 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDef: Automating Definition Extraction from Academic Literature with Large Language Models
Feb 05, 2026Definitions are the foundation for any scientific work, but with a significant increase in publication numbers, gathering definitions relevant to any keyword has become challenging. We therefore introduce SciDef, an LLM-based pipeline for automated definition extraction. We test SciDef on DefExtra & DefSim, novel datasets of human-extracted definitions and definition-pairs' similarity, respectively. Evaluating 16 language models across prompting strategies, we demonstrate that multi-step and DSPy-optimized prompting improve extraction performance. To evaluate extraction, we test various metrics and show that an NLI-based method yields the most reliable results. We show that LLMs are largely able to extract definitions from scientific literature (86.4% of definitions from our test-set); yet future work should focus not just on finding definitions, but on identifying relevant ones, as models tend to over-generate them. Code & datasets are available at https://github.com/Media-Bias-Group/SciDef.
Through the LLM Looking Glass: A Socratic Self-Assessment of Donkeys, Elephants, and Markets
Mar 20, 2025While detecting and avoiding bias in LLM-generated text is becoming increasingly important, media bias often remains subtle and subjective, making it particularly difficult to identify and mitigate. In this study, we assess media bias in LLM-generated content and LLMs' ability to detect subtle ideological bias. We conduct this evaluation using two datasets, PoliGen and EconoLex, covering political and economic discourse, respectively. We evaluate eight widely used LLMs by prompting them to generate articles and analyze their ideological preferences via self-assessment. By using self-assessment, the study aims to directly measure the models' biases rather than relying on external interpretations, thereby minimizing subjective judgments about media bias. Our results reveal a consistent preference of Democratic over Republican positions across all models. Conversely, in economic topics, biases vary among Western LLMs, while those developed in China lean more strongly toward socialism.
The Promises and Pitfalls of LLM Annotations in Dataset Labeling: a Case Study on Media Bias Detection
Nov 17, 2024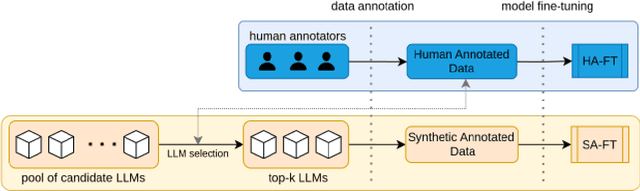
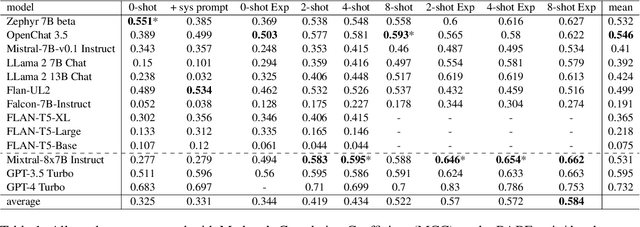
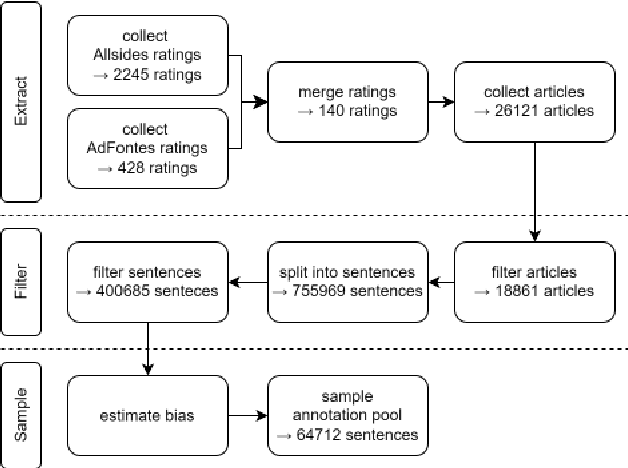
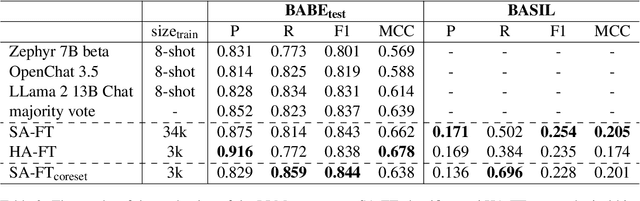
High annotation costs from hiring or crowdsourcing complicate the creation of large, high-quality datasets needed for training reliable text classifiers. Recent research suggests using Large Language Models (LLMs) to automate the annotation process, reducing these costs while maintaining data quality. LLMs have shown promising results in annotating downstream tasks like hate speech detection and political framing. Building on the success in these areas, this study investigates whether LLMs are viable for annotating the complex task of media bias detection and whether a downstream media bias classifier can be trained on such data. We create annolexical, the first large-scale dataset for media bias classification with over 48000 synthetically annotated examples. Our classifier, fine-tuned on this dataset, surpasses all of the annotator LLMs by 5-9 percent in Matthews Correlation Coefficient (MCC) and performs close to or outperforms the model trained on human-labeled data when evaluated on two media bias benchmark datasets (BABE and BASIL). This study demonstrates how our approach significantly reduces the cost of dataset creation in the media bias domain and, by extension, the development of classifiers, while our subsequent behavioral stress-testing reveals some of its current limitations and trade-offs.
