 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Collapse: LLMs Flatten Long-Form Public Debate
Jun 01, 2026As LLMs are increasingly used to draft public-facing arguments, they may flatten public debate by repeatedly introducing the same polished, plausible arguments. We study argument collapse, the tendency of essays generated by different LLMs to converge to a smaller set of main arguments, sub-arguments, and paragraph-level structures. We compare 1,039 human responses from 195 New York Times (NYT) debates, 448 human responses from 61 longer-form Boston Review (BR) forums, and 23,384 LLM-generated essays. In the NYT corpus, 65.3% of human main arguments are unique within a debate, compared to 3.4% of LLM main arguments. Asking LLMs to generate diverse answers adds variation, but a typical model recovers only about half of the distinct human main arguments, with much of the added variation falling outside the observed human argument space. Collapse also appears in sub-arguments, where among essays with the same main argument, 41.0% of human sub-arguments are unique versus 9.1% from LLM responses. Qualitatively, LLMs often reuse generalized and hedged sub-arguments, while humans prefer more concrete and topic-specific ones. Structure-wise, LLM-generated essays tend to follow a more fixed arc, often opening with a direct claim and moving quickly toward proposals. The same patterns hold in longer BR essays, suggesting that argument collapse extends beyond short-form responses.
OWL: Probing Cross-Lingual Recall of Memorized Texts via World Literature
May 28, 2025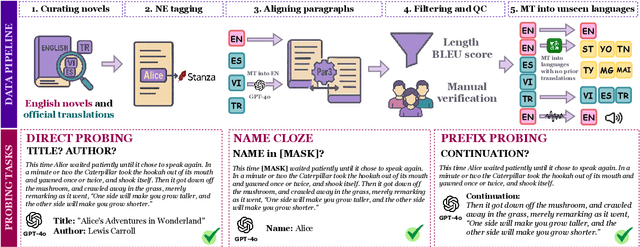



Large language models (LLMs) are known to memorize and recall English text from their pretraining data. However, the extent to which this ability generalizes to non-English languages or transfers across languages remains unclear. This paper investigates multilingual and cross-lingual memorization in LLMs, probing if memorized content in one language (e.g., English) can be recalled when presented in translation. To do so, we introduce OWL, a dataset of 31.5K aligned excerpts from 20 books in ten languages, including English originals, official translations (Vietnamese, Spanish, Turkish), and new translations in six low-resource languages (Sesotho, Yoruba, Maithili, Malagasy, Setswana, Tahitian). We evaluate memorization across model families and sizes through three tasks: (1) direct probing, which asks the model to identify a book's title and author; (2) name cloze, which requires predicting masked character names; and (3) prefix probing, which involves generating continuations. We find that LLMs consistently recall content across languages, even for texts without direct translation in pretraining data. GPT-4o, for example, identifies authors and titles 69% of the time and masked entities 6% of the time in newly translated excerpts. Perturbations (e.g., masking characters, shuffling words) modestly reduce direct probing accuracy (7% drop for shuffled official translations). Our results highlight the extent of cross-lingual memorization and provide insights on the differences between the models.
Frankentext: Stitching random text fragments into long-form narratives
May 23, 2025

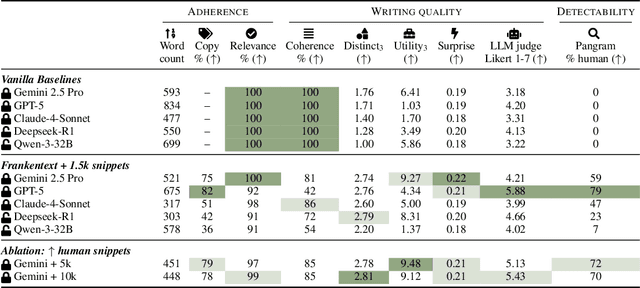
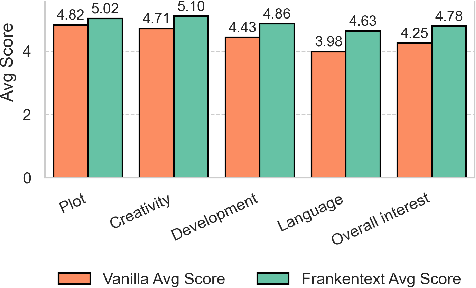
We introduce Frankentexts, a new type of long-form narratives produced by LLMs under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim from human writings. This task presents a challenging test of controllable generation, requiring models to satisfy a writing prompt, integrate disparate text fragments, and still produce a coherent narrative. To generate Frankentexts, we instruct the model to produce a draft by selecting and combining human-written passages, then iteratively revise the draft while maintaining a user-specified copy ratio. We evaluate the resulting Frankentexts along three axes: writing quality, instruction adherence, and detectability. Gemini-2.5-Pro performs surprisingly well on this task: 81% of its Frankentexts are coherent and 100% relevant to the prompt. Notably, up to 59% of these outputs are misclassified as human-written by detectors like Pangram, revealing limitations in AI text detectors. Human annotators can sometimes identify Frankentexts through their abrupt tone shifts and inconsistent grammar between segments, especially in longer generations. Beyond presenting a challenging generation task, Frankentexts invite discussion on building effective detectors for this new grey zone of authorship, provide training data for mixed authorship detection, and serve as a sandbox for studying human-AI co-writing processes.
Can Large Language Models Really Recognize Your Name?
May 20, 2025



