 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Manipulation: Token-Space Attacks on Reward Models
Apr 03, 2026Reward models (RMs) are widely used as optimization targets in reinforcement learning from human feedback (RLHF), yet they remain vulnerable to reward hacking. Existing attacks mainly operate within the semantic space, constructing human-readable adversarial outputs that exploit RM biases. In this work, we introduce a fundamentally different paradigm: Token Mapping Perturbation Attack (TOMPA), a framework that performs adversarial optimization directly in token space. By bypassing the standard decode-re-tokenize interface between the policy and the reward model, TOMPA enables the attack policy to optimize over raw token sequences rather than coherent natural language. Using only black-box scalar feedback, TOMPA automatically discovers non-linguistic token patterns that elicit extremely high rewards across multiple state-of-the-art RMs. Specifically, when targeting Skywork-Reward-V2-Llama-3.1-8B, TOMPA nearly doubles the reward of GPT-5 reference answers and outperforms them on 98.0% of prompts. Despite these high scores, the generated outputs degenerate into nonsensical text, revealing that RMs can be systematically exploited beyond the semantic regime and exposing a critical vulnerability in current RLHF pipelines.
Error Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
CARES: Comprehensive Evaluation of Safety and Adversarial Robustness in Medical LLMs
May 16, 2025Large language models (LLMs) are increasingly deployed in medical contexts, raising critical concerns about safety, alignment, and susceptibility to adversarial manipulation. While prior benchmarks assess model refusal capabilities for harmful prompts, they often lack clinical specificity, graded harmfulness levels, and coverage of jailbreak-style attacks. We introduce CARES (Clinical Adversarial Robustness and Evaluation of Safety), a benchmark for evaluating LLM safety in healthcare. CARES includes over 18,000 prompts spanning eight medical safety principles, four harm levels, and four prompting styles: direct, indirect, obfuscated, and role-play, to simulate both malicious and benign use cases. We propose a three-way response evaluation protocol (Accept, Caution, Refuse) and a fine-grained Safety Score metric to assess model behavior. Our analysis reveals that many state-of-the-art LLMs remain vulnerable to jailbreaks that subtly rephrase harmful prompts, while also over-refusing safe but atypically phrased queries. Finally, we propose a mitigation strategy using a lightweight classifier to detect jailbreak attempts and steer models toward safer behavior via reminder-based conditioning. CARES provides a rigorous framework for testing and improving medical LLM safety under adversarial and ambiguous conditions.
Modeling and Analyzing Scorer Preferences in Short-Answer Math Questions
Jun 01, 2023Automated scoring of student responses to open-ended questions, including short-answer questions, has great potential to scale to a large number of responses. Recent approaches for automated scoring rely on supervised learning, i.e., training classifiers or fine-tuning language models on a small number of responses with human-provided score labels. However, since scoring is a subjective process, these human scores are noisy and can be highly variable, depending on the scorer. In this paper, we investigate a collection of models that account for the individual preferences and tendencies of each human scorer in the automated scoring task. We apply these models to a short-answer math response dataset where each response is scored (often differently) by multiple different human scorers. We conduct quantitative experiments to show that our scorer models lead to improved automated scoring accuracy. We also conduct quantitative experiments and case studies to analyze the individual preferences and tendencies of scorers. We found that scorers can be grouped into several obvious clusters, with each cluster having distinct features, and analyzed them in detail.
