 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectionPlanner: Self-Correction Planner with Reinforcement Learning in Autonomous Driving
Mar 16, 2026Autonomous driving requires safe planning, but most learning-based planners lack explicit self-correction ability: once an unsafe action is proposed, there is no mechanism to correct it. Thus, we propose CorrectionPlanner, an autoregressive planner with self-correction that models planning as motion-token generation within a propose, evaluate, and correct loop. At each planning step, the policy proposes an action, namely a motion token, and a learned collision critic predicts whether it will induce a collision within a short horizon. If the critic predicts a collision, we retain the sequence of historical unsafe motion tokens as a self-correction trace, generate the next motion token conditioned on it, and repeat this process until a safe motion token is proposed or the safety criterion is met. This self-correction trace, consisting of all unsafe motion tokens, represents the planner's correction process in motion-token space, analogous to a reasoning trace in language models. We train the planner with imitation learning followed by model-based reinforcement learning using rollouts from a pretrained world model that realistically models agents' reactive behaviors. Closed-loop evaluations show that CorrectionPlanner reduces collision rate by over 20% on Waymax and achieves state-of-the-art planning scores on nuPlan.
ORMOT: A Dataset and Framework for Omnidirectional Referring Multi-Object Tracking
Mar 05, 2026Multi-Object Tracking (MOT) is a fundamental task in computer vision, aiming to track targets across video frames. Existing MOT methods perform well in general visual scenes, but face significant challenges and limitations when extended to visual-language settings. To bridge this gap, the task of Referring Multi-Object Tracking (RMOT) has recently been proposed, which aims to track objects that correspond to language descriptions. However, current RMOT methods are primarily developed on datasets captured by conventional cameras, which suffer from limited field of view. This constraint often causes targets to move out of the frame, leading to fragmented tracking and loss of contextual information. In this work, we propose a novel task, called Omnidirectional Referring Multi-Object Tracking (ORMOT), which extends RMOT to omnidirectional imagery, aiming to overcome the field-of-view (FoV) limitation of conventional datasets and improve the model's ability to understand long-horizon language descriptions. To advance the ORMOT task, we construct ORSet, an Omnidirectional Referring Multi-Object Tracking dataset, which contains 27 diverse omnidirectional scenes, 848 language descriptions, and 3,401 annotated objects, providing rich visual, temporal, and language information. Furthermore, we propose ORTrack, a Large Vision-Language Model (LVLM)-driven framework tailored for Omnidirectional Referring Multi-Object Tracking. Extensive experiments on the ORSet dataset demonstrate the effectiveness of our ORTrack framework. The dataset and code will be open-sourced at https://github.com/chen-si-jia/ORMOT.
RT-RMOT: A Dataset and Framework for RGB-Thermal Referring Multi-Object Tracking
Feb 25, 2026Referring Multi-Object Tracking has attracted increasing attention due to its human-friendly interactive characteristics, yet it exhibits limitations in low-visibility conditions, such as nighttime, smoke, and other challenging scenarios. To overcome this limitation, we propose a new RGB-Thermal RMOT task, named RT-RMOT, which aims to fuse RGB appearance features with the illumination robustness of the thermal modality to enable all-day referring multi-object tracking. To promote research on RT-RMOT, we construct the first Referring Multi-Object Tracking dataset under RGB-Thermal modality, named RefRT. It contains 388 language descriptions, 1,250 tracked targets, and 166,147 Language-RGB-Thermal (L-RGB-T) triplets. Furthermore, we propose RTrack, a framework built upon a multimodal large language model (MLLM) that integrates RGB, thermal, and textual features. Since the initial framework still leaves room for improvement, we introduce a Group Sequence Policy Optimization (GSPO) strategy to further exploit the model's potential. To alleviate training instability during RL fine-tuning, we introduce a Clipped Advantage Scaling (CAS) strategy to suppress gradient explosion. In addition, we design Structured Output Reward and Comprehensive Detection Reward to balance exploration and exploitation, thereby improving the completeness and accuracy of target perception. Extensive experiments on the RefRT dataset demonstrate the effectiveness of the proposed RTrack framework.
