 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Instructed Retrieval Models Really Support Exploration?
Jan 16, 2026Exploratory searches are characterized by under-specified goals and evolving query intents. In such scenarios, retrieval models that can capture user-specified nuances in query intent and adapt results accordingly are desirable -- instruction-following retrieval models promise such a capability. In this work, we evaluate instructed retrievers for the prevalent yet under-explored application of aspect-conditional seed-guided exploration using an expert-annotated test collection. We evaluate both recent LLMs fine-tuned for instructed retrieval and general-purpose LLMs prompted for ranking with the highly performant Pairwise Ranking Prompting. We find that the best instructed retrievers improve on ranking relevance compared to instruction-agnostic approaches. However, we also find that instruction following performance, crucial to the user experience of interacting with models, does not mirror ranking relevance improvements and displays insensitivity or counter-intuitive behavior to instructions. Our results indicate that while users may benefit from using current instructed retrievers over instruction-agnostic models, they may not benefit from using them for long-running exploratory sessions requiring greater sensitivity to instructions.
Prototypical Human-AI Collaboration Behaviors from LLM-Assisted Writing in the Wild
May 21, 2025As large language models (LLMs) are used in complex writing workflows, users engage in multi-turn interactions to steer generations to better fit their needs. Rather than passively accepting output, users actively refine, explore, and co-construct text. We conduct a large-scale analysis of this collaborative behavior for users engaged in writing tasks in the wild with two popular AI assistants, Bing Copilot and WildChat. Our analysis goes beyond simple task classification or satisfaction estimation common in prior work and instead characterizes how users interact with LLMs through the course of a session. We identify prototypical behaviors in how users interact with LLMs in prompts following their original request. We refer to these as Prototypical Human-AI Collaboration Behaviors (PATHs) and find that a small group of PATHs explain a majority of the variation seen in user-LLM interaction. These PATHs span users revising intents, exploring texts, posing questions, adjusting style or injecting new content. Next, we find statistically significant correlations between specific writing intents and PATHs, revealing how users' intents shape their collaboration behaviors. We conclude by discussing the implications of our findings on LLM alignment.
Memory Augmented Cross-encoders for Controllable Personalized Search
Nov 05, 2024



Personalized search represents a problem where retrieval models condition on historical user interaction data in order to improve retrieval results. However, personalization is commonly perceived as opaque and not amenable to control by users. Further, personalization necessarily limits the space of items that users are exposed to. Therefore, prior work notes a tension between personalization and users' ability for discovering novel items. While discovery of novel items in personalization setups may be resolved through search result diversification, these approaches do little to allow user control over personalization. Therefore, in this paper, we introduce an approach for controllable personalized search. Our model, CtrlCE presents a novel cross-encoder model augmented with an editable memory constructed from users historical items. Our proposed memory augmentation allows cross-encoder models to condition on large amounts of historical user data and supports interaction from users permitting control over personalization. Further, controllable personalization for search must account for queries which don't require personalization, and in turn user control. For this, we introduce a calibrated mixing model which determines when personalization is necessary. This allows system designers using CtrlCE to only obtain user input for control when necessary. In multiple datasets of personalized search, we show CtrlCE to result in effective personalization as well as fulfill various key goals for controllable personalized search.
Interactive Topic Models with Optimal Transport
Jun 28, 2024