The Media Bias Taxonomy: A Systematic Literature Review on the Forms and Automated Detection of Media Bias
Jan 10, 2024
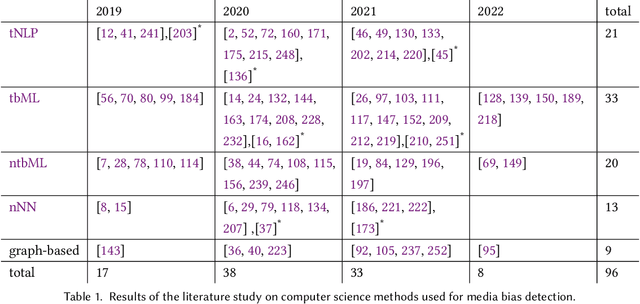

The way the media presents events can significantly affect public perception, which in turn can alter people's beliefs and views. Media bias describes a one-sided or polarizing perspective on a topic. This article summarizes the research on computational methods to detect media bias by systematically reviewing 3140 research papers published between 2019 and 2022. To structure our review and support a mutual understanding of bias across research domains, we introduce the Media Bias Taxonomy, which provides a coherent overview of the current state of research on media bias from different perspectives. We show that media bias detection is a highly active research field, in which transformer-based classification approaches have led to significant improvements in recent years. These improvements include higher classification accuracy and the ability to detect more fine-granular types of bias. However, we have identified a lack of interdisciplinarity in existing projects, and a need for more awareness of the various types of media bias to support methodologically thorough performance evaluations of media bias detection systems. Concluding from our analysis, we see the integration of recent machine learning advancements with reliable and diverse bias assessment strategies from other research areas as the most promising area for future research contributions in the field.
Introducing MBIB -- the first Media Bias Identification Benchmark Task and Dataset Collection
Apr 25, 2023

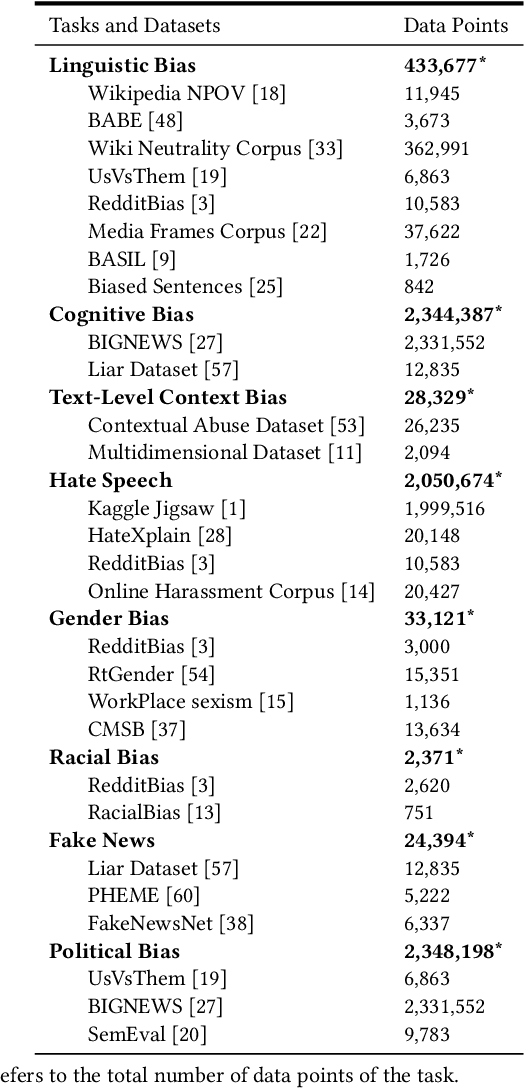
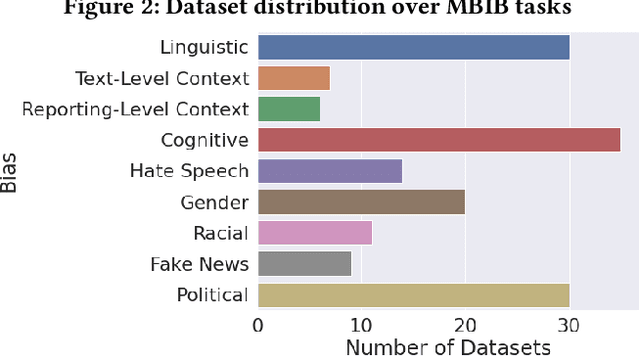
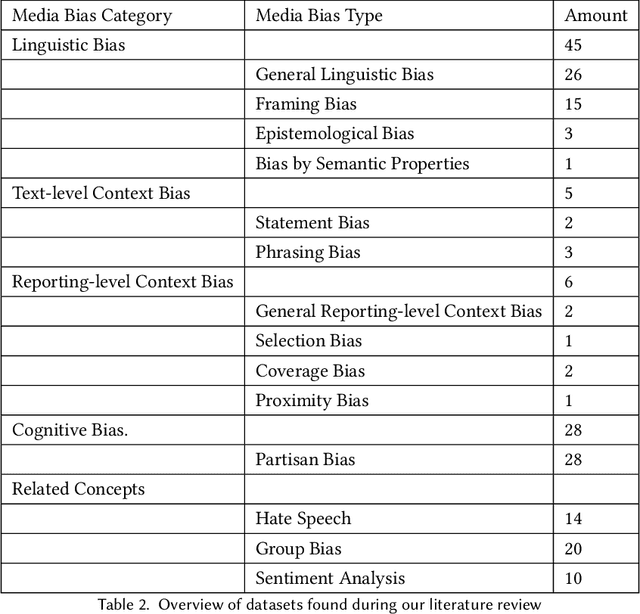
Although media bias detection is a complex multi-task problem, there is, to date, no unified benchmark grouping these evaluation tasks. We introduce the Media Bias Identification Benchmark (MBIB), a comprehensive benchmark that groups different types of media bias (e.g., linguistic, cognitive, political) under a common framework to test how prospective detection techniques generalize. After reviewing 115 datasets, we select nine tasks and carefully propose 22 associated datasets for evaluating media bias detection techniques. We evaluate MBIB using state-of-the-art