 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORMOT: A Dataset and Framework for Omnidirectional Referring Multi-Object Tracking
Mar 05, 2026Multi-Object Tracking (MOT) is a fundamental task in computer vision, aiming to track targets across video frames. Existing MOT methods perform well in general visual scenes, but face significant challenges and limitations when extended to visual-language settings. To bridge this gap, the task of Referring Multi-Object Tracking (RMOT) has recently been proposed, which aims to track objects that correspond to language descriptions. However, current RMOT methods are primarily developed on datasets captured by conventional cameras, which suffer from limited field of view. This constraint often causes targets to move out of the frame, leading to fragmented tracking and loss of contextual information. In this work, we propose a novel task, called Omnidirectional Referring Multi-Object Tracking (ORMOT), which extends RMOT to omnidirectional imagery, aiming to overcome the field-of-view (FoV) limitation of conventional datasets and improve the model's ability to understand long-horizon language descriptions. To advance the ORMOT task, we construct ORSet, an Omnidirectional Referring Multi-Object Tracking dataset, which contains 27 diverse omnidirectional scenes, 848 language descriptions, and 3,401 annotated objects, providing rich visual, temporal, and language information. Furthermore, we propose ORTrack, a Large Vision-Language Model (LVLM)-driven framework tailored for Omnidirectional Referring Multi-Object Tracking. Extensive experiments on the ORSet dataset demonstrate the effectiveness of our ORTrack framework. The dataset and code will be open-sourced at https://github.com/chen-si-jia/ORMOT.
RT-RMOT: A Dataset and Framework for RGB-Thermal Referring Multi-Object Tracking
Feb 25, 2026Referring Multi-Object Tracking has attracted increasing attention due to its human-friendly interactive characteristics, yet it exhibits limitations in low-visibility conditions, such as nighttime, smoke, and other challenging scenarios. To overcome this limitation, we propose a new RGB-Thermal RMOT task, named RT-RMOT, which aims to fuse RGB appearance features with the illumination robustness of the thermal modality to enable all-day referring multi-object tracking. To promote research on RT-RMOT, we construct the first Referring Multi-Object Tracking dataset under RGB-Thermal modality, named RefRT. It contains 388 language descriptions, 1,250 tracked targets, and 166,147 Language-RGB-Thermal (L-RGB-T) triplets. Furthermore, we propose RTrack, a framework built upon a multimodal large language model (MLLM) that integrates RGB, thermal, and textual features. Since the initial framework still leaves room for improvement, we introduce a Group Sequence Policy Optimization (GSPO) strategy to further exploit the model's potential. To alleviate training instability during RL fine-tuning, we introduce a Clipped Advantage Scaling (CAS) strategy to suppress gradient explosion. In addition, we design Structured Output Reward and Comprehensive Detection Reward to balance exploration and exploitation, thereby improving the completeness and accuracy of target perception. Extensive experiments on the RefRT dataset demonstrate the effectiveness of the proposed RTrack framework.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
VGAS: Value-Guided Action-Chunk Selection for Few-Shot Vision-Language-Action Adaptation
Feb 07, 2026Vision--Language--Action (VLA) models bridge multimodal reasoning with physical control, but adapting them to new tasks with scarce demonstrations remains unreliable. While fine-tuned VLA policies often produce semantically plausible trajectories, failures often arise from unresolved geometric ambiguities, where near-miss action candidates lead to divergent execution outcomes under limited supervision. We study few-shot VLA adaptation from a \emph{generation--selection} perspective and propose a novel framework \textbf{VGAS} (\textbf{V}alue-\textbf{G}uided \textbf{A}ction-chunk \textbf{S}election). It performs inference-time best-of-$N$ selection to identify action chunks that are both semantically faithful and geometrically precise. Specifically, \textbf{VGAS} employs a finetuned VLA as a high-recall proposal generator and introduces the \textrm{Q-Chunk-Former}, a geometrically grounded Transformer critic to resolve fine-grained geometric ambiguities. In addition, we propose \textit{Explicit Geometric Regularization} (\texttt{EGR}), which explicitly shapes a discriminative value landscape to preserve action ranking resolution among near-miss candidates while mitigating value instability under scarce supervision. Experiments and theoretical analysis demonstrate that \textbf{VGAS} consistently improves success rates and robustness under limited demonstrations and distribution shifts. Our code is available at https://github.com/Jyugo-15/VGAS.