Interpretable Math Word Problem Solution Generation Via Step-by-step Planning
Jun 01, 2023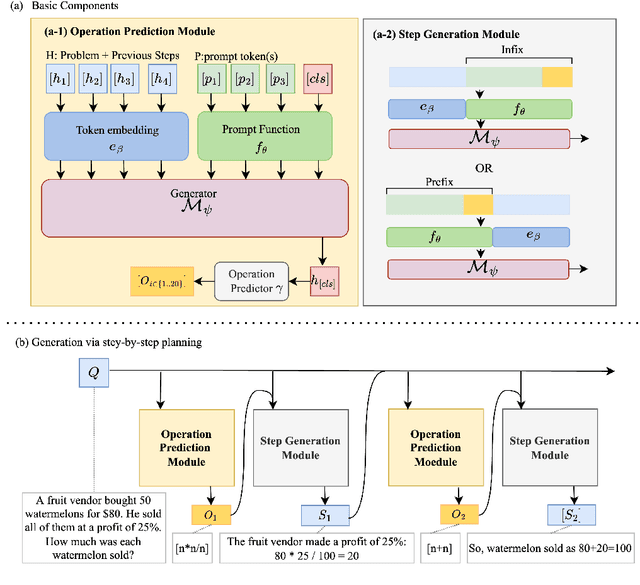
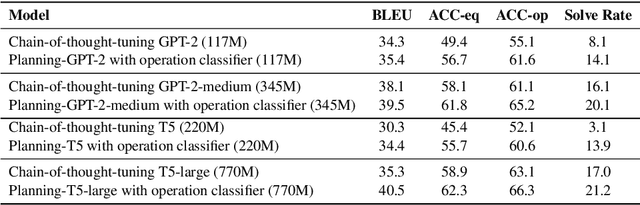
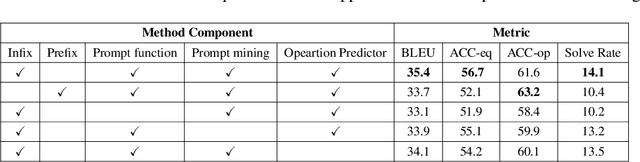
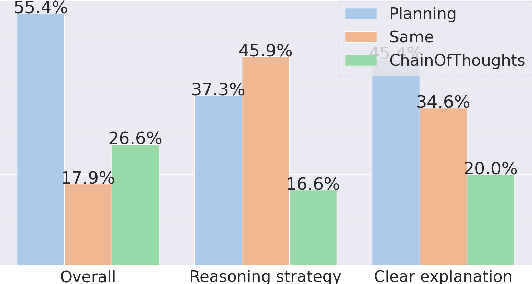
Solutions to math word problems (MWPs) with step-by-step explanations are valuable, especially in education, to help students better comprehend problem-solving strategies. Most existing approaches only focus on obtaining the final correct answer. A few recent approaches leverage intermediate solution steps to improve final answer correctness but often cannot generate coherent steps with a clear solution strategy. Contrary to existing work, we focus on improving the correctness and coherence of the intermediate solutions steps. We propose a step-by-step planning approach for intermediate solution generation, which strategically plans the generation of the next solution step based on the MWP and the previous solution steps. Our approach first plans the next step by predicting the necessary math operation needed to proceed, given history steps, then generates the next step, token-by-token, by prompting a language model with the predicted math operation. Experiments on the GSM8K dataset demonstrate that our approach improves the accuracy and interpretability of the solution on both automatic metrics and human evaluation.
Algebra Error Classification with Large Language Models
May 08, 2023



Automated feedback as students answer open-ended math questions has significant potential in improving learning outcomes at large scale. A key part of automated feedback systems is an error classification component, which identifies student errors and enables appropriate, predefined feedback to be deployed. Most existing approaches to error classification use a rule-based method, which has limited capacity to generalize. Existing data-driven methods avoid these limitations but specifically require mathematical expressions in student responses to be parsed into syntax trees. This requirement is itself a limitation, since student responses are not always syntactically valid and cannot be converted into trees. In this work, we introduce a flexible method for error classification using pre-trained large language models. We demonstrate that our method can outperform existing methods in algebra error classification, and is able to classify a larger set of student responses. Additionally, we analyze common classification errors made by our method and discuss limitations of automated error classification.
Automatic Short Math Answer Grading via In-context Meta-learning
May 30, 2022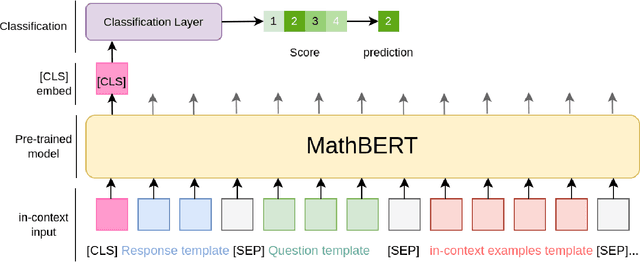


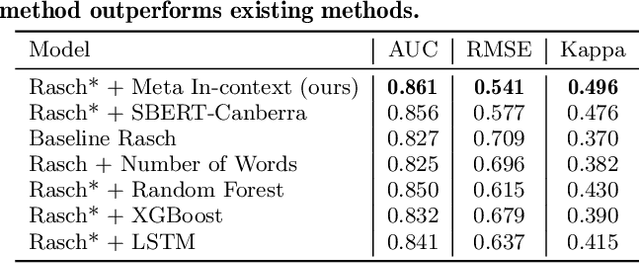
Automatic short answer grading is an important research direction in the exploration of how to use artificial intelligence (AI)-based tools to improve education. Current state-of-the-art approaches use neural language models to create vectorized representations of students responses, followed by classifiers to predict the score. However, these approaches have several key limitations, including i) they use pre-trained language models that are not well-adapted to educational subject domains and/or student-generated text and ii) they almost always train one model per question, ignoring the linkage across a question and result in a significant model storage problem due to the size of advanced language models. In this paper, we study the problem of automatic short answer grading for students' responses to math questions and propose a novel framework for this task. First, we use MathBERT, a variant of the popular language model BERT adapted to mathematical content, as our base model and fine-tune it for the downstream task of student response grading. Second, we use an in-context learning approach that provides scoring examples as input to the language model to provide additional context information and promote generalization to previously unseen questions. We evaluate our framework on a real-world dataset of student responses to open-ended math questions and show that our framework (often significantly) outperforms existing approaches, especially for new questions that are not seen during training.