Transformer techniques (e.g., T5, BART). Our results suggest that while hate speech, racial bias, and gender bias are easier to detect, models struggle to handle certain bias types, e.g., cognitive and political bias. However, our results show that no single technique can outperform all the others significantly. We also find an uneven distribution of research interest and resource allocation to the individual tasks in media bias. A unified benchmark encourages the development of more robust systems and shifts the current paradigm in media bias detection evaluation towards solutions that tackle not one but multiple media bias types simultaneously.
A Benchmark of PDF Information Extraction Tools using a Multi-Task and Multi-Domain Evaluation Framework for Academic Documents
Mar 17, 2023Extracting information from academic PDF documents is crucial for numerous indexing, retrieval, and analysis use cases. Choosing the best tool to extract specific content elements is difficult because many, technically diverse tools are available, but recent performance benchmarks are rare. Moreover, such benchmarks typically cover only a few content elements like header metadata or bibliographic references and use smaller datasets from specific academic disciplines. We provide a large and diverse evaluation framework that supports more extraction tasks than most related datasets. Our framework builds upon DocBank, a multi-domain dataset of 1.5M annotated content elements extracted from 500K pages of research papers on arXiv. Using the new framework, we benchmark ten freely available tools in extracting document metadata, bibliographic references, tables, and other content elements from academic PDF documents. GROBID achieves the best metadata and reference extraction results, followed by CERMINE and Science Parse. For table extraction, Adobe Extract outperforms other tools, even though the performance is much lower than for other content elements. All tools struggle to extract lists, footers, and equations. We conclude that more research on improving and combining tools is necessary to achieve satisfactory extraction quality for most content elements. Evaluation datasets and frameworks like the one we present support this line of research. We make our data and code publicly available to contribute toward this goal.
