 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the LLM Looking Glass: A Socratic Self-Assessment of Donkeys, Elephants, and Markets
Mar 20, 2025While detecting and avoiding bias in LLM-generated text is becoming increasingly important, media bias often remains subtle and subjective, making it particularly difficult to identify and mitigate. In this study, we assess media bias in LLM-generated content and LLMs' ability to detect subtle ideological bias. We conduct this evaluation using two datasets, PoliGen and EconoLex, covering political and economic discourse, respectively. We evaluate eight widely used LLMs by prompting them to generate articles and analyze their ideological preferences via self-assessment. By using self-assessment, the study aims to directly measure the models' biases rather than relying on external interpretations, thereby minimizing subjective judgments about media bias. Our results reveal a consistent preference of Democratic over Republican positions across all models. Conversely, in economic topics, biases vary among Western LLMs, while those developed in China lean more strongly toward socialism.
DeltaLLM: Compress LLMs with Low-Rank Deltas between Shared Weights
Jan 30, 2025We introduce DeltaLLM, a new post-training compression technique to reduce the memory footprint of LLMs. We propose an alternative way of structuring LLMs with weight sharing between layers in subsequent Transformer blocks, along with additional low-rank difference matrices between them. For training, we adopt the progressing module replacement method and show that the lightweight training of the low-rank modules with approximately 30M-40M tokens is sufficient to achieve performance on par with LLMs of comparable sizes trained from scratch. We release the resultant models, DeltaLLAMA and DeltaPHI, with a 12% parameter reduction, retaining 90% of the performance of the base Llama and Phi models on common knowledge and reasoning benchmarks. Our method also outperforms compression techniques JointDrop, LaCo, ShortGPT and SliceGPT with the same number of parameters removed. For example, DeltaPhi 2.9B with a 24% reduction achieves similar average zero-shot accuracies as recovery fine-tuned SlicedPhi 3.3B with a 12% reduction, despite being approximately 400M parameters smaller with no fine-tuning applied. This work provides new insights into LLM architecture design and compression methods when storage space is critical.
How Transliterations Improve Crosslingual Alignment
Sep 25, 2024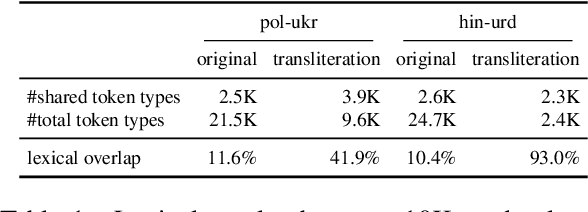

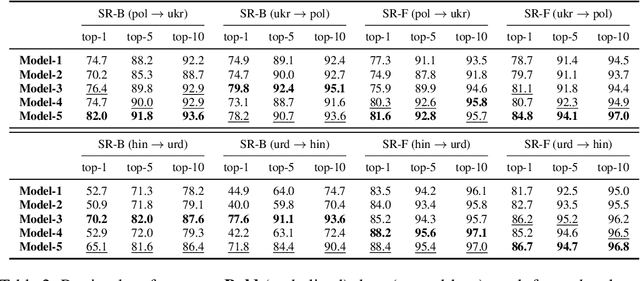

Recent studies have shown that post-aligning multilingual pretrained language models (mPLMs) using alignment objectives on both original and transliterated data can improve crosslingual alignment. This improvement further leads to better crosslingual transfer performance. However, it remains unclear how and why a better crosslingual alignment is achieved, as this technique only involves transliterations, and does not use any parallel data. This paper attempts to explicitly evaluate the crosslingual alignment and identify the key elements in transliteration-based approaches that contribute to better performance. For this, we train multiple models under varying setups for two pairs of related languages: (1) Polish and Ukrainian and (2) Hindi and Urdu. To assess alignment, we define four types of similarities based on sentence representations. Our experiments show that adding transliterations alone improves the overall similarities, even for random sentence pairs. With the help of auxiliary alignment objectives, especially the contrastive objective, the model learns to distinguish matched from random pairs, leading to better alignments. However, we also show that better alignment does not always yield better downstream performance, suggesting that further research is needed to clarify the connection between alignment and performance.
MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Apr 17, 2024



While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $\unicode{x2013}$ though non-parametric $\unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
GlotLID: Language Identification for Low-Resource Languages
Nov 04, 2023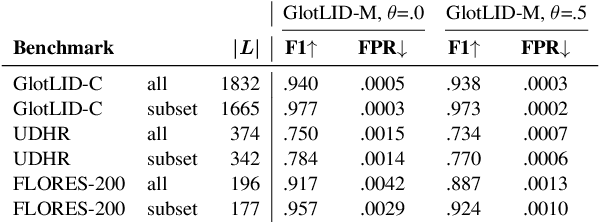



