 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe StudyChat Dataset: Student Dialogues With ChatGPT in an Artificial Intelligence Course
Mar 11, 2025


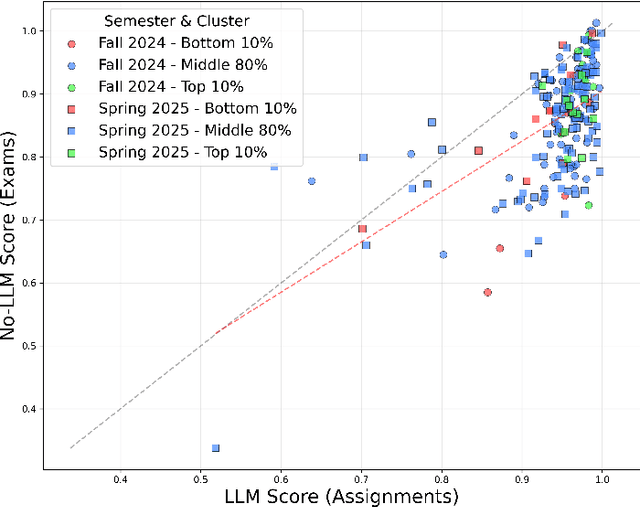
The widespread availability of large language models (LLMs), such as ChatGPT, has significantly impacted education, raising both opportunities and challenges. Students can frequently interact with LLM-powered, interactive learning tools, but their usage patterns need to be analyzed to ensure ethical usage of these tools. To better understand how students interact with LLMs in an academic setting, we introduce \textbf{StudyChat}, a publicly available dataset capturing real-world student interactions with an LLM-powered tutoring chatbot in a semester-long, university-level artificial intelligence (AI) course. We deploy a web application that replicates ChatGPT's core functionalities, and use it to log student interactions with the LLM while working on programming assignments. We collect 1,197 conversations, which we annotate using a dialogue act labeling schema inspired by observed interaction patterns and prior research. Additionally, we analyze these interactions, highlight behavioral trends, and analyze how specific usage patterns relate to course outcomes. \textbf{StudyChat} provides a rich resource for the learning sciences and AI in education communities, enabling further research into the evolving role of LLMs in education.
Exploring Automated Keyword Mnemonics Generation with Large Language Models via Overgenerate-and-Rank
Sep 21, 2024



In this paper, we study an under-explored area of language and vocabulary learning: keyword mnemonics, a technique for memorizing vocabulary through memorable associations with a target word via a verbal cue. Typically, creating verbal cues requires extensive human effort and is quite time-consuming, necessitating an automated method that is more scalable. We propose a novel overgenerate-and-rank method via prompting large language models (LLMs) to generate verbal cues and then ranking them according to psycholinguistic measures and takeaways from a pilot user study. To assess cue quality, we conduct both an automated evaluation of imageability and coherence, as well as a human evaluation involving English teachers and learners. Results show that LLM-generated mnemonics are comparable to human-generated ones in terms of imageability, coherence, and perceived usefulness, but there remains plenty of room for improvement due to the diversity in background and preference among language learners.
Can Large Language Models Replicate ITS Feedback on Open-Ended Math Questions?
May 10, 2024



Intelligent Tutoring Systems (ITSs) often contain an automated feedback component, which provides a predefined feedback message to students when they detect a predefined error. To such a feedback component, we often resort to template-based approaches. These approaches require significant effort from human experts to detect a limited number of possible student errors and provide corresponding feedback. This limitation is exemplified in open-ended math questions, where there can be a large number of different incorrect errors. In our work, we examine the capabilities of large language models (LLMs) to generate feedback for open-ended math questions, similar to that of an established ITS that uses a template-based approach. We fine-tune both open-source and proprietary LLMs on real student responses and corresponding ITS-provided feedback. We measure the quality of the generated feedback using text similarity metrics. We find that open-source and proprietary models both show promise in replicating the feedback they see during training, but do not generalize well to previously unseen student errors. These results suggest that despite being able to learn the formatting of feedback, LLMs are not able to fully understand mathematical errors made by students.
Exploring Automated Distractor Generation for Math Multiple-choice Questions via Large Language Models
Apr 05, 2024



Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in assessments and practices. One of the most important aspects of MCQs is the distractors, i.e., incorrect options that are designed to target common errors or misconceptions among real students. To date, the task of crafting high-quality distractors largely remains a labor and time-intensive process for teachers and learning content designers, which has limited scalability. In this work, we study the task of automated distractor generation in the domain of math MCQs and explore a wide variety of large language model (LLM)-based approaches, from in-context learning to fine-tuning. We conduct extensive experiments using a real-world math MCQ dataset and find that although LLMs can generate some mathematically valid distractors, they are less adept at anticipating common errors or misconceptions among real students.
Exploring Automated Distractor and Feedback Generation for Math Multiple-choice Questions via In-context Learning
Aug 07, 2023



Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in both assessments and practices. An important aspect of MCQs is the distractors, i.e., incorrect options that are designed to target specific misconceptions or insufficient knowledge among students. To date, the task of crafting high-quality distractors has largely remained a labor-intensive process for teachers and learning content designers, which has limited scalability. In this work, we explore the task of automated distractor and corresponding feedback message generation in math MCQs using large language models. We establish a formulation of these two tasks and propose a simple, in-context learning-based solution. Moreover, we explore using two non-standard metrics to evaluate the quality of the generated distractors and feedback messages. We conduct extensive experiments on these tasks using a real-world MCQ dataset that contains student response information. Our findings suggest that there is a lot of room for improvement in automated distractor and feedback generation. We also outline several directions for future work
A Conceptual Model for End-to-End Causal Discovery in Knowledge Tracing
May 11, 2023



In this paper, we take a preliminary step towards solving the problem of causal discovery in knowledge tracing, i.e., finding the underlying causal relationship among different skills from real-world student response data. This problem is important since it can potentially help us understand the causal relationship between different skills without extensive A/B testing, which can potentially help educators to design better curricula according to skill prerequisite information. Specifically, we propose a conceptual solution, a novel causal gated recurrent unit (GRU) module in a modified deep knowledge tracing model, which uses i) a learnable permutation matrix for causal ordering among skills and ii) an optionally learnable lower-triangular matrix for causal structure among skills. We also detail how to learn the model parameters in an end-to-end, differentiable way. Our solution placed among the top entries in Task 3 of the NeurIPS 2022 Challenge on Causal Insights for Learning Paths in Education. We detail preliminary experiments as evaluated on the challenge's public leaderboard since the ground truth causal structure has not been publicly released, making detailed local evaluation impossible.
Algebra Error Classification with Large Language Models
May 08, 2023



Automated feedback as students answer open-ended math questions has significant potential in improving learning outcomes at large scale. A key part of automated feedback systems is an error classification component, which identifies student errors and enables appropriate, predefined feedback to be deployed. Most existing approaches to error classification use a rule-based method, which has limited capacity to generalize. Existing data-driven methods avoid these limitations but specifically require mathematical expressions in student responses to be parsed into syntax trees. This requirement is itself a limitation, since student responses are not always syntactically valid and cannot be converted into trees. In this work, we introduce a flexible method for error classification using pre-trained large language models. We demonstrate that our method can outperform existing methods in algebra error classification, and is able to classify a larger set of student responses. Additionally, we analyze common classification errors made by our method and discuss limitations of automated error classification.