 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee-and-Reach: Precise Vision-Language Navigation for UAVs within the Field of View
Jun 18, 2026UAV Vision-Language Navigation (UAV-VLN) is typically formulated as a holistic search-and-reach problem, where long-range target discovery and final target approach are optimized and evaluated jointly. This formulation makes it difficult to assess a critical capability of aerial embodied agents, namely whether a UAV can accurately ground a visible target and translate vision-language evidence into precise 3D motion once the target enters its field of view. To address this limitation, we introduce UAV-VLN-FOV, a target-visible navigation task that isolates the see-and-reach stage and enables a more diagnostic evaluation of terminal reaching ability. We further propose 3DG-VLN, a vision-language waypoint prediction framework guided by dynamic 3D direction cues to enhance fine-grained visual grounding and spatial direction alignment for precise target reaching. Specifically, 3DG-VLN adaptively processes high-resolution front-view and downward-view observations to preserve fine-grained visual and geometric details for target grounding. It also updates the target-relative direction online during closed-loop navigation, allowing the agent to maintain spatial alignment with the target and reduce accumulated direction drift. To support this task, we construct a dedicated high-resolution benchmark which contains 2,717 trajectories with target-oriented high-level instructions, high-resolution front-view and downward-view egocentric observations, and continuous 3D waypoint annotations. Experiments show that 3DG-VLN outperforms competitive UAV-VLN baselines, achieving a 13.82\% improvement in success rate. Real-world trials further demonstrate the potential of 3DG-VLN for practical see-and-reach navigation. The source code and benchmark are available at https://github.com/xuefanfu/3DG-VLN.
Dual-Integrated Low-Latency Single-Lens Infrared Computational Imaging for Object Detection
May 21, 2026Computational imaging enables compact infrared systems, but deep-learning pipelines that combine image reconstruction and object detection often introduce substantial inference latency. Most existing acceleration strategies compress the reconstruction network while overlooking physical priors from the optical path, leaving a trade-off between accuracy and speed. We present Physics-aware Dual-Integrated Network (PDI-Net), a low-latency framework that integrates infrared reconstruction with object detection and further embeds optical priors into the learning process. PDI-Net uses a supervised U-Net during training, while a semi-U-Net encoder shares features directly with a YOLO-based detector during inference, avoiding full image reconstruction. To bridge the gap between fidelity-oriented reconstruction features and detection-oriented semantics, we introduce a physics-aware large-small bridge (PALS-Bridge), which uses field-dependent point spread function priors to adaptively modulate multiscale convolutional branches. A physics-informed optical degradation simulation pipeline is also developed for training and validation. The method is deployed on a single-lens infrared camera, reducing system weight by about 50% compared with traditional multi-lens designs. On the M3FD benchmark under low-SNR conditions, PDI-Net reduces inference time by 84.06% compared with the Rec+Det with pruning strategy while improving mAP@0.5:0.95 by 5.07%. These results demonstrate compact, low-latency computational infrared imaging for real-time object detection on resource-constrained platforms.
Machine Learning-Driven Student Performance Prediction for Enhancing Tiered Instruction
Feb 05, 2025



Student performance prediction is one of the most important subjects in educational data mining. As a modern technology, machine learning offers powerful capabilities in feature extraction and data modeling, providing essential support for diverse application scenarios, as evidenced by recent studies confirming its effectiveness in educational data mining. However, despite extensive prediction experiments, machine learning methods have not been effectively integrated into practical teaching strategies, hindering their application in modern education. In addition, massive features as input variables for machine learning algorithms often leads to information redundancy, which can negatively impact prediction accuracy. Therefore, how to effectively use machine learning methods to predict student performance and integrate the prediction results with actual teaching scenarios is a worthy research subject. To this end, this study integrates the results of machine learning-based student performance prediction with tiered instruction, aiming to enhance student outcomes in target course, which is significant for the application of educational data mining in contemporary teaching scenarios. Specifically, we collect original educational data and perform feature selection to reduce information redundancy. Then, the performance of five representative machine learning methods is analyzed and discussed with Random Forest showing the best performance. Furthermore, based on the results of the classification of students, tiered instruction is applied accordingly, and different teaching objectives and contents are set for all levels of students. The comparison of teaching outcomes between the control and experimental classes, along with the analysis of questionnaire results, demonstrates the effectiveness of the proposed framework.