Large language models (LLMs) are increasingly being used to protect sensitive user data. However, current LLM-based privacy solutions assume that these models can reliably detect personally identifiable information (PII), particularly named entities. In this paper, we challenge that assumption by revealing systematic failures in LLM-based privacy tasks. Specifically, we show that modern LLMs regularly overlook human names even in short text snippets due to ambiguous contexts, which cause the names to be misinterpreted or mishandled. We propose AMBENCH, a benchmark dataset of seemingly ambiguous human names, leveraging the name regularity bias phenomenon, embedded within concise text snippets along with benign prompt injections. Our experiments on modern LLMs tasked to detect PII as well as specialized tools show that recall of ambiguous names drops by 20--40% compared to more recognizable names. Furthermore, ambiguous human names are four times more likely to be ignored in supposedly privacy-preserving summaries generated by LLMs when benign prompt injections are present. These findings highlight the underexplored risks of relying solely on LLMs to safeguard user privacy and underscore the need for a more systematic investigation into their privacy failure modes.
BEARCUBS: A benchmark for computer-using web agents
Mar 10, 2025



Modern web agents possess computer use abilities that allow them to interact with webpages by sending commands to a virtual keyboard and mouse. While such agents have considerable potential to assist human users with complex tasks, evaluating their capabilities in real-world settings poses a major challenge. To this end, we introduce BEARCUBS, a "small but mighty" benchmark of 111 information-seeking questions designed to evaluate a web agent's ability to search, browse, and identify factual information from the web. Unlike prior web agent benchmarks, solving BEARCUBS requires (1) accessing live web content rather than synthetic or simulated pages, which captures the unpredictability of real-world web interactions; and (2) performing a broad range of multimodal interactions (e.g., video understanding, 3D navigation) that cannot be bypassed via text-based workarounds. Each question in BEARCUBS has a corresponding short, unambiguous answer and a human-validated browsing trajectory, allowing for transparent evaluation of agent performance and strategies. A human study confirms that BEARCUBS questions are solvable but non-trivial (84.7% human accuracy), revealing search inefficiencies and domain knowledge gaps as common failure points. By contrast, state-of-the-art computer-using agents underperform, with the best-scoring system (OpenAI's Operator) reaching only 24.3% accuracy. These results highlight critical areas for improvement, including reliable source selection and more powerful multimodal capabilities. To facilitate future research, BEARCUBS will be updated periodically to replace invalid or contaminated questions, keeping the benchmark fresh for future generations of web agents.
CLIPPER: Compression enables long-context synthetic data generation
Feb 20, 2025LLM developers are increasingly reliant on synthetic data, but generating high-quality data for complex long-context reasoning tasks remains challenging. We introduce CLIPPER, a compression-based approach for generating synthetic data tailored to narrative claim verification - a task that requires reasoning over a book to verify a given claim. Instead of generating claims directly from the raw text of the book, which results in artifact-riddled claims, CLIPPER first compresses the book into chapter outlines and book summaries and then uses these intermediate representations to generate complex claims and corresponding chain-of-thoughts. Compared to naive approaches, CLIPPER produces claims that are more valid, grounded, and complex. Using CLIPPER, we construct a dataset of 19K synthetic book claims paired with their source texts and chain-of-thought reasoning, and use it to fine-tune three open-weight models. Our best model achieves breakthrough results on narrative claim verification (from 28% to 76% accuracy on our test set) and sets a new state-of-the-art for sub-10B models on the NoCha leaderboard. Further analysis shows that our models generate more detailed and grounded chain-of-thought reasoning while also improving performance on other narrative understanding tasks (e.g., NarrativeQA).
Whose story is it? Personalizing story generation by inferring author styles
Feb 18, 2025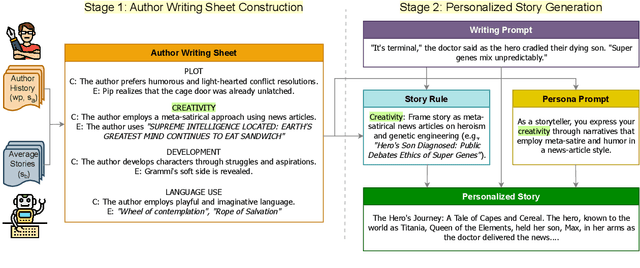