DRMOT: A Dataset and Framework for RGBD Referring Multi-Object Tracking
Feb 04, 2026Referring Multi-Object Tracking (RMOT) aims to track specific targets based on language descriptions and is vital for interactive AI systems such as robotics and autonomous driving. However, existing RMOT models rely solely on 2D RGB data, making it challenging to accurately detect and associate targets characterized by complex spatial semantics (e.g., ``the person closest to the camera'') and to maintain reliable identities under severe occlusion, due to the absence of explicit 3D spatial information. In this work, we propose a novel task, RGBD Referring Multi-Object Tracking (DRMOT), which explicitly requires models to fuse RGB, Depth (D), and Language (L) modalities to achieve 3D-aware tracking. To advance research on the DRMOT task, we construct a tailored RGBD referring multi-object tracking dataset, named DRSet, designed to evaluate models' spatial-semantic grounding and tracking capabilities. Specifically, DRSet contains RGB images and depth maps from 187 scenes, along with 240 language descriptions, among which 56 descriptions incorporate depth-related information. Furthermore, we propose DRTrack, a MLLM-guided depth-referring tracking framework. DRTrack performs depth-aware target grounding from joint RGB-D-L inputs and enforces robust trajectory association by incorporating depth cues. Extensive experiments on the DRSet dataset demonstrate the effectiveness of our framework.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Bandwidth-constrained Variational Message Encoding for Cooperative Multi-agent Reinforcement Learning
Dec 11, 2025Graph-based multi-agent reinforcement learning (MARL) enables coordinated behavior under partial observability by modeling agents as nodes and communication links as edges. While recent methods excel at learning sparse coordination graphs-determining who communicates with whom-they do not address what information should be transmitted under hard bandwidth constraints. We study this bandwidth-limited regime and show that naive dimensionality reduction consistently degrades coordination performance. Hard bandwidth constraints force selective encoding, but deterministic projections lack