 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgegencat: Generative computerized adaptive testing
Feb 23, 2026Existing computerized Adaptive Testing (CAT) frameworks are typically built on predicting the correctness of a student response to a question. Although effective, this approach fails to leverage textual information in questions and responses, especially for open-ended questions. In this work, we propose GENCAT (\textbf{GEN}erative \textbf{CAT}), a novel CAT framework that leverages Large Language Models for knowledge estimate and question selection. First, we develop a Generative Item Response Theory (GIRT) model that enables us to estimate student knowledge from their open-ended responses and predict responses to unseen questions. We train the model in a two-step process, first via Supervised Fine-Tuning and then via preference optimization for knowledge-response alignment. Second, we introduce three question selection algorithms that leverage the generative capabilities of the GIRT model, based on the uncertainty, linguistic diversity, and information of sampled student responses. Third, we conduct experiments on two real-world programming datasets and demonstrate that GENCAT outperforms existing CAT baselines, achieving an AUC improvement of up to 4.32\% in the key early testing stages.
Using LLMs for Knowledge Component-level Correctness Labeling in Open-ended Coding Problems
Feb 19, 2026Fine-grained skill representations, commonly referred to as knowledge components (KCs), are fundamental to many approaches in student modeling and learning analytics. However, KC-level correctness labels are rarely available in real-world datasets, especially for open-ended programming tasks where solutions typically involve multiple KCs simultaneously. Simply propagating problem-level correctness to all associated KCs obscures partial mastery and often leads to poorly fitted learning curves. To address this challenge, we propose an automated framework that leverages large language models (LLMs) to label KC-level correctness directly from student-written code. Our method assesses whether each KC is correctly applied and further introduces a temporal context-aware Code-KC mapping mechanism to better align KCs with individual student code. We evaluate the resulting KC-level correctness labels in terms of learning curve fit and predictive performance using the power law of practice and the Additive Factors Model. Experimental results show that our framework leads to learning curves that are more consistent with cognitive theory and improves predictive performance, compared to baselines. Human evaluation further demonstrates substantial agreement between LLM and expert annotations.
Letting Tutor Personas "Speak Up" for LLMs: Learning Steering Vectors from Dialogue via Preference Optimization
Feb 07, 2026With the emergence of large language models (LLMs) as a powerful class of generative artificial intelligence (AI), their use in tutoring has become increasingly prominent. Prior works on LLM-based tutoring typically learn a single tutor policy and do not capture the diversity of tutoring styles. In real-world tutor-student interactions, pedagogical intent is realized through adaptive instructional strategies, with tutors varying the level of scaffolding, instructional directiveness, feedback, and affective support in response to learners' needs. These differences can all impact dialogue dynamics and student engagement. In this paper, we explore how tutor personas embedded in human tutor-student dialogues can be used to guide LLM behavior without relying on explicitly prompted instructions. We modify Bidirectional Preference Optimization (BiPO) to learn a steering vector, an activation-space direction that steers model responses towards certain tutor personas. We find that this steering vector captures tutor-specific variation across dialogue contexts, improving semantic alignment with ground-truth tutor utterances and increasing preference-based evaluations, while largely preserving lexical similarity. Analysis of the learned directional coefficients further reveals interpretable structure across tutors, corresponding to consistent differences in tutoring behavior. These results demonstrate that activation steering offers an effective and interpretable way for controlling tutor-specific variation in LLMs using signals derived directly from human dialogue data.