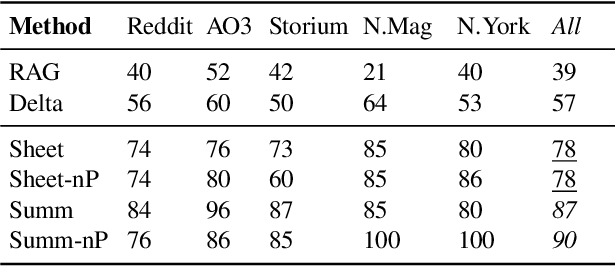
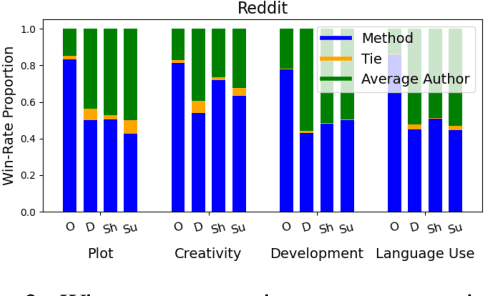
Personalization has become essential for improving user experience in interactive writing and educational applications, yet its potential in story generation remains largely unexplored. In this work, we propose a novel two-stage pipeline for personalized story generation. Our approach first infers an author's implicit story-writing characteristics from their past work and organizes them into an Author Writing Sheet, inspired by narrative theory. The second stage uses this sheet to simulate the author's persona through tailored persona descriptions and personalized story writing rules. To enable and validate our approach, we construct Mythos, a dataset of 590 stories from 64 authors across five distinct sources that reflect diverse story-writing settings. A head-to-head comparison with a non-personalized baseline demonstrates our pipeline's effectiveness in generating high-quality personalized stories. Our personalized stories achieve a 75 percent win rate (versus 14 percent for the baseline and 11 percent ties) in capturing authors' writing style based on their past works. Human evaluation highlights the high quality of our Author Writing Sheet and provides valuable insights into the personalized story generation task. Notable takeaways are that writings from certain sources, such as Reddit, are easier to personalize than others, like AO3, while narrative aspects, like Creativity and Language Use, are easier to personalize than others, like Plot.
Interactive Topic Models with Optimal Transport
Jun 28, 2024


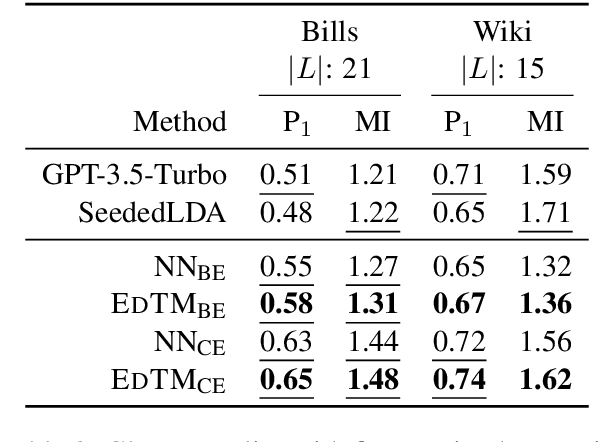
Topic models are widely used to analyze document collections. While they are valuable for discovering latent topics in a corpus when analysts are unfamiliar with the corpus, analysts also commonly start with an understanding of the content present in a corpus. This may be through categories obtained from an initial pass over the corpus or a desire to analyze the corpus through a predefined set of categories derived from a high level theoretical framework (e.g. political ideology). In these scenarios analysts desire a topic modeling approach which incorporates their understanding of the corpus while supporting various forms of interaction with the model. In this work, we present EdTM, as an approach for label name supervised topic modeling. EdTM models topic modeling as an assignment problem while leveraging LM/LLM based document-topic affinities and using optimal transport for making globally coherent topic-assignments. In experiments, we show the efficacy of our framework compared to few-shot LLM classifiers, and topic models based on clustering and LDA. Further, we show EdTM's ability to incorporate various forms of analyst feedback and while remaining robust to noisy analyst inputs.
Suri: Multi-constraint Instruction Following for Long-form Text Generation
Jun 27, 2024