Math Operation Embeddings for Open-ended Solution Analysis and Feedback
Apr 25, 2021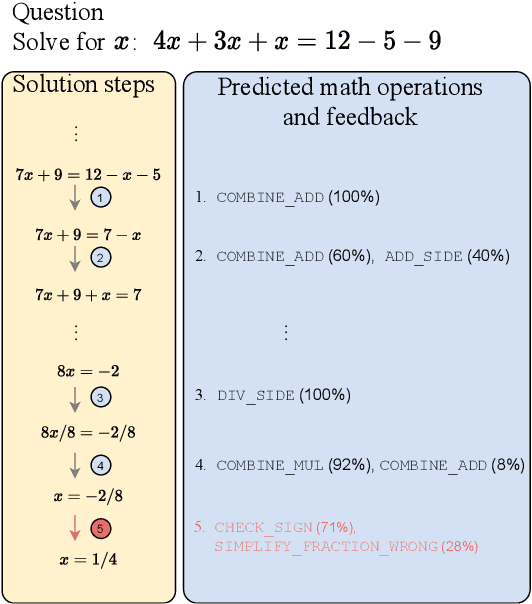


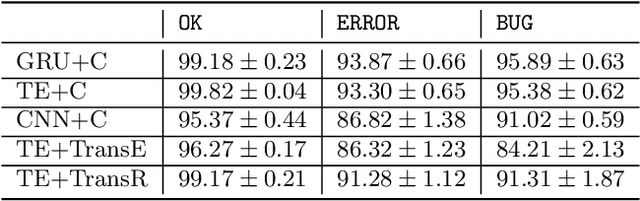
Feedback on student answers and even during intermediate steps in their solutions to open-ended questions is an important element in math education. Such feedback can help students correct their errors and ultimately lead to improved learning outcomes. Most existing approaches for automated student solution analysis and feedback require manually constructing cognitive models and anticipating student errors for each question. This process requires significant human effort and does not scale to most questions used in homework and practices that do not come with this information. In this paper, we analyze students' step-by-step solution processes to equation solving questions in an attempt to scale up error diagnostics and feedback mechanisms developed for a small number of questions to a much larger number of questions. Leveraging a recent math expression encoding method, we represent each math operation applied in solution steps as a transition in the math embedding vector space. We use a dataset that contains student solution steps in the Cognitive Tutor system to learn implicit and explicit representations of math operations. We explore whether these representations can i) identify math operations a student intends to perform in each solution step, regardless of whether they did it correctly or not, and ii) select the appropriate feedback type for incorrect steps. Experimental results show that our learned math operation representations generalize well across different data distributions.