Several recent papers have published good solutions for language identification (LID) for about 300 high-resource and medium-resource languages. However, there is no LID available that (i) covers a wide range of low-resource languages, (ii) is rigorously evaluated and reliable and (iii) efficient and easy to use. Here, we publish GlotLID-M, an LID model that satisfies the desiderata of wide coverage, reliability and efficiency. It identifies 1665 languages, a large increase in coverage compared to prior work. In our experiments, GlotLID-M outperforms four baselines (CLD3, FT176, OpenLID and NLLB) when balancing F1 and false positive rate (FPR). We analyze the unique challenges that low-resource LID poses: incorrect corpus metadata, leakage from high-resource languages, difficulty separating closely related languages, handling of macrolanguage vs varieties and in general noisy data. We hope that integrating GlotLID-M into dataset creation pipelines will improve quality and enhance accessibility of NLP technology for low-resource languages and cultures. GlotLID-M model, code, and list of data sources are available: https://github.com/cisnlp/GlotLID.
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages
May 26, 2023



The NLP community has mainly focused on scaling Large Language Models (LLMs) vertically, i.e., making them better for about 100 languages. We instead scale LLMs horizontally: we create, through continued pretraining, Glot500-m, an LLM that covers 511 predominantly low-resource languages. An important part of this effort is to collect and clean Glot500-c, a corpus that covers these 511 languages and allows us to train Glot500-m. We evaluate Glot500-m on five diverse tasks across these languages. We observe large improvements for both high-resource and low-resource languages compared to an XLM-R baseline. Our analysis shows that no single factor explains the quality of multilingual LLM representations. Rather, a combination of factors determines quality including corpus size, script, "help" from related languages and the total capacity of the model. Our work addresses an important goal of NLP research: we should not limit NLP to a small fraction of the world's languages and instead strive to support as many languages as possible to bring the benefits of NLP technology to all languages and cultures. Code, data and models are available at https://github.com/cisnlp/Glot500.
RET-LLM: Towards a General Read-Write Memory for Large Language Models
May 23, 2023



Large language models (LLMs) have significantly advanced the field of natural language processing (NLP) through their extensive parameters and comprehensive data utilization. However, existing LLMs lack a dedicated memory unit, limiting their ability to explicitly store and retrieve knowledge for various tasks. In this paper, we propose RET-LLM a novel framework that equips LLMs with a general write-read memory unit, allowing them to extract, store, and recall knowledge from the text as needed for task performance. Inspired by Davidsonian semantics theory, we extract and save knowledge in the form of triplets. The memory unit is designed to be scalable, aggregatable, updatable, and interpretable. Through qualitative evaluations, we demonstrate the superiority of our proposed framework over baseline approaches in question answering tasks. Moreover, our framework exhibits robust performance in handling temporal-based question answering tasks, showcasing its ability to effectively manage time-dependent information.
Graph-Based Multilingual Label Propagation for Low-Resource Part-of-Speech Tagging
Oct 18, 2022



Part-of-Speech (POS) tagging is an important component of the NLP pipeline, but many low-resource languages lack labeled data for training. An established method for training a POS tagger in such a scenario is to create a labeled training set by transferring from high-resource languages. In this paper, we propose a novel method for transferring labels from multiple high-resource source to low-resource target languages. We formalize POS tag projection as graph-based label propagation. Given translations of a sentence in multiple languages, we create a graph with words as nodes and alignment links as edges by aligning words for all language pairs. We then propagate node labels from source to target using a Graph Neural Network augmented with transformer layers. We show that our propagation creates training sets that allow us to train POS taggers for a diverse set of languages. When combined with enhanced contextualized embeddings, our method achieves a new state-of-the-art for unsupervised POS tagging of low-resource languages.
$Λ$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells
Oct 14, 2022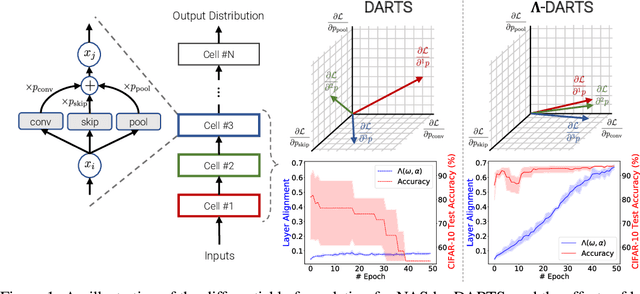
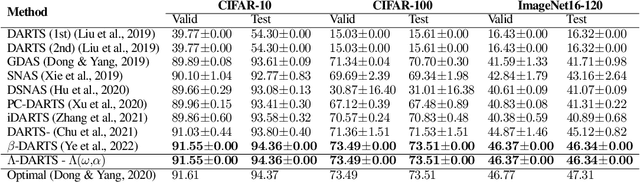