Existing research on instruction following largely focuses on tasks with simple instructions and short responses. In this work, we explore multi-constraint instruction following for generating long-form text. We create Suri, a dataset with 20K human-written long-form texts paired with LLM-generated backtranslated instructions that contain multiple complex constraints. Because of prohibitive challenges associated with collecting human preference judgments on long-form texts, preference-tuning algorithms such as DPO are infeasible in our setting; thus, we propose Instructional ORPO (I-ORPO), an alignment method based on the ORPO algorithm. Instead of receiving negative feedback from dispreferred responses, I-ORPO obtains negative feedback from synthetically corrupted instructions generated by an LLM. Using Suri, we perform supervised and I-ORPO fine-tuning on Mistral-7b-Instruct-v0.2. The resulting models, Suri-SFT and Suri-I-ORPO, generate significantly longer texts (~5K tokens) than base models without significant quality deterioration. Our human evaluation shows that while both SFT and I-ORPO models satisfy most constraints, Suri-I-ORPO generations are generally preferred for their coherent and informative incorporation of the constraints. We release our code at https://github.com/chtmp223/suri.
TopicGPT: A Prompt-based Topic Modeling Framework
Nov 02, 2023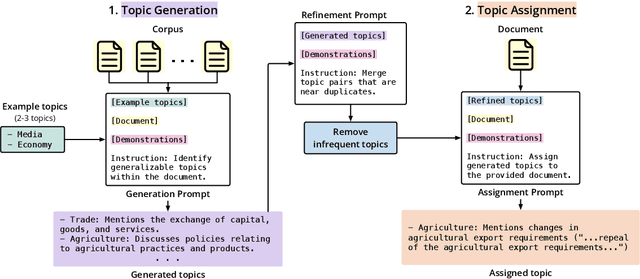
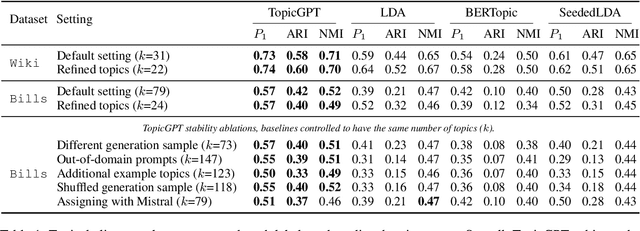

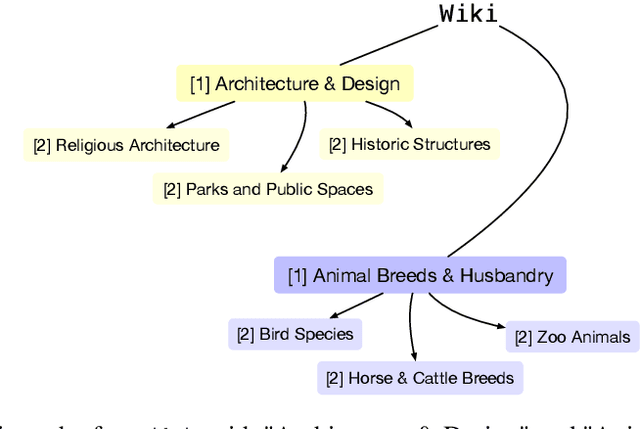
Topic modeling is a well-established technique for exploring text corpora. Conventional topic models (e.g., LDA) represent topics as bags of words that often require "reading the tea leaves" to interpret; additionally, they offer users minimal semantic control over topics. To tackle these issues, we introduce TopicGPT, a prompt-based framework that uses large language models (LLMs) to uncover latent topics within a provided text collection. TopicGPT produces topics that align better with human categorizations compared to competing methods: for example, it achieves a harmonic mean purity of 0.74 against human-annotated Wikipedia topics compared to 0.64 for the strongest baseline. Its topics are also more interpretable, dispensing with ambiguous bags of words in favor of topics with natural language labels and associated free-form descriptions. Moreover, the framework is highly adaptable, allowing users to specify constraints and modify topics without the need for model retraining. TopicGPT can be further extended to hierarchical topical modeling, enabling users to explore topics at various levels of granularity. By streamlining access to high-quality and interpretable topics, TopicGPT represents a compelling, human-centered approach to topic modeling.