 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Security Risk Detection and Verification in Open Agentic Skill Ecosystems
May 30, 2026Open agent platforms allow community contributors to publish reusable skills that agents can invoke at runtime. This extensibility also creates a supply-chain risk: malicious contributors can hide harmful behavior inside skills that appear benign under superficial inspection. However, existing defenses are hard to evaluate because there is no benchmark that measures both malicious-skill detection and runtime verification. We present SkillVetBench, a two-stage security vetting benchmark for open agentic skill ecosystems. The first stage performs semantic vetting over each skill's natural-language specification to detect hidden malicious intent. The second stage executes flagged skills in an instrumented sandbox to observe runtime behavior and collect auditable evidence. We build a benchmark from confirmed malicious skills in the live OpenClaw ecosystem, including samples from the recent ClawHavoc supplychain campaign. Unlike static-only methods, SkillVetBench verifies detected threats with execution traces. Our experiments show that: (1) semantic-only and signature-based baselines are insufficient, missing up to 89\% of malicious skills whose threats arise from natural-language instructions, multicomponent logic, or cross-component interactions; (2) runtime attacks are concentrated in a small set of high-permission primitives, especially exec, write\_file, install\_skill, and spawn; and (3) SkillVetBench provides case studies in which sandbox execution directly supports malicious verdicts with concrete runtime evidence.
How to Interpret Agent Behavior
May 13, 2026Autonomous agents such as Claude Code and Codex now operate for hours or even days. Understanding their runtime behavior has become critical for downstream tasks such as diagnosing inefficiencies, fixing bugs, and ensuring better oversight. A primary way to gain this understanding is analyzing the reasoning trajectories and execution traces these agents generate. Yet such data remains in unstructured natural-language form, making it difficult for humans to interpret at scale. We introduce ACT*ONOMY (a combination of Action and Taxonomy), a taxonomy for describing and analyzing agent behavior at runtime. ACT*ONOMY has two components: (1) the taxonomy itself, developed through Grounded Theory and structured as a three-level hierarchy of 10 actions, 46 subactions, and 120 leaf categories; and (2) an open repository that hosts the living taxonomy, provides an automated analysis pipeline that applies it to agent trajectories analysis, and defines an extension protocol for customization and growth. Our experiments show that ACTONOMY can compare behavioral profiles across agents and characterize a single agent's behavior across diverse trajectories, surfacing patterns indicative of failure modes. By providing a shared vocabulary, ACT*ONOMY helps researchers, agent designers, and end users interpret agent behavior more consistently, enabling better oversight and control.
Human-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
WhatELSE: Shaping Narrative Spaces at Configurable Level of Abstraction for AI-bridged Interactive Storytelling
Feb 25, 2025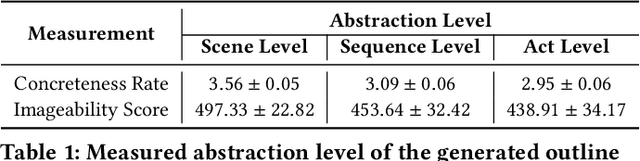
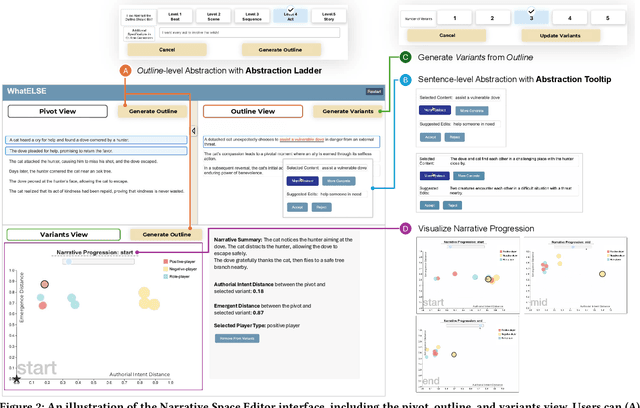

