 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
Feb 02, 2026Timely and accurate identification of student misconceptions is key to improving learning outcomes and pre-empting the compounding of student errors. However, this task is highly dependent on the effort and intuition of the teacher. In this work, we present a novel approach for detecting misconceptions from student-tutor dialogues using large language models (LLMs). First, we use a fine-tuned LLM to generate plausible misconceptions, and then retrieve the most promising candidates among these using embedding similarity with the input dialogue. These candidates are then assessed and re-ranked by another fine-tuned LLM to improve misconception relevance. Empirically, we evaluate our system on real dialogues from an educational tutoring platform. We consider multiple base LLM models including LLaMA, Qwen and Claude on zero-shot and fine-tuned settings. We find that our approach improves predictive performance over baseline models and that fine-tuning improves both generated misconception quality and can outperform larger closed-source models. Finally, we conduct ablation studies to both validate the importance of our generation and reranking steps on misconception generation quality.
AI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Dec 29, 2025One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
PIIvot: A Lightweight NLP Anonymization Framework for Question-Anchored Tutoring Dialogues
May 22, 2025Personally identifiable information (PII) anonymization is a high-stakes task that poses a barrier to many open-science data sharing initiatives. While PII identification has made large strides in recent years, in practice, error thresholds and the recall/precision trade-off still limit the uptake of these anonymization pipelines. We present PIIvot, a lighter-weight framework for PII anonymization that leverages knowledge of the data context to simplify the PII detection problem. To demonstrate its effectiveness, we also contribute QATD-2k, the largest open-source real-world tutoring dataset of its kind, to support the demand for quality educational dialogue data.
Math Multiple Choice Question Generation via Human-Large Language Model Collaboration
May 01, 2024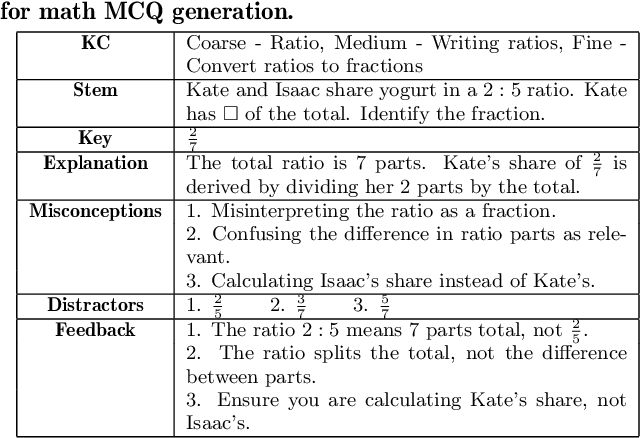

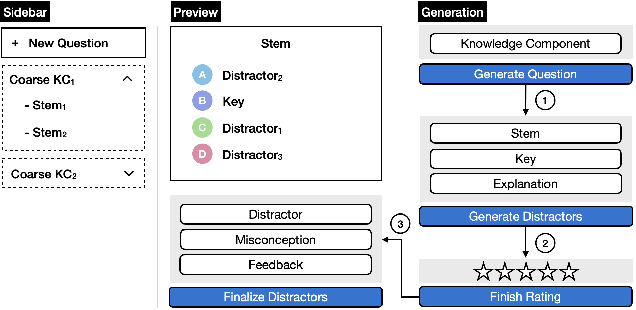

Multiple choice questions (MCQs) are a popular method for evaluating students' knowledge due to their efficiency in administration and grading. Crafting high-quality math MCQs is a labor-intensive process that requires educators to formulate precise stems and plausible distractors. Recent advances in large language models (LLMs) have sparked interest in automating MCQ creation, but challenges persist in ensuring mathematical accuracy and addressing student errors. This paper introduces a prototype tool designed to facilitate collaboration between LLMs and educators for streamlining the math MCQ generation process. We conduct a pilot study involving math educators to investigate how the tool can help them simplify the process of crafting high-quality math MCQs. We found that while LLMs can generate well-formulated question stems, their ability to generate distractors that capture common student errors and misconceptions is limited. Nevertheless, a human-AI collaboration has the potential to enhance the efficiency and effectiveness of MCQ generation.
Exploring Automated Distractor Generation for Math Multiple-choice Questions via Large Language Models
Apr 05, 2024



Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in assessments and practices. One of the most important aspects of MCQs is the distractors, i.e., incorrect options that are designed to target common errors or misconceptions among real students. To date, the task of crafting high-quality distractors largely remains a labor and time-intensive process for teachers and learning content designers, which has limited scalability. In this work, we study the task of automated distractor generation in the domain of math MCQs and explore a wide variety of large language model (LLM)-based approaches, from in-context learning to fine-tuning. We conduct extensive experiments using a real-world math MCQ dataset and find that although LLMs can generate some mathematically valid distractors, they are less adept at anticipating common errors or misconceptions among real students.
Improving the Validity of Automatically Generated Feedback via Reinforcement Learning
Mar 02, 2024Automatically generating feedback via large language models (LLMs) in intelligent tutoring systems and online learning platforms has the potential to improve the learning outcomes of many students. However, both feedback generation and evaluation are challenging: feedback content has to be valid especially in subjects like math, which requires models to understand the problem, the solution, and where the student's error lies. Feedback also has to be pedagogically valid to reflect effective tutoring strategies, such as explaining possible misconceptions and encouraging the student, among other desirable features. In this work, we address both problems of automatically generating and evaluating feedback while considering both correctness and alignment. First, we propose a rubric for evaluating math feedback and show that GPT-4 is able to effectively use it to annotate human-written and LLM-generated feedback. Second, we propose a framework for feedback generation that optimizes both correctness and alignment using reinforcement learning (RL). Specifically, we use GPT-4's annotations to create preferences over feedback pairs in an augmented dataset for training via direct preference optimization (DPO). We show that our methods significantly increase the correctness and alignment of generated feedback with Llama 2, an open-source LLM, qualitatively analyze our generation and evaluation systems using case studies, and outline several areas for future work.
Exploring Automated Distractor and Feedback Generation for Math Multiple-choice Questions via In-context Learning
Aug 07, 2023



Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in both assessments and practices. An important aspect of MCQs is the distractors, i.e., incorrect options that are designed to target specific misconceptions or insufficient knowledge among students. To date, the task of crafting high-quality distractors has largely remained a labor-intensive process for teachers and learning content designers, which has limited scalability. In this work, we explore the task of automated distractor and corresponding feedback message generation in math MCQs using large language models. We establish a formulation of these two tasks and propose a simple, in-context learning-based solution. Moreover, we explore using two non-standard metrics to evaluate the quality of the generated distractors and feedback messages. We conduct extensive experiments on these tasks using a real-world MCQ dataset that contains student response information. Our findings suggest that there is a lot of room for improvement in automated distractor and feedback generation. We also outline several directions for future work
NeurIPS Competition Instructions and Guide: Causal Insights for Learning Paths in Education
Aug 31, 2022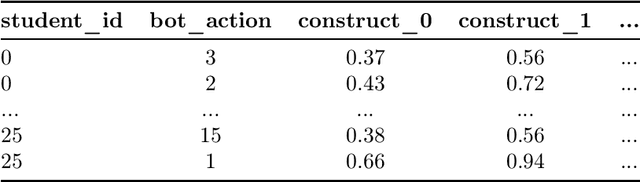
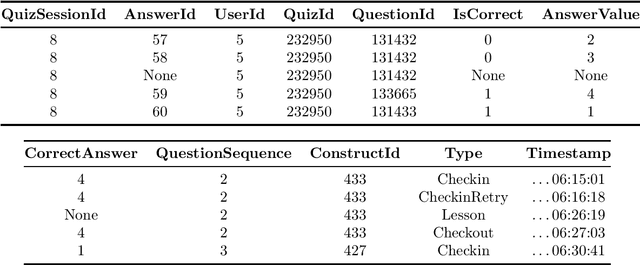

In this competition, participants will address two fundamental causal challenges in machine learning in the context of education using time-series data. The first is to identify the causal relationships between different constructs, where a construct is defined as the smallest element of learning. The second challenge is to predict the impact of learning one construct on the ability to answer questions on other constructs. Addressing these challenges will enable optimisation of students' knowledge acquisition, which can be deployed in a real edtech solution impacting millions of students. Participants will run these tasks in an idealised environment with synthetic data and a real-world scenario with evaluation data collected from a series of A/B tests.