Concept-Aware Latent and Explicit Knowledge Integration for Enhanced Cognitive Diagnosis
Feb 04, 2025



Cognitive diagnosis can infer the students' mastery of specific knowledge concepts based on historical response logs. However, the existing cognitive diagnostic models (CDMs) represent students' proficiency via a unidimensional perspective, which can't assess the students' mastery on each knowledge concept comprehensively. Moreover, the Q-matrix binarizes the relationship between exercises and knowledge concepts, and it can't represent the latent relationship between exercises and knowledge concepts. Especially, when the granularity of knowledge attributes refines increasingly, the Q-matrix becomes incomplete correspondingly and the sparse binary representation (0/1) fails to capture the intricate relationships among knowledge concepts. To address these issues, we propose a Concept-aware Latent and Explicit Knowledge Integration model for cognitive diagnosis (CLEKI-CD). Specifically, a multidimensional vector is constructed according to the students' mastery and exercise difficulty for each knowledge concept from multiple perspectives, which enhances the representation capabilities of the model. Moreover, a latent Q-matrix is generated by our proposed attention-based knowledge aggregation method, and it can uncover the coverage degree of exercises over latent knowledge. The latent Q-matrix can supplement the sparse explicit Q-matrix with the inherent relationships among knowledge concepts, and mitigate the knowledge coverage problem. Furthermore, we employ a combined cognitive diagnosis layer to integrate both latent and explicit knowledge, further enhancing cognitive diagnosis performance. Extensive experiments on real-world datasets demonstrate that CLEKI-CD outperforms the state-of-the-art models. The proposed CLEKI-CD is promising in practical applications in the field of intelligent education, as it exhibits good interpretability with diagnostic results.
Multimodal Inverse Attention Network with Intrinsic Discriminant Feature Exploitation for Fake News Detection
Feb 03, 2025



Multimodal fake news detection has garnered significant attention due to its profound implications for social security. While existing approaches have contributed to understanding cross-modal consistency, they often fail to leverage modal-specific representations and explicit discrepant features. To address these limitations, we propose a Multimodal Inverse Attention Network (MIAN), a novel framework that explores intrinsic discriminative features based on news content to advance fake news detection. Specifically, MIAN introduces a hierarchical learning module that captures diverse intra-modal relationships through local-to-global and local-to-local interactions, thereby generating enhanced unimodal representations to improve the identification of fake news at the intra-modal level. Additionally, a cross-modal interaction module employs a co-attention mechanism to establish and model dependencies between the refined unimodal representations, facilitating seamless semantic integration across modalities. To explicitly extract inconsistency features, we propose an inverse attention mechanism that effectively highlights the conflicting patterns and semantic deviations introduced by fake news in both intra- and inter-modality. Extensive experiments on benchmark datasets demonstrate that MIAN significantly outperforms state-of-the-art methods, underscoring its pivotal contribution to advancing social security through enhanced multimodal fake news detection.