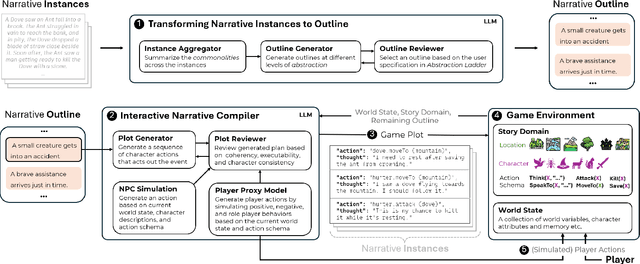
Generative AI significantly enhances player agency in interactive narratives (IN) by enabling just-in-time content generation that adapts to player actions. While delegating generation to AI makes IN more interactive, it becomes challenging for authors to control the space of possible narratives - within which the final story experienced by the player emerges from their interaction with AI. In this paper, we present WhatELSE, an AI-bridged IN authoring system that creates narrative possibility spaces from example stories. WhatELSE provides three views (narrative pivot, outline, and variants) to help authors understand the narrative space and corresponding tools leveraging linguistic abstraction to control the boundaries of the narrative space. Taking innovative LLM-based narrative planning approaches, WhatELSE further unfolds the narrative space into executable game events. Through a user study (N=12) and technical evaluations, we found that WhatELSE enables authors to perceive and edit the narrative space and generates engaging interactive narratives at play-time.
From Text to Trust: Empowering AI-assisted Decision Making with Adaptive LLM-powered Analysis
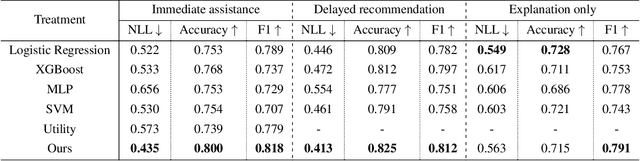
Feb 17, 2025AI-assisted decision making becomes increasingly prevalent, yet individuals often fail to utilize AI-based decision aids appropriately especially when the AI explanations are absent, potentially as they do not %understand reflect on AI's decision recommendations critically. Large language models (LLMs), with their exceptional conversational and analytical capabilities, present great opportunities to enhance AI-assisted decision making in the absence of AI explanations by providing natural-language-based analysis of AI's decision recommendation, e.g., how each feature of a decision making task might contribute to the AI recommendation. In this paper, via a randomized experiment, we first show that presenting LLM-powered analysis of each task feature, either sequentially or concurrently, does not significantly improve people's AI-assisted decision performance. To enable decision makers to better leverage LLM-powered analysis, we then propose an algorithmic framework to characterize the effects of LLM-powered analysis on human decisions and dynamically decide which analysis to present. Our evaluation with human subjects shows that this approach effectively improves decision makers' appropriate reliance on AI in AI-assisted decision making.
Does More Advice Help? The Effects of Second Opinions in AI-Assisted Decision Making
Jan 13, 2024



AI assistance in decision-making has become popular, yet people's inappropriate reliance on AI often leads to unsatisfactory human-AI collaboration performance. In this paper, through three pre-registered, randomized human subject experiments, we explore whether and how the provision of {second opinions} may affect decision-makers' behavior and performance in AI-assisted decision-making. We find that if both the AI model's decision recommendation and a second opinion are always presented together, decision-makers reduce their over-reliance on AI while increase their under-reliance on AI, regardless whether the second opinion is generated by a peer or another AI model. However, if decision-makers have the control to decide when to solicit a peer's second opinion, we find that their active solicitations of second opinions have the potential to mitigate over-reliance on AI without inducing increased under-reliance in some cases. We conclude by discussing the implications of our findings for promoting effective human-AI collaborations in decision-making.
Decoding AI's Nudge: A Unified Framework to Predict Human Behavior in AI-assisted Decision Making
Jan 11, 2024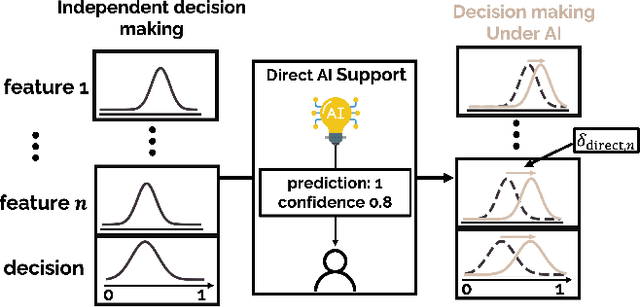
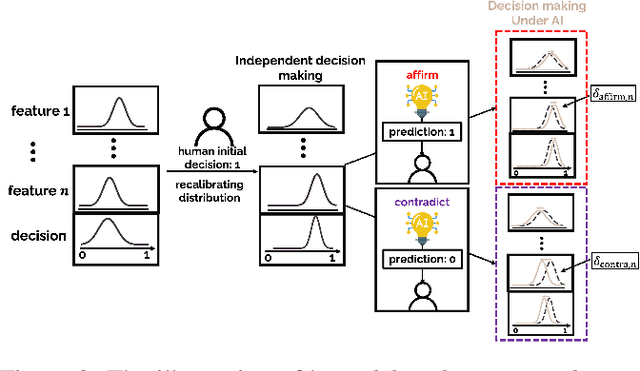