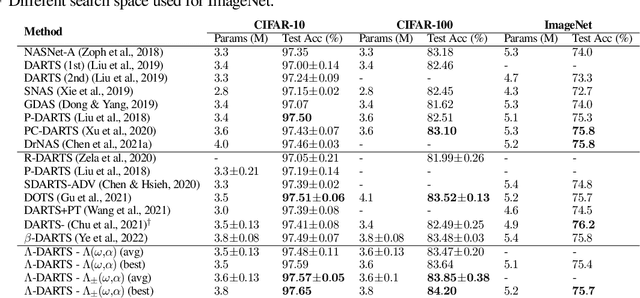
Differentiable neural architecture search (DARTS) is a popular method for neural architecture search (NAS), which performs cell-search and utilizes continuous relaxation to improve the search efficiency via gradient-based optimization. The main shortcoming of DARTS is performance collapse, where the discovered architecture suffers from a pattern of declining quality during search. Performance collapse has become an important topic of research, with many methods trying to solve the issue through either regularization or fundamental changes to DARTS. However, the weight-sharing framework used for cell-search in DARTS and the convergence of architecture parameters has not been analyzed yet. In this paper, we provide a thorough and novel theoretical and empirical analysis on DARTS and its point of convergence. We show that DARTS suffers from a specific structural flaw due to its weight-sharing framework that limits the convergence of DARTS to saturation points of the softmax function. This point of convergence gives an unfair advantage to layers closer to the output in choosing the optimal architecture, causing performance collapse. We then propose two new regularization terms that aim to prevent performance collapse by harmonizing operation selection via aligning gradients of layers. Experimental results on six different search spaces and three different datasets show that our method ($\Lambda$-DARTS) does indeed prevent performance collapse, providing justification for our theoretical analysis and the proposed remedy.
Graph Neural Networks for Multiparallel Word Alignment
Mar 16, 2022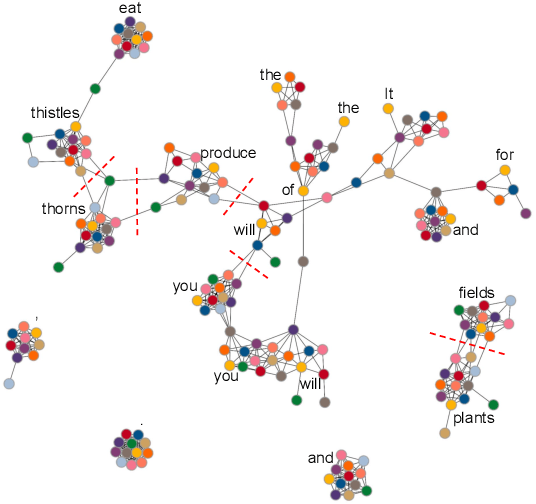
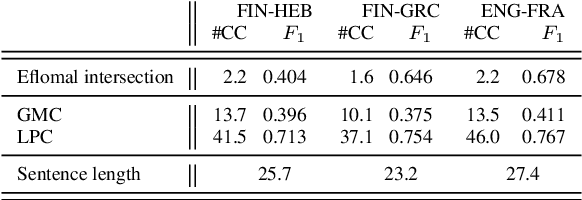
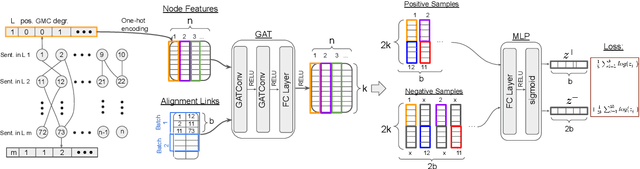

After a period of decrease, interest in word alignments is increasing again for their usefulness in domains such as typological research, cross-lingual annotation projection, and machine translation. Generally, alignment algorithms only use bitext and do not make use of the fact that many parallel corpora are multiparallel. Here, we compute high-quality word alignments between multiple language pairs by considering all language pairs together. First, we create a multiparallel word alignment graph, joining all bilingual word alignment pairs in one graph. Next, we use graph neural networks (GNNs) to exploit the graph structure. Our GNN approach (i) utilizes information about the meaning, position, and language of the input words, (ii) incorporates information from multiple parallel sentences, (iii) adds and removes edges from the initial alignments, and (iv) yields a prediction model that can generalize beyond the training sentences. We show that community detection provides valuable information for multiparallel word alignment. Our method outperforms previous work on three word-alignment datasets and on a downstream task.