DRMOT: A Dataset and Framework for RGBD Referring Multi-Object Tracking
Feb 04, 2026Referring Multi-Object Tracking (RMOT) aims to track specific targets based on language descriptions and is vital for interactive AI systems such as robotics and autonomous driving. However, existing RMOT models rely solely on 2D RGB data, making it challenging to accurately detect and associate targets characterized by complex spatial semantics (e.g., ``the person closest to the camera'') and to maintain reliable identities under severe occlusion, due to the absence of explicit 3D spatial information. In this work, we propose a novel task, RGBD Referring Multi-Object Tracking (DRMOT), which explicitly requires models to fuse RGB, Depth (D), and Language (L) modalities to achieve 3D-aware tracking. To advance research on the DRMOT task, we construct a tailored RGBD referring multi-object tracking dataset, named DRSet, designed to evaluate models' spatial-semantic grounding and tracking capabilities. Specifically, DRSet contains RGB images and depth maps from 187 scenes, along with 240 language descriptions, among which 56 descriptions incorporate depth-related information. Furthermore, we propose DRTrack, a MLLM-guided depth-referring tracking framework. DRTrack performs depth-aware target grounding from joint RGB-D-L inputs and enforces robust trajectory association by incorporating depth cues. Extensive experiments on the DRSet dataset demonstrate the effectiveness of our framework.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
iCLP: Large Language Model Reasoning with Implicit Cognition Latent Planning
Dec 30, 2025Large language models (LLMs), when guided by explicit textual plans, can perform reliable step-by-step reasoning during problem-solving. However, generating accurate and effective textual plans remains challenging due to LLM hallucinations and the high diversity of task-specific questions. To address this, we draw inspiration from human Implicit Cognition (IC), the subconscious process by which decisions are guided by compact, generalized patterns learned from past experiences without requiring explicit verbalization. We propose iCLP, a novel framework that enables LLMs to adaptively generate latent plans (LPs), which are compact encodings of effective reasoning instructions. iCLP first distills explicit plans from existing step-by-step reasoning trajectories. It then learns discrete representations of these plans via a vector-quantized autoencoder coupled with a codebook. Finally, by fine-tuning LLMs on paired latent plans and corresponding reasoning steps, the models learn to perform implicit planning during reasoning. Experimental results on mathematical reasoning and code generation tasks demonstrate that, with iCLP, LLMs can plan in latent space while reasoning in language space. This approach yields significant improvements in both accuracy and efficiency and, crucially, demonstrates strong cross-domain generalization while preserving the interpretability of chain-of-thought reasoning.
A2VISR: An Active and Adaptive Ground-Aerial Localization System Using Visual Inertial and Single-Range Fusion
Dec 18, 2025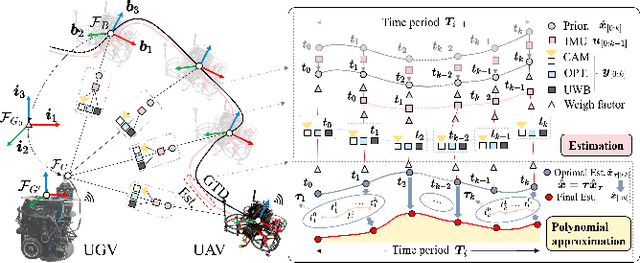


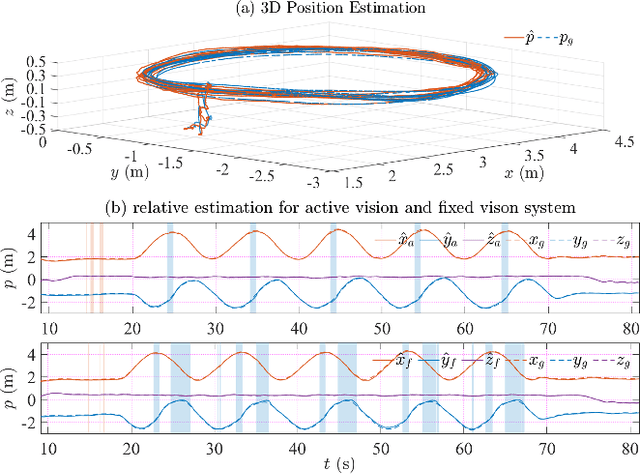
It's a practical approach using the ground-aerial collaborative system to enhance the localization robustness of flying robots in cluttered environments, especially when visual sensors degrade. Conventional approaches estimate the flying robot's position using fixed cameras observing pre-attached markers, which could be constrained by limited distance and susceptible to capture failure. To address this issue, we improve the ground-aerial localization framework in a more comprehensive manner, which integrates active vision, single-ranging, inertial odometry, and optical flow. First, the designed active vision subsystem mounted on the ground vehicle can be dynamically rotated to detect and track infrared markers on the