 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRA: Grounding Discrete-Time Joint Acceleration in Voltage-Constrained Actuation
May 11, 2026Discrete-time joint acceleration constraints are widely used to enforce position and velocity limits. However, under voltage-constrained electric actuators, kinematically admissible accelerations may be physically unrealizable, exposing a missing execution-level abstraction. We propose Voltage-Realizable Acceleration (VRA), a joint-level acceleration interface that grounds kinematic acceleration in voltage-constrained actuator physics by restricting commanded accelerations to voltage-realizable constraints. Hardware experiments on electric actuators and a wheel-legged quadruped show that VRA removes unrealizable accelerations, restores consistent near-constraint execution, and reduces constraint-induced oscillations.
Jumping Control for a Quadrupedal Wheeled-Legged Robot via NMPC and DE Optimization
Feb 25, 2026Quadrupedal wheeled-legged robots combine the advantages of legged and wheeled locomotion to achieve superior mobility, but executing dynamic jumps remains a significant challenge due to the additional degrees of freedom introduced by wheeled legs. This paper develops a mini-sized wheeled-legged robot for agile motion and presents a novel motion control framework that integrates the Nonlinear Model Predictive Control (NMPC) for locomotion and the Differential Evolution (DE) based trajectory optimization for jumping in quadrupedal wheeled-legged robots. The proposed controller utilizes wheel motion and locomotion to enhance jumping performance, achieving versatile maneuvers such as vertical jumping, forward jumping, and backflips. Extensive simulations and real-world experiments validate the effectiveness of the framework, demonstrating a forward jump over a 0.12 m obstacle and a vertical jump reaching 0.5 m.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
Whole-Body Control Framework for Humanoid Robots with Heavy Limbs: A Model-Based Approach
Jun 17, 2025Humanoid robots often face significant balance issues due to the motion of their heavy limbs. These challenges are particularly pronounced when attempting dynamic motion or operating in environments with irregular terrain. To address this challenge, this manuscript proposes a whole-body control framework for humanoid robots with heavy limbs, using a model-based approach that combines a kino-dynamics planner and a hierarchical optimization problem. The kino-dynamics planner is designed as a model predictive control (MPC) scheme to account for the impact of heavy limbs on mass and inertia distribution. By simplifying the robot's system dynamics and constraints, the planner enables real-time planning of motion and contact forces. The hierarchical optimization problem is formulated using Hierarchical Quadratic Programming (HQP) to minimize limb control errors and ensure compliance with the policy generated by the kino-dynamics planner. Experimental validation of the proposed framework demonstrates its effectiveness. The humanoid robot with heavy limbs controlled by the proposed framework can achieve dynamic walking speeds of up to 1.2~m/s, respond to external disturbances of up to 60~N, and maintain balance on challenging terrains such as uneven surfaces, and outdoor environments.
Multimodal Inverse Attention Network with Intrinsic Discriminant Feature Exploitation for Fake News Detection
Feb 03, 2025