Communication-Efficient and Privacy-Adaptable Mechanism for Federated Learning
Jan 21, 2025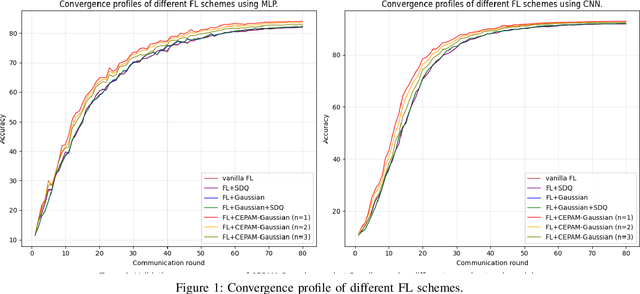
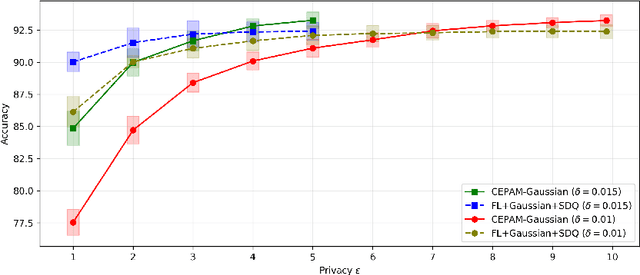
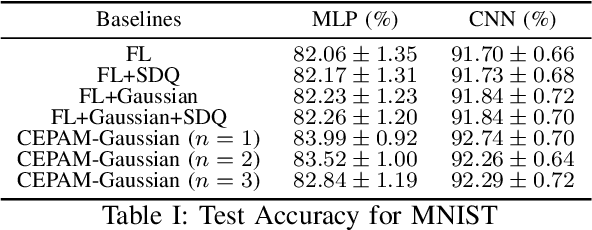
Training machine learning models on decentralized private data via federated learning (FL) poses two key challenges: communication efficiency and privacy protection. In this work, we address these challenges within the trusted aggregator model by introducing a novel approach called the Communication-Efficient and Privacy-Adaptable Mechanism (CEPAM), achieving both objectives simultaneously. In particular, CEPAM leverages the rejection-sampled universal quantizer (RSUQ), a construction of randomized vector quantizer whose resulting distortion is equivalent to a prescribed noise, such as Gaussian or Laplace noise, enabling joint differential privacy and compression. Moreover, we analyze the trade-offs among user privacy, global utility, and transmission rate of CEPAM by defining appropriate metrics for FL with differential privacy and compression. Our CEPAM provides the additional benefit of privacy adaptability, allowing clients and the server to customize privacy protection based on required accuracy and protection. We assess CEPAM's utility performance using MNIST dataset, demonstrating that CEPAM surpasses baseline models in terms of learning accuracy.
HFGCN:Hypergraph Fusion Graph Convolutional Networks for Skeleton-Based Action Recognition
Jan 19, 2025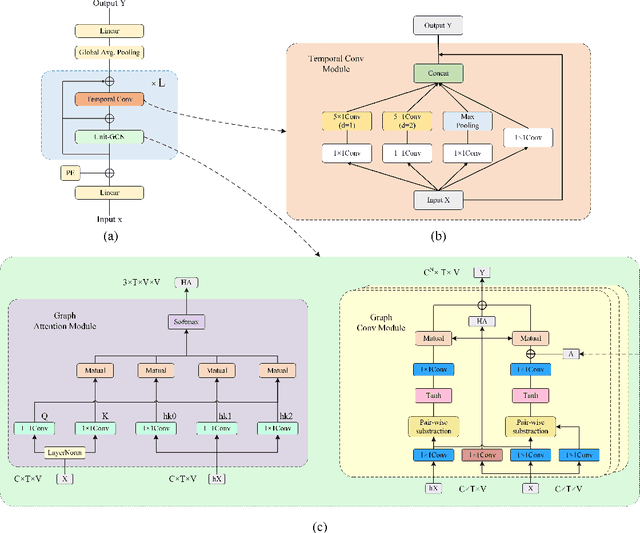
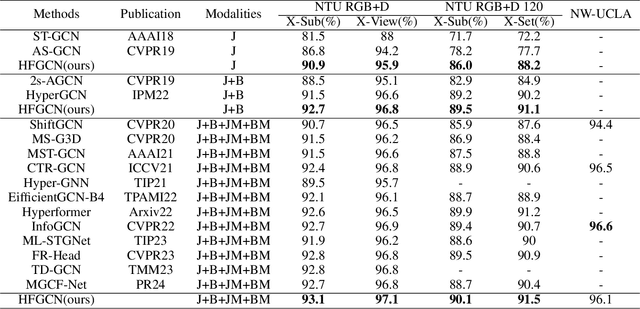
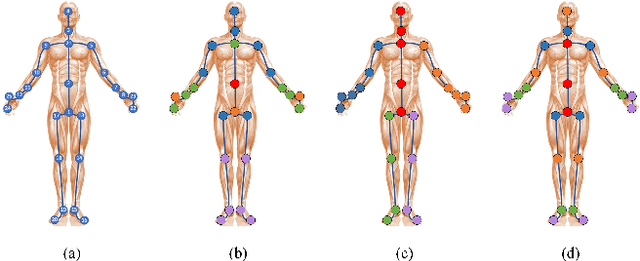
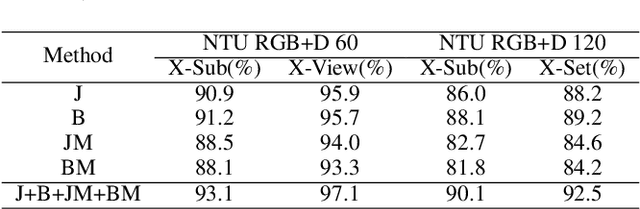
In recent years, action recognition has received much attention and wide application due to its important role in video understanding. Most of the researches on action recognition methods focused on improving the performance via various deep learning methods rather than the classification of skeleton points. The topological modeling between skeleton points and body parts was seldom considered. Although some studies have used a data-driven approach to classify the topology of the skeleton point, the nature of the skeleton point in terms of kinematics has not been taken into consideration. Therefore, in this paper, we draw on the theory of kinematics to adapt the topological relations of the skeleton point and propose a topological relation classification based on body parts and distance from core of body. To synthesize these topological