CATTO: Balancing Preferences and Confidence in Language Models
Jan 30, 2026Large language models (LLMs) often make accurate next token predictions but their confidence in these predictions can be poorly calibrated: high-confidence predictions are frequently wrong, and low-confidence predictions may be correct. This miscalibration is exacerbated by preference-based alignment methods breaking the link between predictive probability and correctness. We introduce a Calibration Aware Token-level Training Objective (CATTO), a calibration-aware objective that aligns predicted confidence with empirical prediction correctness, which can be combined with the original preference optimization objectives. Empirically, CATTO reduces Expected Calibration Error (ECE) by 2.22%-7.61% in-distribution and 1.46%-10.44% out-of-distribution compared to direct preference optimization (DPO), and by 0.22%-1.24% in-distribution and 1.23%-5.07% out-of-distribution compared to the strongest DPO baseline. This improvement in confidence does not come at a cost of losing task accuracy, where CATTO maintains or slightly improves multiple-choice question-answering accuracy on five datasets. We also introduce Confidence@k, a test-time scaling mechanism leveraging calibrated token probabilities for Bayes-optimal selection of output tokens.
KASER: Knowledge-Aligned Student Error Simulator for Open-Ended Coding Tasks
Jan 10, 2026Open-ended tasks, such as coding problems that are common in computer science education, provide detailed insights into student knowledge. However, training large language models (LLMs) to simulate and predict possible student errors in their responses to these problems can be challenging: they often suffer from mode collapse and fail to fully capture the diversity in syntax, style, and solution approach in student responses. In this work, we present KASER (Knowledge-Aligned Student Error Simulator), a novel approach that aligns errors with student knowledge. We propose a training method based on reinforcement learning using a hybrid reward that reflects three aspects of student code prediction: i) code similarity to the ground-truth, ii) error matching, and iii) code prediction diversity. On two real-world datasets, we perform two levels of evaluation and show that: At the per-student-problem pair level, our method outperforms baselines on code and error prediction; at the per-problem level, our method outperforms baselines on error coverage and simulated code diversity.
Simulated Students in Tutoring Dialogues: Substance or Illusion?
Jan 07, 2026Advances in large language models (LLMs) enable many new innovations in education. However, evaluating the effectiveness of new technology requires real students, which is time-consuming and hard to scale up. Therefore, many recent works on LLM-powered tutoring solutions have used simulated students for both training and evaluation, often via simple prompting. Surprisingly, little work has been done to ensure or even measure the quality of simulated students. In this work, we formally define the student simulation task, propose a set of evaluation metrics that span linguistic, behavioral, and cognitive aspects, and benchmark a wide range of student simulation methods on these metrics. We experiment on a real-world math tutoring dialogue dataset, where both automated and human evaluation results show that prompting strategies for student simulation perform poorly; supervised fine-tuning and preference optimization yield much better but still limited performance, motivating future work on this challenging task.
Exploring LLMs for Predicting Tutor Strategy and Student Outcomes in Dialogues
Jul 09, 2025Tutoring dialogues have gained significant attention in recent years, given the prominence of online learning and the emerging tutoring abilities of artificial intelligence (AI) agents powered by large language models (LLMs). Recent studies have shown that the strategies used by tutors can have significant effects on student outcomes, necessitating methods to predict how tutors will behave and how their actions impact students. However, few works have studied predicting tutor strategy in dialogues. Therefore, in this work we investigate the ability of modern LLMs, particularly Llama 3 and GPT-4o, to predict both future tutor moves and student outcomes in dialogues, using two math tutoring dialogue datasets. We find that even state-of-the-art LLMs struggle to predict future tutor strategy while tutor strategy is highly indicative of student outcomes, outlining a need for more powerful methods to approach this task.
LookAlike: Consistent Distractor Generation in Math MCQs
May 03, 2025



Large language models (LLMs) are increasingly used to generate distractors for multiple-choice questions (MCQs), especially in domains like math education. However, existing approaches are limited in ensuring that the generated distractors are consistent with common student errors. We propose LookAlike, a method that improves error-distractor consistency via preference optimization. Our two main innovations are: (a) mining synthetic preference pairs from model inconsistencies, and (b) alternating supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to stabilize training. Unlike prior work that relies on heuristics or manually annotated preference data, LookAlike uses its own generation inconsistencies as dispreferred samples, thus enabling scalable and stable training. Evaluated on a real-world dataset of 1,400+ math MCQs, LookAlike achieves 51.6% accuracy in distractor generation and 57.2% in error generation under LLM-as-a-judge evaluation, outperforming an existing state-of-the-art method (45.6% / 47.7%). These improvements highlight the effectiveness of preference-based regularization and inconsistency mining for generating consistent math MCQ distractors at scale.
