 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Human Behavior Simulation via Verbal Feedback
May 19, 2026Humans learn social norms and behaviors from verbal feedback (e.g., a parent saying "that was rude" or a friend explaining "here's why that hurt"). Yet, learning from feedback for LLMs has largely focused on domains like code and math, where RL rewards are directly verifiable and condensed into scalar values. As LLMs are increasingly used to simulate human behavior, e.g., standing in for users, patients, students, and other personas, there is a pressing need to make them more human-like, which requires embracing a fundamentally different kind of signal: feedback that is verbal, subjective, and multi-faceted. We present DITTO, a model trained by treating verbal feedback as a first-class signal in reinforcement learning. After each rollout, DITTO receives verbal feedback and generates a feedback-conditioned improved rollout; both outputs are jointly optimized with GRPO, distilling verbal guidance into the base policy without requiring feedback at test time. We also introduce SOUL (Simulation gym Of hUman-Like behavior), a unified benchmark and training data suite spanning 10 tasks across six categories: Theory of Mind, character role play, social skill, learner simulation, user simulation, and persona simulation. DITTO achieves an average 36% improvement over the base model and exceeds GPT-5.4 on 6 of 10 SOUL benchmarks, demonstrating that RL with verbal feedback is a promising direction for training LLMs to simulate human behavior.
Evaluating LLM-Simulated Conversations in Modeling Inconsistent and Uncollaborative Behaviors in Human Social Interaction
Mar 17, 2026Simulating human conversations using large language models (LLMs) has emerged as a scalable methodology for modeling human social interaction. However, simulating human conversations is challenging because they inherently involve inconsistent and uncollaborative behaviors, such as misunderstandings and interruptions. Analysis comparing inconsistent and uncollaborative behaviors in human- and LLM-generated conversations remains limited, although reproducing these behaviors is integral to simulating human-like and complex social interaction. In this work, we introduce CoCoEval, an evaluation framework that analyzes LLM-simulated conversations by detecting 10 types of inconsistent and uncollaborative behaviors at the turn level using an LLM-as-a-Judge. Using CoCoEval, we evaluate GPT-4.1, GPT-5.1, and Claude Opus 4 by comparing the frequencies of detected behaviors in conversations simulated by each model and in human conversations across academic, business, and governmental meetings, as well as debates. Our analysis shows that (1) under vanilla prompting, LLM-simulated conversations exhibit far fewer inconsistent and uncollaborative behaviors than human conversations; (2) prompt engineering does not provide reliable control over these behaviors, as our results show that different prompts lead to their under- or overproduction; and (3) supervised fine-tuning on human conversations can lead LLMs to overproduce a narrow set of behaviors, such as repetition. Our findings highlight the difficulty of simulating human conversations, raising concerns about the use of LLMs as a proxy for human social interaction.
Experiential Reinforcement Learning
Feb 15, 2026Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
Beyond Output Critique: Self-Correction via Task Distillation
Jan 31, 2026Large language models (LLMs) have shown promising self-correction abilities, where iterative refinement improves the quality of generated responses. However, most existing approaches operate at the level of output critique, patching surface errors while often failing to correct deeper reasoning flaws. We propose SELF-THOUGHT, a framework that introduces an intermediate step of task abstraction before solution refinement. Given an input and an initial response, the model first distills the task into a structured template that captures key variables, constraints, and problem structure. This abstraction then guides solution instantiation, grounding subsequent responses in a clearer understanding of the task and reducing error propagation. Crucially, we show that these abstractions can be transferred across models: templates generated by larger models can serve as structured guides for smaller LLMs, which typically struggle with intrinsic self-correction. By reusing distilled task structures, smaller models achieve more reliable refinements without heavy fine-tuning or reliance on external verifiers. Experiments across diverse reasoning tasks demonstrate that SELF-THOUGHT improves accuracy, robustness, and generalization for both large and small models, offering a scalable path toward more reliable self-correcting language systems.
Conversational User-AI Intervention: A Study on Prompt Rewriting for Improved LLM Response Generation
Mar 21, 2025Human-LLM conversations are increasingly becoming more pervasive in peoples' professional and personal lives, yet many users still struggle to elicit helpful responses from LLM Chatbots. One of the reasons for this issue is users' lack of understanding in crafting effective prompts that accurately convey their information needs. Meanwhile, the existence of real-world conversational datasets on the one hand, and the text understanding faculties of LLMs on the other, present a unique opportunity to study this problem, and its potential solutions at scale. Thus, in this paper we present the first LLM-centric study of real human-AI chatbot conversations, focused on investigating aspects in which user queries fall short of expressing information needs, and the potential of using LLMs to rewrite suboptimal user prompts. Our findings demonstrate that rephrasing ineffective prompts can elicit better responses from a conversational system, while preserving the user's original intent. Notably, the performance of rewrites improves in longer conversations, where contextual inferences about user needs can be made more accurately. Additionally, we observe that LLMs often need to -- and inherently do -- make \emph{plausible} assumptions about a user's intentions and goals when interpreting prompts. Our findings largely hold true across conversational domains, user intents, and LLMs of varying sizes and families, indicating the promise of using prompt rewriting as a solution for better human-AI interactions.
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation
Feb 26, 2025Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024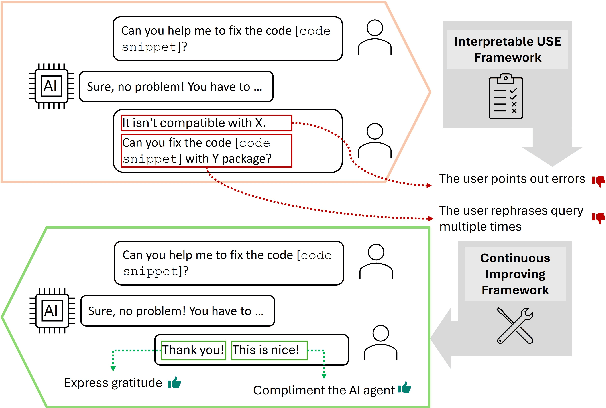
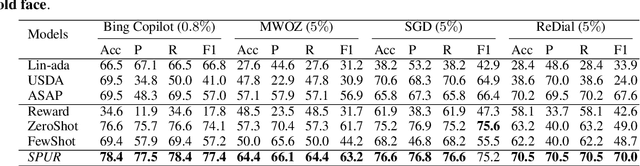
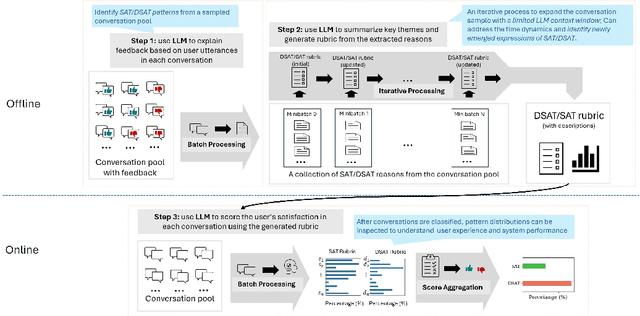
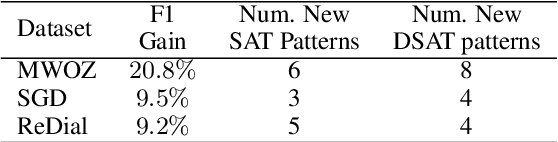
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.