relations for action recognition, we propose a novel Hypergraph Fusion Graph Convolutional Network (HFGCN). In particular, the proposed model is able to focus on the human skeleton points and the different body parts simultaneously, and thus construct the topology, which improves the recognition accuracy obviously. We use a hypergraph to represent the categorical relationships of these skeleton points and incorporate the hypergraph into a graph convolution network to model the higher-order relationships among the skeleton points and enhance the feature representation of the network. In addition, our proposed hypergraph attention module and hypergraph graph convolution module optimize topology modeling in temporal and channel dimensions, respectively, to further enhance the feature representation of the network. We conducted extensive experiments on three widely used datasets.The results validate that our proposed method can achieve the best performance when compared with the state-of-the-art skeleton-based methods.
Cost-Efficient Computation Offloading and Service Chain Caching in LEO Satellite Networks
Nov 14, 2023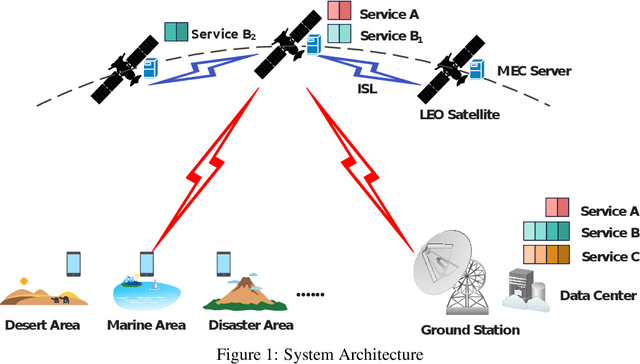
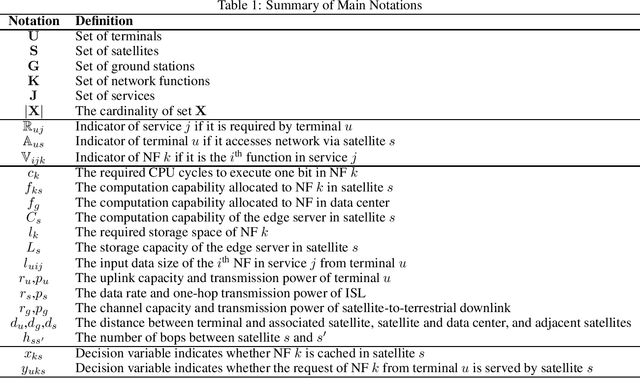

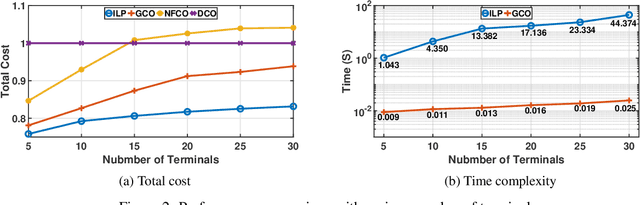
The ever-increasing demand for ubiquitous, continuous, and high-quality services poses a great challenge to the traditional terrestrial network. To mitigate this problem, the mobile-edge-computing-enhanced low earth orbit (LEO) satellite network, which provides both communication connectivity and on-board processing services, has emerged as an effective method. The main issue in LEO satellites includes finding the optimal locations to host network functions (NFs) and then making offloading decisions. In this article, we jointly consider the problem of service chain caching and computation offloading to minimize the overall cost, which consists of task latency and energy consumption. In particular, the collaboration among satellites, the network resource limitations, and the specific operation order of NFs in service chains are taken into account. Then, the problem is formulated and linearized as an integer linear programming model. Moreover, to accelerate the solution, we provide a greedy algorithm with cubic time complexity. Numerical investigations demonstrate the effectiveness of the proposed scheme, which can reduce the overall cost by around 20% compared to the nominal case where NFs are served in data centers.
