 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
Deep Neural Networks for Query Expansion using Word Embeddings
Nov 08, 2018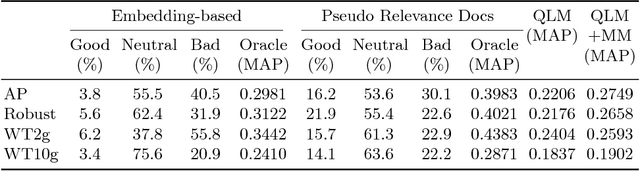
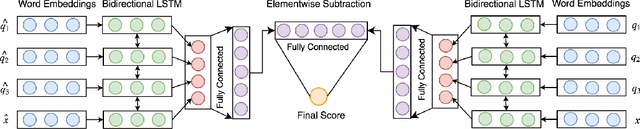

Query expansion is a method for alleviating the vocabulary mismatch problem present in information retrieval tasks. Previous works have shown that terms selected for query expansion by traditional methods such as pseudo-relevance feedback are not always helpful to the retrieval process. In this paper, we show that this is also true for more recently proposed embedding-based query expansion methods. We then introduce an artificial neural network classifier to predict the usefulness of query expansion terms. This classifier uses term word embeddings as inputs. We perform experiments on four TREC newswire and web collections show that using terms selected by the classifier for expansion significantly improves retrieval performance when compared to competitive baselines. The results are also shown to be more robust than the baselines.