mechanisms to control how compression occurs. We introduce Bandwidth-constrained Variational Message Encoding (BVME), a lightweight module that treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior. BVME's variational framework provides principled, tunable control over compression strength through interpretable hyperparameters, directly constraining the representations used for decision-making. Across SMACv1, SMACv2, and MPE benchmarks, BVME achieves comparable or superior performance while using 67--83% fewer message dimensions, with gains most pronounced on sparse graphs where message quality critically impacts coordination. Ablations reveal U-shaped sensitivity to bandwidth, with BVME excelling at extreme ratios while adding minimal overhead.
Autonomous Concept Drift Threshold Determination
Nov 13, 2025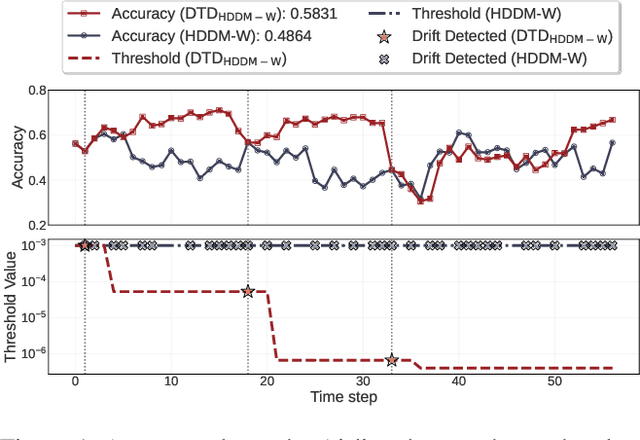
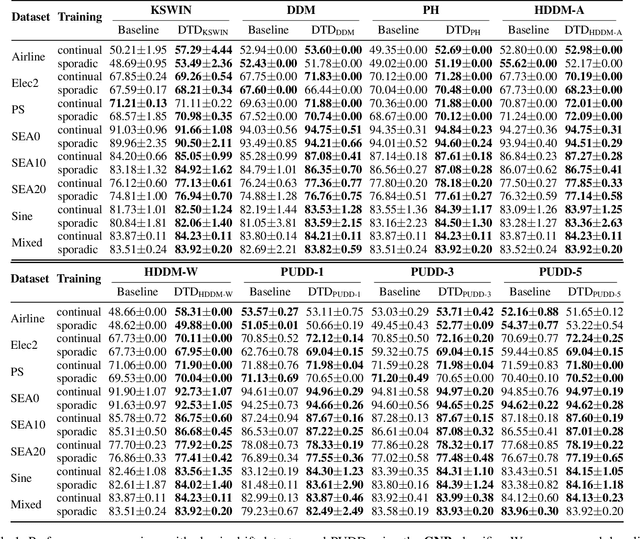
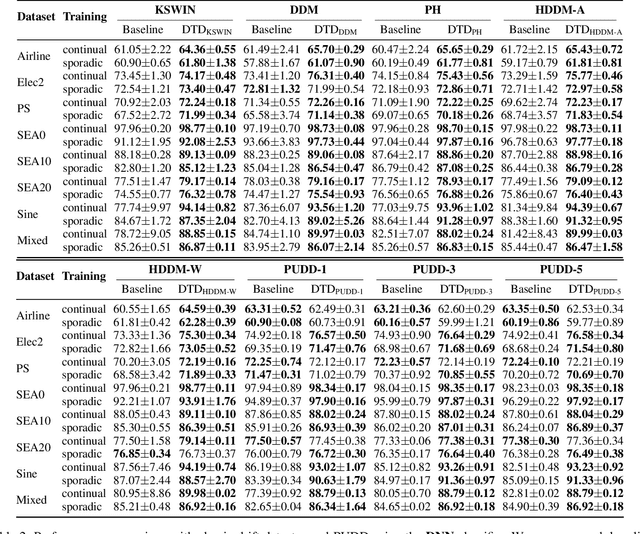
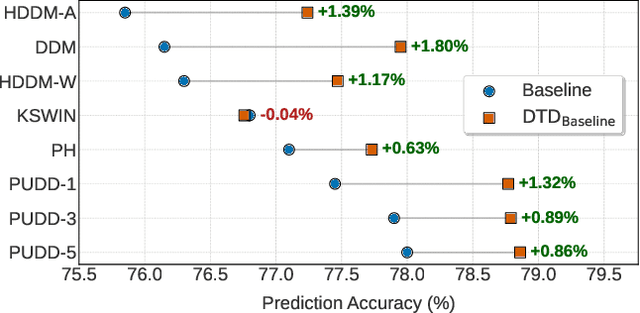
Existing drift detection methods focus on designing sensitive test statistics. They treat the detection threshold as a fixed hyperparameter, set once to balance false alarms and late detections, and applied uniformly across all datasets and over time. However, maintaining model performance is the key objective from the perspective of machine learning, and we observe that model performance is highly sensitive to this threshold. This observation inspires us to investigate whether a dynamic threshold could be provably better. In this paper, we prove that a threshold that adapts over time can outperform any single fixed threshold. The main idea of the proof is that a dynamic strategy, constructed by combining the best threshold from each individual data segment, is guaranteed to outperform any single threshold that apply to all segments. Based on the theorem, we propose a Dynamic Threshold Determination algorithm. It enhances existing drift detection frameworks with a novel comparison phase to inform how the threshold should be adjusted. Extensive experiments on a wide range of synthetic and real-world datasets, including both image and tabular data, validate that our approach substantially enhances the performance of state-of-the-art drift detectors.