Reasoning and Sampling-Augmented MCQ Difficulty Prediction via LLMs
Mar 11, 2025



The difficulty of multiple-choice questions (MCQs) is a crucial factor for educational assessments. Predicting MCQ difficulty is challenging since it requires understanding both the complexity of reaching the correct option and the plausibility of distractors, i.e., incorrect options. In this paper, we propose a novel, two-stage method to predict the difficulty of MCQs. First, to better estimate the complexity of each MCQ, we use large language models (LLMs) to augment the reasoning steps required to reach each option. We use not just the MCQ itself but also these reasoning steps as input to predict the difficulty. Second, to capture the plausibility of distractors, we sample knowledge levels from a distribution to account for variation among students responding to the MCQ. This setup, inspired by item response theory (IRT), enable us to estimate the likelihood of students selecting each (both correct and incorrect) option. We align these predictions with their ground truth values, using a Kullback-Leibler (KL) divergence-based regularization objective, and use estimated likelihoods to predict MCQ difficulty. We evaluate our method on two real-world \emph{math} MCQ and response datasets with ground truth difficulty values estimated using IRT. Experimental results show that our method outperforms all baselines, up to a 28.3\% reduction in mean squared error and a 34.6\% improvement in the coefficient of determination. We also qualitatively discuss how our novel method results in higher accuracy in predicting MCQ difficulty.
The StudyChat Dataset: Student Dialogues With ChatGPT in an Artificial Intelligence Course
Mar 11, 2025


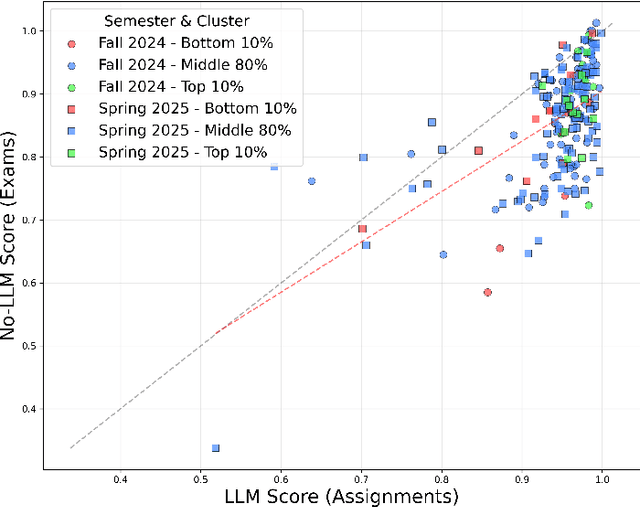
The widespread availability of large language models (LLMs), such as ChatGPT, has significantly impacted education, raising both opportunities and challenges. Students can frequently interact with LLM-powered, interactive learning tools, but their usage patterns need to be analyzed to ensure ethical usage of these tools. To better understand how students interact with LLMs in an academic setting, we introduce \textbf{StudyChat}, a publicly available dataset capturing real-world student interactions with an LLM-powered tutoring chatbot in a semester-long, university-level artificial intelligence (AI) course. We deploy a web application that replicates ChatGPT's core functionalities, and use it to log student interactions with the LLM while working on programming assignments. We collect 1,197 conversations, which we annotate using a dialogue act labeling schema inspired by observed interaction patterns and prior research. Additionally, we analyze these interactions, highlight behavioral trends, and analyze how specific usage patterns relate to course outcomes. \textbf{StudyChat} provides a rich resource for the learning sciences and AI in education communities, enabling further research into the evolving role of LLMs in education.