With the rapid development of AI-based decision aids, different forms of AI assistance have been increasingly integrated into the human decision making processes. To best support humans in decision making, it is essential to quantitatively understand how diverse forms of AI assistance influence humans' decision making behavior. To this end, much of the current research focuses on the end-to-end prediction of human behavior using ``black-box'' models, often lacking interpretations of the nuanced ways in which AI assistance impacts the human decision making process. Meanwhile, methods that prioritize the interpretability of human behavior predictions are often tailored for one specific form of AI assistance, making adaptations to other forms of assistance difficult. In this paper, we propose a computational framework that can provide an interpretable characterization of the influence of different forms of AI assistance on decision makers in AI-assisted decision making. By conceptualizing AI assistance as the ``{\em nudge}'' in human decision making processes, our approach centers around modelling how different forms of AI assistance modify humans' strategy in weighing different information in making their decisions. Evaluations on behavior data collected from real human decision makers show that the proposed framework outperforms various baselines in accurately predicting human behavior in AI-assisted decision making. Based on the proposed framework, we further provide insights into how individuals with different cognitive styles are nudged by AI assistance differently.
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
Nov 15, 2023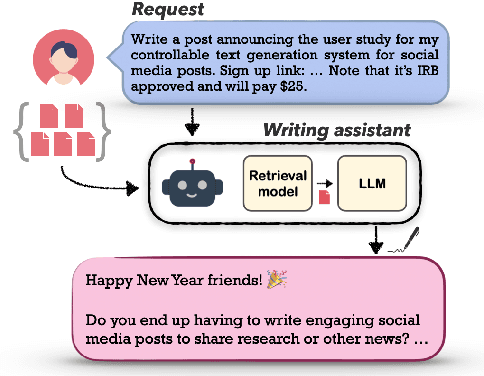
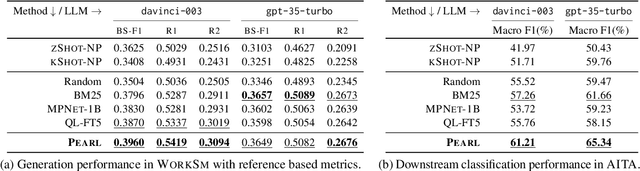
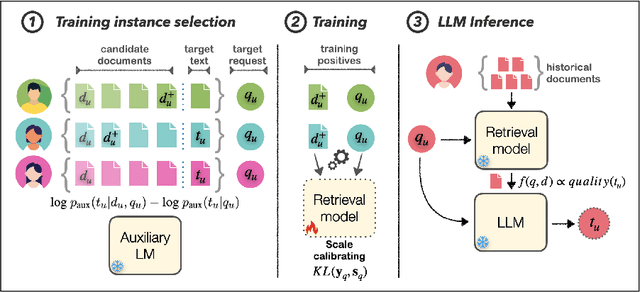

Powerful large language models have facilitated the development of writing assistants that promise to significantly improve the quality and efficiency of composition and communication. However, a barrier to effective assistance is the lack of personalization in LLM outputs to the author's communication style and specialized knowledge. In this paper, we address this challenge by proposing PEARL, a retrieval-augmented LLM writing assistant personalized with a generation-calibrated retriever. Our retriever is trained to select historic user-authored documents for prompt augmentation, such that they are likely to best personalize LLM generations for a user request. We propose two key novelties for training our retriever: 1) A training data selection method that identifies user requests likely to benefit from personalization and documents that provide that benefit; and 2) A scale-calibrating KL-divergence objective that ensures that our retriever closely tracks the benefit of a document for personalized generation. We demonstrate the effectiveness of PEARL in generating personalized workplace social media posts and Reddit comments. Finally, we showcase the potential of a generation-calibrated retriever to double as a performance predictor and further improve low-quality generations via LLM chaining.
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
Oct 13, 2023
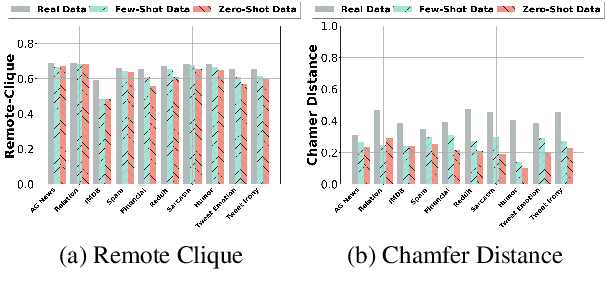


The collection and curation of high-quality training data is crucial for developing text classification models with superior performance, but it is often associated with significant costs and time investment. Researchers have recently explored using large language models (LLMs) to generate synthetic datasets as an alternative approach. However, the effectiveness of the LLM-generated synthetic data in supporting model training is inconsistent across different classification tasks. To better understand factors that moderate the effectiveness of the LLM-generated synthetic data, in this study, we look into how the performance of models trained on these synthetic data may vary with the subjectivity of classification. Our results indicate that subjectivity, at both the task level and instance level, is negatively associated with the performance of the model trained on synthetic data. We conclude by discussing the implications of our work on the potential and limitations of leveraging LLM for synthetic data generation.