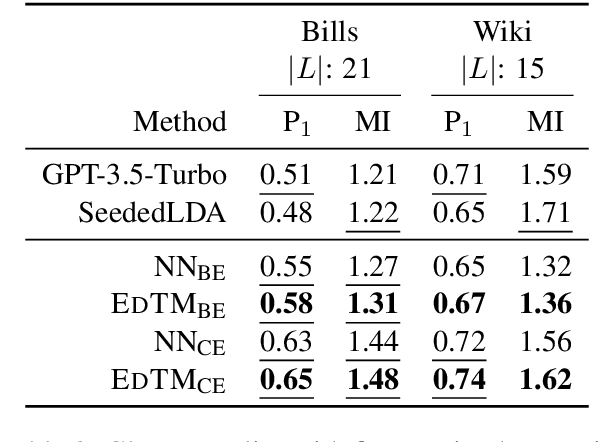
Topic models are widely used to analyze document collections. While they are valuable for discovering latent topics in a corpus when analysts are unfamiliar with the corpus, analysts also commonly start with an understanding of the content present in a corpus. This may be through categories obtained from an initial pass over the corpus or a desire to analyze the corpus through a predefined set of categories derived from a high level theoretical framework (e.g. political ideology). In these scenarios analysts desire a topic modeling approach which incorporates their understanding of the corpus while supporting various forms of interaction with the model. In this work, we present EdTM, as an approach for label name supervised topic modeling. EdTM models topic modeling as an assignment problem while leveraging LM/LLM based document-topic affinities and using optimal transport for making globally coherent topic-assignments. In experiments, we show the efficacy of our framework compared to few-shot LLM classifiers, and topic models based on clustering and LDA. Further, we show EdTM's ability to incorporate various forms of analyst feedback and while remaining robust to noisy analyst inputs.
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
Nov 15, 2023
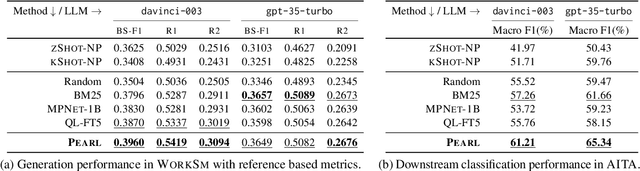
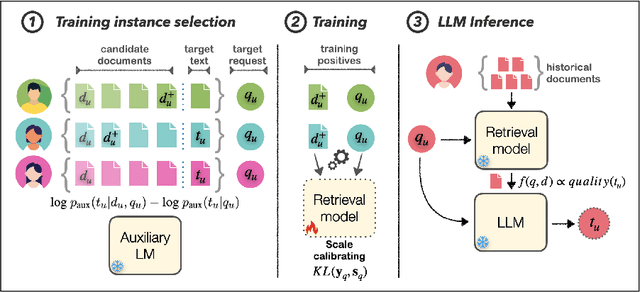

Powerful large language models have facilitated the development of writing assistants that promise to significantly improve the quality and efficiency of composition and communication. However, a barrier to effective assistance is the lack of personalization in LLM outputs to the author's communication style and specialized knowledge. In this paper, we address this challenge by proposing PEARL, a retrieval-augmented LLM writing assistant personalized with a generation-calibrated retriever. Our retriever is trained to select historic user-authored documents for prompt augmentation, such that they are likely to best personalize LLM generations for a user request. We propose two key novelties for training our retriever: 1) A training data selection method that identifies user requests likely to benefit from personalization and documents that provide that benefit; and 2) A scale-calibrating KL-divergence objective that ensures that our retriever closely tracks the benefit of a document for personalized generation. We demonstrate the effectiveness of PEARL in generating personalized workplace social media posts and Reddit comments. Finally, we showcase the potential of a generation-calibrated retriever to double as a performance predictor and further improve low-quality generations via LLM chaining.
Large Language Model Augmented Narrative Driven Recommendations
Jun 04, 2023Narrative-driven recommendation (NDR) presents an information access problem where users solicit recommendations with verbose descriptions of their preferences and context, for example, travelers soliciting recommendations for points of interest while describing their likes/dislikes and travel circumstances. These requests are increasingly important with the rise of natural language-based conversational interfaces for search and recommendation systems. However, NDR lacks abundant training data for models, and current platforms commonly do not support these requests. Fortunately, classical user-item interaction datasets contain rich textual data, e.g., reviews, which often describe user preferences and context - this may be used to bootstrap training for NDR models. In this work, we explore using large language models (LLMs) for data augmentation to train NDR models. We use LLMs for authoring synthetic narrative queries from user-item interactions with few-shot prompting and train retrieval models for NDR on synthetic queries and user-item interaction data. Our experiments demonstrate that this is an effective strategy for training small-parameter retrieval models that outperform other retrieval and LLM baselines for narrative-driven recommendation.
LaMP: When Large Language Models Meet Personalization
Apr 22, 2023



This paper highlights the importance of personalization in the current state of natural language understanding and generation and introduces the LaMP benchmark -- a novel benchmark for training and evaluating language models for producing personalized outputs. LaMP offers a comprehensive evaluation framework with diverse language tasks and multiple entries for each user profile. It consists of seven personalized tasks, spanning three classification and four text generation tasks. We also propose a retrieval augmentation approach that retrieves personalized items from user profiles to construct personalized prompts for large language models. Our baseline zero-shot and fine-tuned model results indicate that LMs utilizing profile augmentation outperform their counterparts that do not factor in profile information.
Editable User Profiles for Controllable Text Recommendation
Apr 09, 2023