Exploiting Transformer-based Multitask Learning for the Detection of Media Bias in News Articles
Nov 07, 2022Media has a substantial impact on the public perception of events. A one-sided or polarizing perspective on any topic is usually described as media bias. One of the ways how bias in news articles can be introduced is by altering word choice. Biased word choices are not always obvious, nor do they exhibit high context-dependency. Hence, detecting bias is often difficult. We propose a Transformer-based deep learning architecture trained via Multi-Task Learning using six bias-related data sets to tackle the media bias detection problem. Our best-performing implementation achieves a macro $F_{1}$ of 0.776, a performance boost of 3\% compared to our baseline, outperforming existing methods. Our results indicate Multi-Task Learning as a promising alternative to improve existing baseline models in identifying slanted reporting.
Neural Media Bias Detection Using Distant Supervision With BABE -- Bias Annotations By Experts
Sep 29, 2022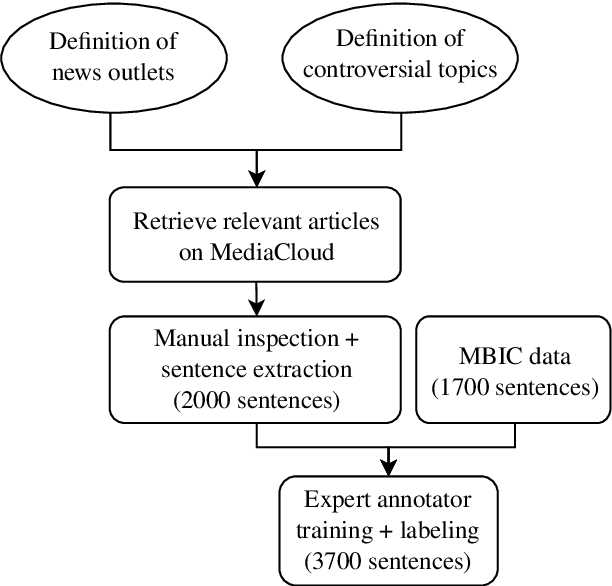
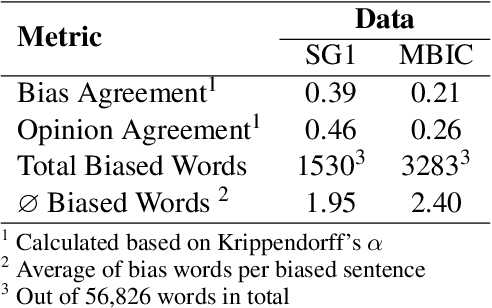
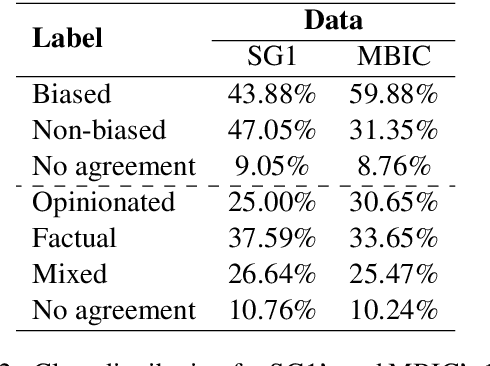
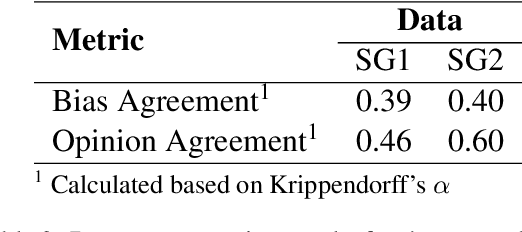
Media coverage has a substantial effect on the public perception of events. Nevertheless, media outlets are often biased. One way to bias news articles is by altering the word choice. The automatic identification of bias by word choice is challenging, primarily due to the lack of a gold standard data set and high context dependencies. This paper presents BABE, a robust and diverse data set created by trained experts, for media bias research. We also analyze why expert labeling is essential within this domain. Our data set offers better annotation quality and higher inter-annotator agreement than existing work. It consists of 3,700 sentences balanced among topics and outlets, containing media bias labels on the word and sentence level. Based on our data, we also introduce a way to detect bias-inducing sentences in news articles automatically. Our best performing BERT-based model is pre-trained on a larger corpus consisting of distant labels. Fine-tuning and evaluating the model on our proposed supervised data set, we achieve a macro F1-score of 0.804, outperforming existing methods.
