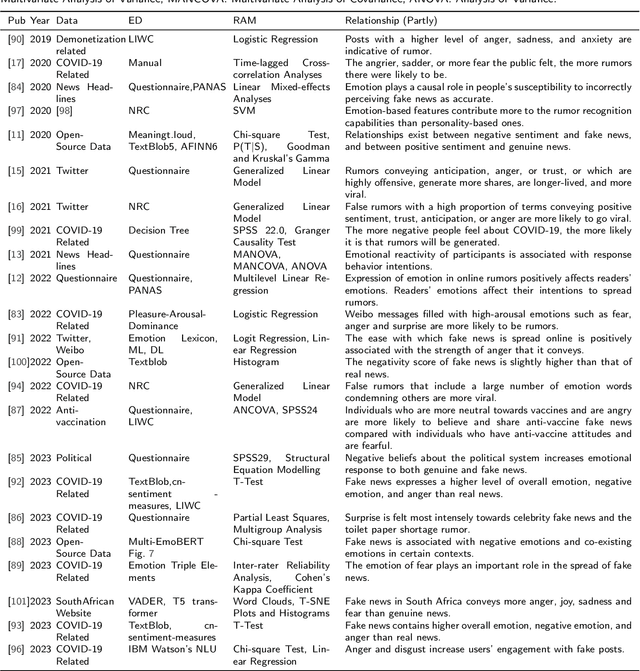
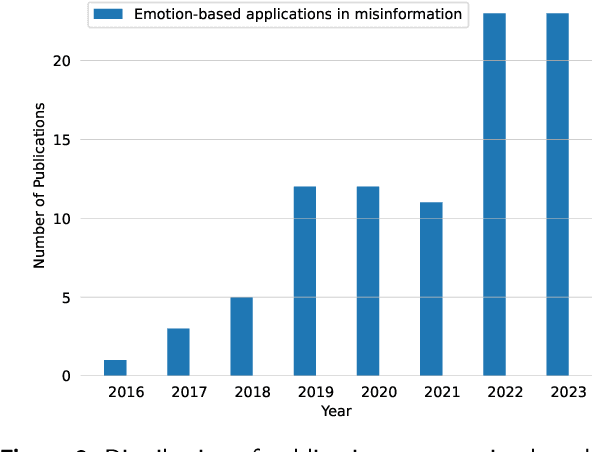
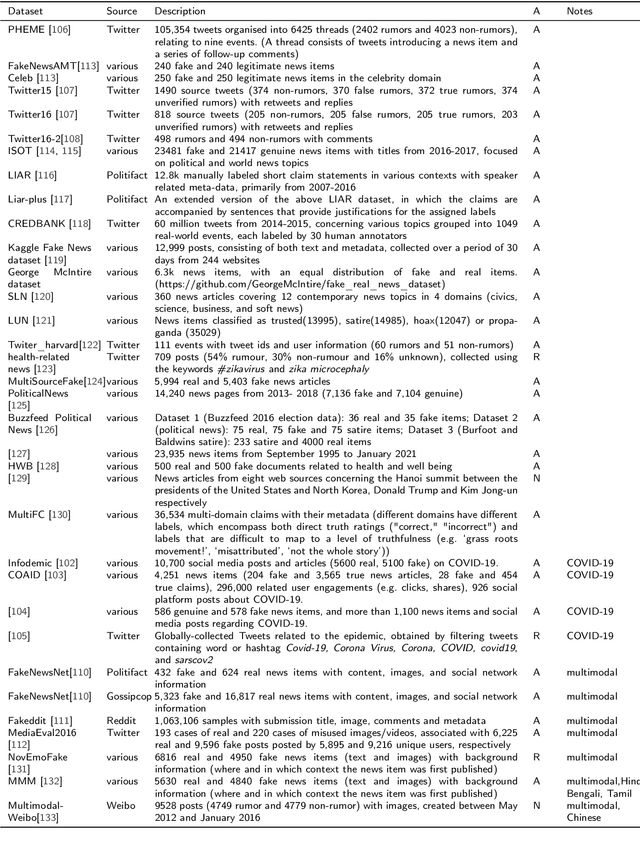
With the advent of social media, an increasing number of netizens are sharing and reading posts and news online. However, the huge volumes of misinformation (e.g., fake news and rumors) that flood the internet can adversely affect people's lives, and have resulted in the emergence of rumor and fake news detection as a hot research topic. The emotions and sentiments of netizens, as expressed in social media posts and news, constitute important factors that can help to distinguish fake news from genuine news and to understand the spread of rumors. This article comprehensively reviews emotion-based methods for misinformation detection. We begin by explaining the strong links between emotions and misinformation. We subsequently provide a detailed analysis of a range of misinformation detection methods that employ a variety of emotion, sentiment and stance-based features, and describe their strengths and weaknesses. Finally, we discuss a number of ongoing challenges in emotion-based misinformation detection based on large language models and suggest future research directions, including data collection (multi-platform, multilingual), annotation, benchmark, multimodality, and interpretability.