aerial robot, improving the field of view and the target recognition with a single camera. Meanwhile, the incorporation of single-ranging extends the feasible distance and enhances re-capture capability under visual degradation. During estimation, a dimension-reduced estimator fuses multi-source measurements based on polynomial approximation with an extended sliding window, balancing computational efficiency and redundancy. Considering different sensor fidelities, an adaptive sliding confidence evaluation algorithm is implemented to assess measurement quality and dynamically adjust the weighting parameters based on moving variance. Finally, extensive experiments under conditions such as smoke interference, illumination variation, obstacle occlusion, prolonged visual loss, and extended operating range demonstrate that the proposed approach achieves robust online localization, with an average root mean square error of approximately 0.09 m, while maintaining resilience to capture loss and sensor failures.
PyFi: Toward Pyramid-like Financial Image Understanding for VLMs via Adversarial Agents
Dec 11, 2025This paper proposes PyFi, a novel framework for pyramid-like financial image understanding that enables vision language models (VLMs) to reason through question chains in a progressive, simple-to-complex manner. At the core of PyFi is PyFi-600K, a dataset comprising 600K financial question-answer pairs organized into a reasoning pyramid: questions at the base require only basic perception, while those toward the apex demand increasing levels of capability in financial visual understanding and expertise. This data is scalable because it is synthesized without human annotations, using PyFi-adv, a multi-agent adversarial mechanism under the Monte Carlo Tree Search (MCTS) paradigm, in which, for each image, a challenger agent competes with a solver agent by generating question chains that progressively probe deeper capability levels in financial visual reasoning. Leveraging this dataset, we present fine-grained, hierarchical, and comprehensive evaluations of advanced VLMs in the financial domain. Moreover, fine-tuning Qwen2.5-VL-3B and Qwen2.5-VL-7B on the pyramid-structured question chains enables these models to answer complex financial questions by decomposing them into sub-questions with gradually increasing reasoning demands, yielding average accuracy improvements of 19.52% and 8.06%, respectively, on the dataset. All resources of code, dataset and models are available at: https://github.com/AgenticFinLab/PyFi .
rSIM: Incentivizing Reasoning Capabilities of LLMs via Reinforced Strategy Injection
Dec 09, 2025Large language models (LLMs) are post-trained through reinforcement learning (RL) to evolve into Reasoning Language Models (RLMs), where the hallmark of this advanced reasoning is ``aha'' moments when they start to perform strategies, such as self-reflection and deep thinking, within chain of thoughts (CoTs). Motivated by this, this paper proposes a novel reinforced strategy injection mechanism (rSIM), that enables any LLM to become an RLM by employing a small planner to guide the LLM's CoT through the adaptive injection of reasoning strategies. To achieve this, the planner (leader agent) is jointly trained with an LLM (follower agent) using multi-agent RL (MARL), based on a leader-follower framework and straightforward rule-based rewards. Experimental results show that rSIM enables Qwen2.5-0.5B to become an RLM and significantly outperform Qwen2.5-14B. Moreover, the planner is generalizable: it only needs to be trained once and can be applied as a plug-in to substantially improve the reasoning capabilities of existing LLMs. In addition, the planner supports continual learning across various tasks, allowing its planning abilities to gradually improve and generalize to a wider range of problems.
Fast and Simplex: 2-Simplicial Attention in Triton
Jul 03, 2025Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.