Evaluating the Performance of Reinforcement Learning Algorithms
Jun 30, 2020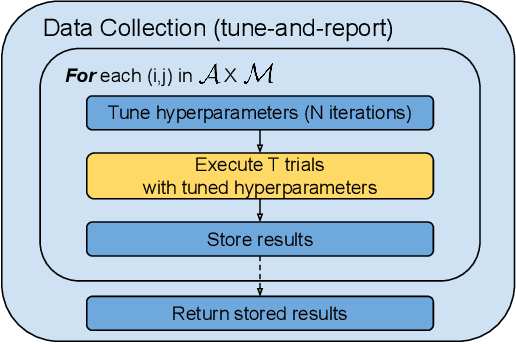
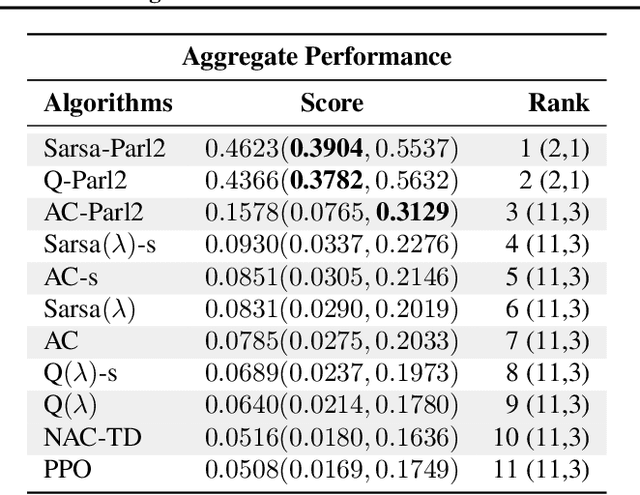
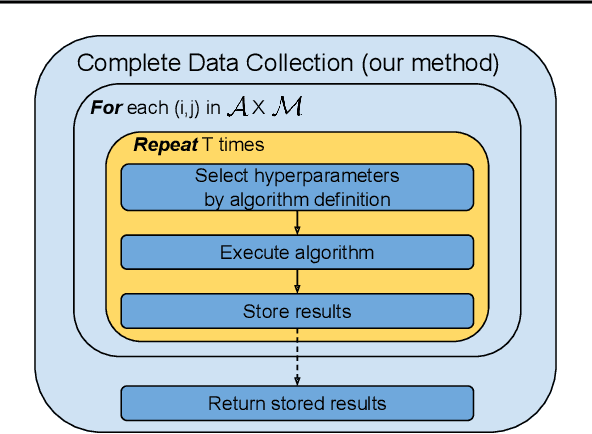
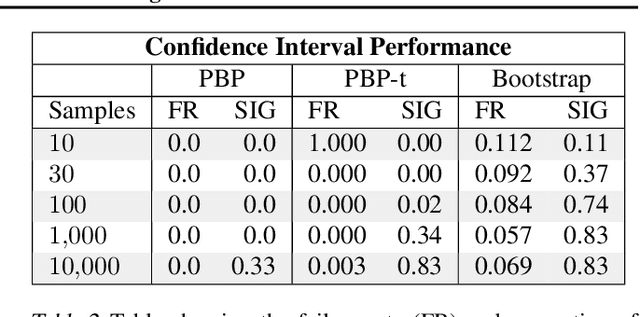
Performance evaluations are critical for quantifying algorithmic advances in reinforcement learning. Recent reproducibility analyses have shown that reported performance results are often inconsistent and difficult to replicate. In this work, we argue that the inconsistency of performance stems from the use of flawed evaluation metrics. Taking a step towards ensuring that reported results are consistent, we propose a new comprehensive evaluation methodology for reinforcement learning algorithms that produces reliable measurements of performance both on a single environment and when aggregated across environments. We demonstrate this method by evaluating a broad class of reinforcement learning algorithms on standard benchmark tasks.
Matching Questions and Answers in Dialogues from Online Forums
May 19, 2020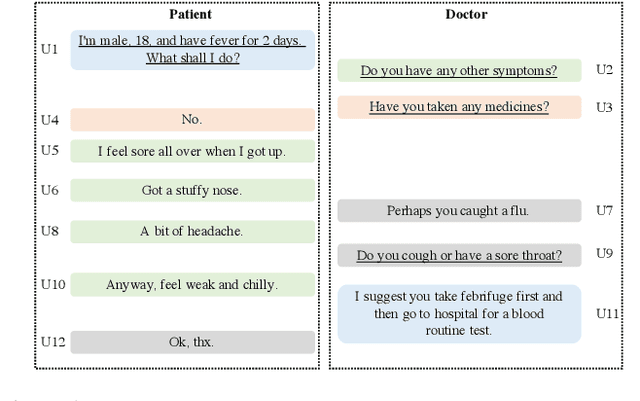

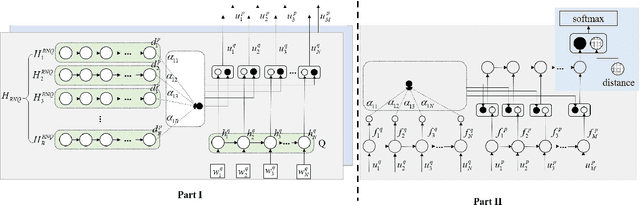

Matching question-answer relations between two turns in conversations is not only the first step in analyzing dialogue structures, but also valuable for training dialogue systems. This paper presents a QA matching model considering both distance information and dialogue history by two simultaneous attention mechanisms called mutual attention. Given scores computed by the trained model between each non-question turn with its candidate questions, a greedy matching strategy is used for final predictions. Because existing dialogue datasets such as the Ubuntu dataset are not suitable for the QA matching task, we further create a dataset with 1,000 labeled dialogues and demonstrate that our proposed model outperforms the state-of-the-art and other strong baselines, particularly for matching long-distance QA pairs.