Generalized Incremental Learning under Concept Drift across Evolving Data Streams
Jun 06, 2025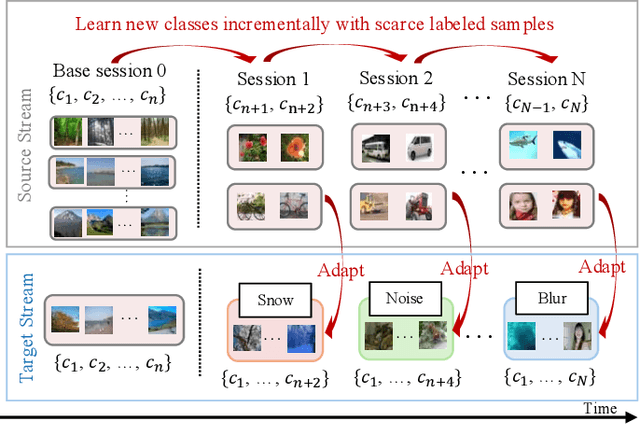
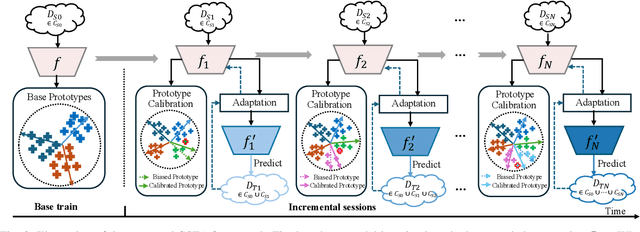
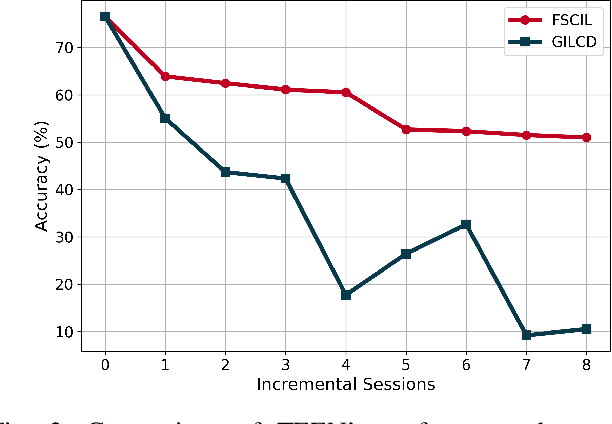
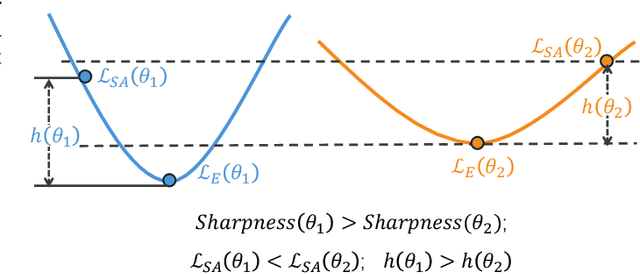
Real-world data streams exhibit inherent non-stationarity characterized by concept drift, posing significant challenges for adaptive learning systems. While existing methods address isolated distribution shifts, they overlook the critical co-evolution of label spaces and distributions under limited supervision and persistent uncertainty. To address this, we formalize Generalized Incremental Learning under Concept Drift (GILCD), characterizing the joint evolution of distributions and label spaces in open-environment streaming contexts, and propose a novel framework called Calibrated Source-Free Adaptation (CSFA). First, CSFA introduces a training-free prototype calibration mechanism that dynamically fuses emerging prototypes with base representations, enabling stable new-class identification without optimization overhead. Second, we design a novel source-free adaptation algorithm, i.e., Reliable Surrogate Gap Sharpness-aware (RSGS) minimization. It integrates sharpness-aware perturbation loss optimization with surrogate gap minimization, while employing entropy-based uncertainty filtering to discard unreliable samples. This mechanism ensures robust distribution alignment and mitigates generalization degradation caused by uncertainties. Therefore, CSFA establishes a unified framework for stable adaptation to evolving semantics and distributions in open-world streaming scenarios. Extensive experiments validate the superior performance and effectiveness of CSFA compared to state-of-the-art approaches.
ReaMOT: A Benchmark and Framework for Reasoning-based Multi-Object Tracking
May 26, 2025



Referring Multi-object tracking (RMOT) is an important research field in computer vision. Its task form is to guide the models to track the objects that conform to the language instruction. However, the RMOT task commonly requires clear language instructions, such methods often fail to work when complex language instructions with reasoning characteristics appear. In this work, we propose a new task, called Reasoning-based Multi-Object Tracking (ReaMOT). ReaMOT is a more challenging task that requires accurate reasoning about objects that match the language instruction with reasoning characteristic and tracking the objects' trajectories. To advance the ReaMOT task and evaluate the reasoning capabilities of tracking models, we construct ReaMOT Challenge, a reasoning-based multi-object tracking benchmark built upon 12 datasets. Specifically, it comprises 1,156 language instructions with reasoning characteristic, 423,359 image-language pairs, and 869 diverse scenes, which is divided into three levels of reasoning difficulty. In addition, we propose a set of evaluation metrics tailored for the ReaMOT task. Furthermore, we propose ReaTrack, a training-free framework for reasoning-based multi-object tracking based on large vision-language models (LVLM) and SAM2, as a baseline for the ReaMOT task. Extensive experiments on the ReaMOT Challenge benchmark demonstrate the effectiveness of our ReaTrack framework.