Multimodal fake news detection has garnered significant attention due to its profound implications for social security. While existing approaches have contributed to understanding cross-modal consistency, they often fail to leverage modal-specific representations and explicit discrepant features. To address these limitations, we propose a Multimodal Inverse Attention Network (MIAN), a novel framework that explores intrinsic discriminative features based on news content to advance fake news detection. Specifically, MIAN introduces a hierarchical learning module that captures diverse intra-modal relationships through local-to-global and local-to-local interactions, thereby generating enhanced unimodal representations to improve the identification of fake news at the intra-modal level. Additionally, a cross-modal interaction module employs a co-attention mechanism to establish and model dependencies between the refined unimodal representations, facilitating seamless semantic integration across modalities. To explicitly extract inconsistency features, we propose an inverse attention mechanism that effectively highlights the conflicting patterns and semantic deviations introduced by fake news in both intra- and inter-modality. Extensive experiments on benchmark datasets demonstrate that MIAN significantly outperforms state-of-the-art methods, underscoring its pivotal contribution to advancing social security through enhanced multimodal fake news detection.
Large Kernel Distillation Network for Efficient Single Image Super-Resolution
Jul 19, 2024Efficient and lightweight single-image super-resolution (SISR) has achieved remarkable performance in recent years. One effective approach is the use of large kernel designs, which have been shown to improve the performance of SISR models while reducing their computational requirements. However, current state-of-the-art (SOTA) models still face problems such as high computational costs. To address these issues, we propose the Large Kernel Distillation Network (LKDN) in this paper. Our approach simplifies the model structure and introduces more efficient attention modules to reduce computational costs while also improving performance. Specifically, we employ the reparameterization technique to enhance model performance without adding extra cost. We also introduce a new optimizer from other tasks to SISR, which improves training speed and performance. Our experimental results demonstrate that LKDN outperforms existing lightweight SR methods and achieves SOTA performance.
MetaAligner: Conditional Weak-to-Strong Correction for Generalizable Multi-Objective Alignment of Language Models
Mar 25, 2024
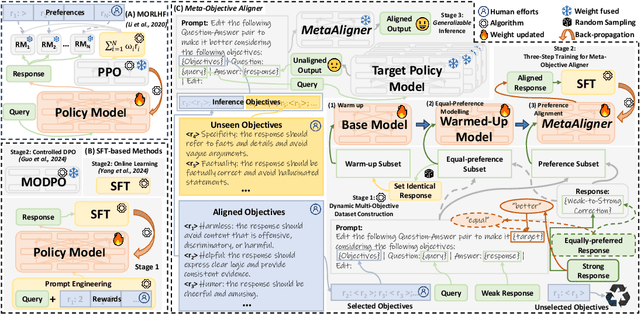


Recent advancements in large language models (LLMs) aim to tackle heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are parameter-adherent to the policy model, leading to two key limitations: (1) the high-cost repetition of their alignment algorithms for each new target model; (2) they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), a model that performs conditional weak-to-strong correction for weak responses to approach strong responses. MetaAligner is the first policy-agnostic and generalizable method for multi-objective preference alignment, which enables plug-and-play alignment by decoupling parameter updates from the policy models and facilitates zero-shot preference alignment for unseen objectives via in-context learning. Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 11 policy models with up to 63x more parameters, and outperforms previous alignment methods with down to 22.27x less computational resources. The model also accurately aligns with unseen objectives, marking the first step towards generalizable multi-objective preference alignment.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Jan 16, 2024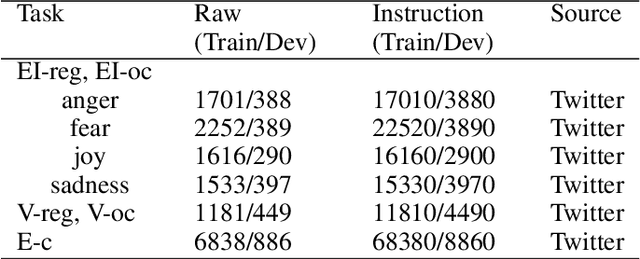
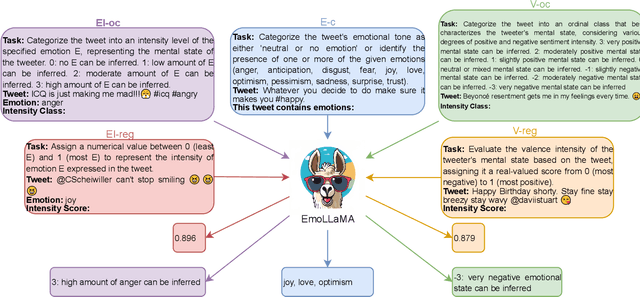


Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
Rethinking Large Language Models in Mental Health Applications
Nov 19, 2023Large Language Models (LLMs) have become valuable assets in mental health, showing promise in both classification tasks and counseling applications. This paper offers a perspective on using LLMs in mental health applications. It discusses the instability of generative models for prediction and the potential for generating hallucinatory outputs, underscoring the need for ongoing audits and evaluations to maintain their reliability and dependability. The paper also distinguishes between the often interchangeable terms ``explainability'' and ``interpretability'', advocating for developing inherently interpretable methods instead of relying on potentially hallucinated self-explanations generated by LLMs. Despite the advancements in LLMs, human counselors' empathetic understanding, nuanced interpretation, and contextual awareness remain irreplaceable in the sensitive and complex realm of mental health counseling. The use of LLMs should be approached with a judicious and considerate mindset, viewing them as tools that complement human expertise rather than seeking to replace it.