Sliced Recurrent Neural Networks
Jul 06, 2018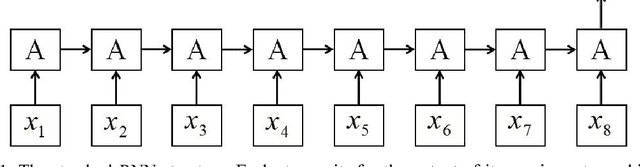
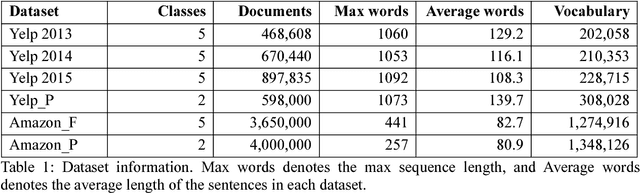
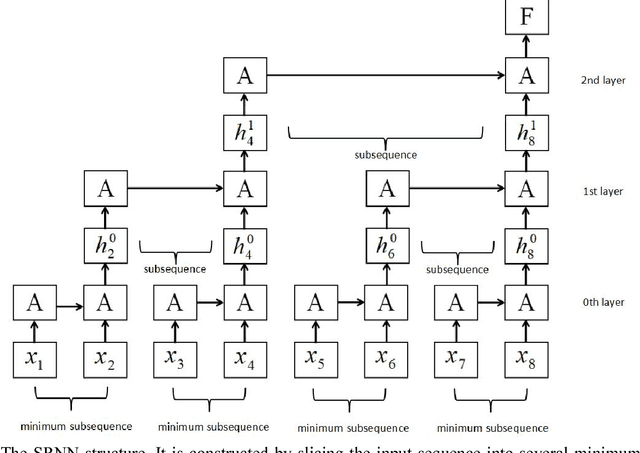
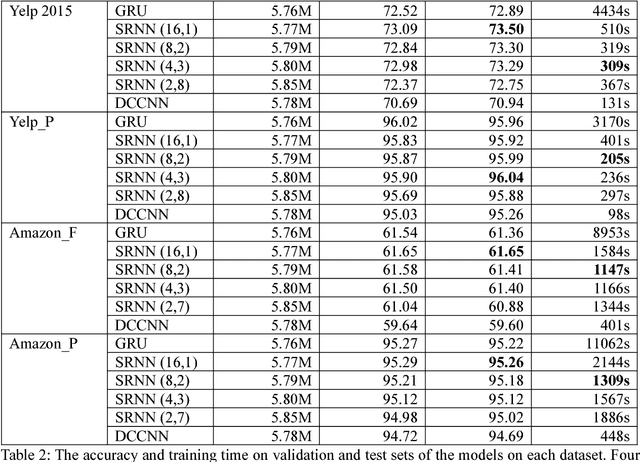
Recurrent neural networks have achieved great success in many NLP tasks. However, they have difficulty in parallelization because of the recurrent structure, so it takes much time to train RNNs. In this paper, we introduce sliced recurrent neural networks (SRNNs), which could be parallelized by slicing the sequences into many subsequences. SRNNs have the ability to obtain high-level information through multiple layers with few extra parameters. We prove that the standard RNN is a special case of the SRNN when we use linear activation functions. Without changing the recurrent units, SRNNs are 136 times as fast as standard RNNs and could be even faster when we train longer sequences. Experiments on six largescale sentiment analysis datasets show that SRNNs achieve better performance than standard RNNs.