Methods for making high-quality recommendations often rely on learning latent representations from interaction data. These methods, while performant, do not provide ready mechanisms for users to control the recommendation they receive. Our work tackles this problem by proposing LACE, a novel concept value bottleneck model for controllable text recommendations. LACE represents each user with a succinct set of human-readable concepts through retrieval given user-interacted documents and learns personalized representations of the concepts based on user documents. This concept based user profile is then leveraged to make recommendations. The design of our model affords control over the recommendations through a number of intuitive interactions with a transparent user profile. We first establish the quality of recommendations obtained from LACE in an offline evaluation on three recommendation tasks spanning six datasets in warm-start, cold-start, and zero-shot setups. Next, we validate the controllability of LACE under simulated user interactions. Finally, we implement LACE in an interactive controllable recommender system and conduct a user study to demonstrate that users are able to improve the quality of recommendations they receive through interactions with an editable user profile.
How Data Scientists Review the Scholarly Literature
Jan 10, 2023

Keeping up with the research literature plays an important role in the workflow of scientists - allowing them to understand a field, formulate the problems they focus on, and develop the solutions that they contribute, which in turn shape the nature of the discipline. In this paper, we examine the literature review practices of data scientists. Data science represents a field seeing an exponential rise in papers, and increasingly drawing on and being applied in numerous diverse disciplines. Recent efforts have seen the development of several tools intended to help data scientists cope with a deluge of research and coordinated efforts to develop AI tools intended to uncover the research frontier. Despite these trends indicative of the information overload faced by data scientists, no prior work has examined the specific practices and challenges faced by these scientists in an interdisciplinary field with evolving scholarly norms. In this paper, we close this gap through a set of semi-structured interviews and think-aloud protocols of industry and academic data scientists (N = 20). Our results while corroborating other knowledge workers' practices uncover several novel findings: individuals (1) are challenged in seeking and sensemaking of papers beyond their disciplinary bubbles, (2) struggle to understand papers in the face of missing details and mathematical content, (3) grapple with the deluge by leveraging the knowledge context in code, blogs, and talks, and (4) lean on their peers online and in-person. Furthermore, we outline future directions likely to help data scientists cope with the burgeoning research literature.
Augmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022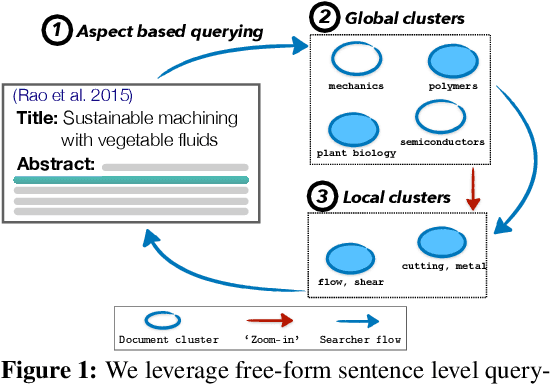
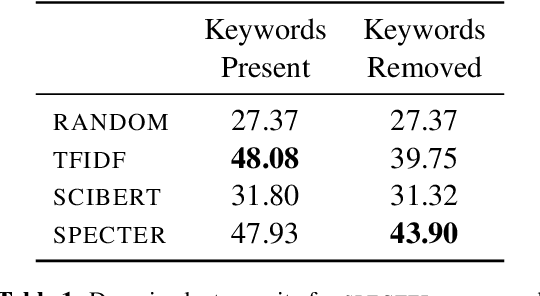
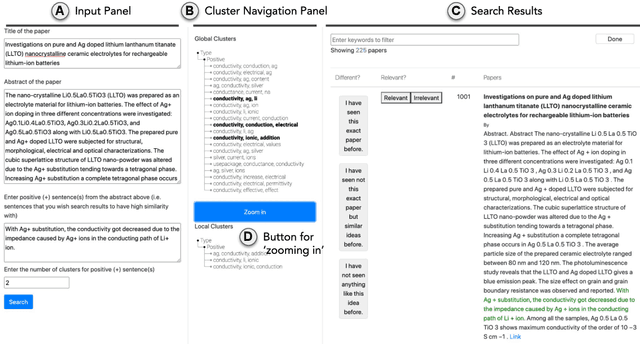

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.