* arXiv admin note: substantial text overlap with arXiv:2112.13352
A Domain-adaptive Pre-training Approach for Language Bias Detection in News
May 22, 2022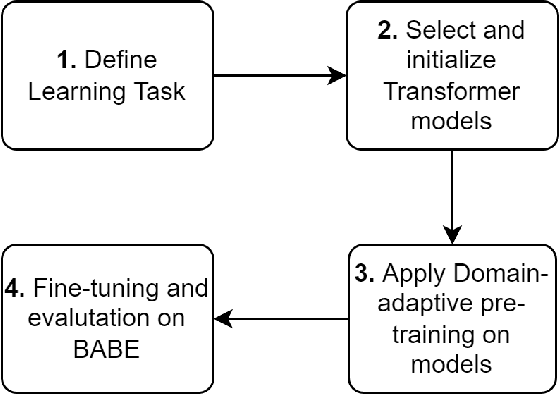

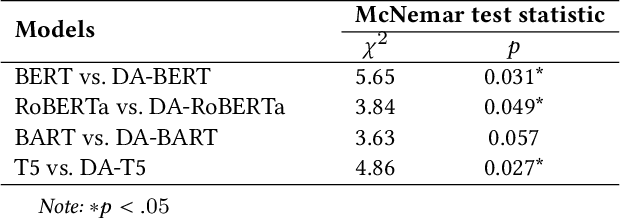
Media bias is a multi-faceted construct influencing individual behavior and collective decision-making. Slanted news reporting is the result of one-sided and polarized writing which can occur in various forms. In this work, we focus on an important form of media bias, i.e. bias by word choice. Detecting biased word choices is a challenging task due to its linguistic complexity and the lack of representative gold-standard corpora. We present DA-RoBERTa, a new state-of-the-art transformer-based model adapted to the media bias domain which identifies sentence-level bias with an F1 score of 0.814. In addition, we also train, DA-BERT and DA-BART, two more transformer models adapted to the bias domain. Our proposed domain-adapted models outperform prior bias detection approaches on the same data.
An Interdisciplinary Approach for the Automated Detection and Visualization of Media Bias in News Articles
Dec 26, 2021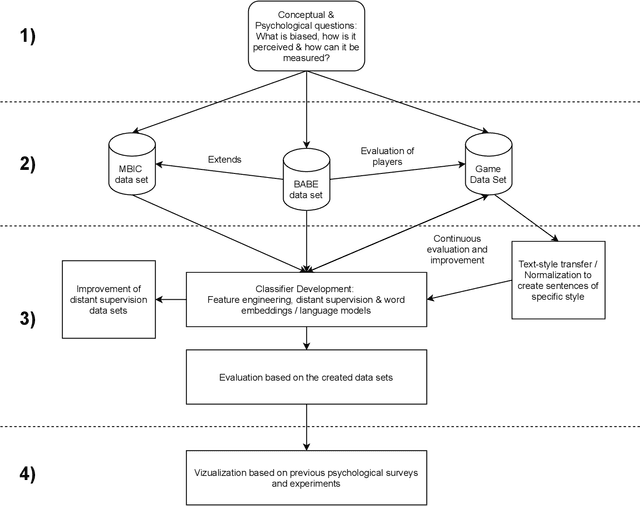
Media coverage has a substantial effect on the public perception of events. Nevertheless, media outlets are often biased. One way to bias news articles is by altering the word choice. The automatic identification of bias by word choice is challenging, primarily due to the lack of gold-standard data sets and high context dependencies. In this research project, I aim to devise data sets and methods to identify media bias. To achieve this, I plan to research methods using natural language processing and deep learning while employing models and using analysis concepts from psychology and linguistics. The first results indicate the effectiveness of an interdisciplinary research approach. My vision is to devise a system that helps news readers become aware of media coverage differences caused by bias. So far, my best performing BERT-based model is pre-trained on a larger corpus consisting of distant labels, indicating that distant supervision has the potential to become a solution for the difficult task of bias detection.