CPFES: Physical Fitness Evaluation Based on Canadian Agility and Movement Skill Assessment
Aug 28, 2023



In recent years, the assessment of fundamental movement skills integrated with physical education has focused on both teaching practice and the feasibility of assessment. The object of assessment has shifted from multiple ages to subdivided ages, while the content of assessment has changed from complex and time-consuming to concise and efficient. Therefore, we apply deep learning to physical fitness evaluation, we propose a system based on the Canadian Agility and Movement Skill Assessment (CAMSA) Physical Fitness Evaluation System (CPFES), which evaluates children's physical fitness based on CAMSA, and gives recommendations based on the scores obtained by CPFES to help children grow. We have designed a landmark detection module and a pose estimation module, and we have also designed a pose evaluation module for the CAMSA criteria that can effectively evaluate the actions of the child being tested. Our experimental results demonstrate the high accuracy of the proposed system.
Robust Single Image Dehazing Based on Consistent and Contrast-Assisted Reconstruction
Mar 29, 2022
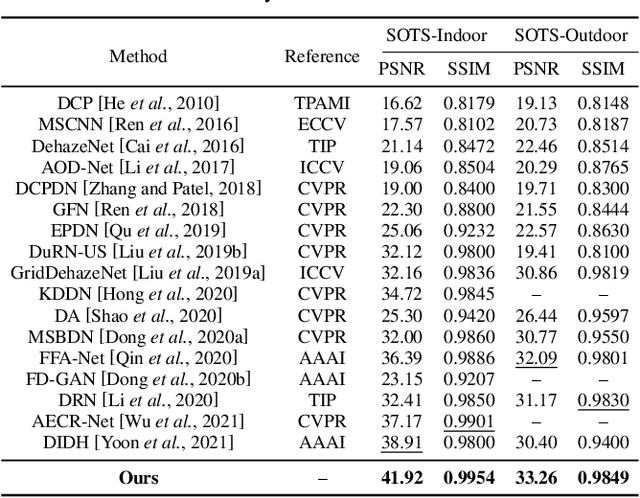
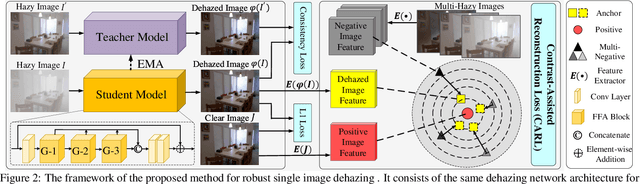

Single image dehazing as a fundamental low-level vision task, is essential for the development of robust intelligent surveillance system. In this paper, we make an early effort to consider dehazing robustness under variational haze density, which is a realistic while under-studied problem in the research filed of singe image dehazing. To properly address this problem, we propose a novel density-variational learning framework to improve the robustness of the image dehzing model assisted by a variety of negative hazy images, to better deal with various complex hazy scenarios. Specifically, the dehazing network is optimized under the consistency-regularized framework with the proposed Contrast-Assisted Reconstruction Loss (CARL). The CARL can fully exploit the negative information to facilitate the traditional positive-orient dehazing objective function, by squeezing the dehazed image to its clean target from different directions. Meanwhile, the consistency regularization keeps consistent outputs given multi-level hazy images, thus improving the model robustness. Extensive experimental results on two synthetic and three real-world datasets demonstrate that our method significantly surpasses the state-of-the-art approaches.