 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebFAQ 2.0: A Multilingual QA Dataset with Mined Hard Negatives for Dense Retrieval
Feb 19, 2026We introduce WebFAQ 2.0, a new version of the WebFAQ dataset, containing 198 million FAQ-based natural question-answer pairs across 108 languages. Compared to the previous version, it significantly expands multilingual coverage and the number of bilingual aligned QA pairs to over 14.3M, making it the largest FAQ-based resource. Unlike the original release, WebFAQ 2.0 uses a novel data collection strategy that directly crawls and extracts relevant web content, resulting in a substantially more diverse and multilingual dataset with richer context through page titles and descriptions. In response to community feedback, we also release a hard negatives dataset for training dense retrievers, with 1.25M queries across 20 languages. These hard negatives were mined using a two-stage retrieval pipeline and include cross-encoder scores for 200 negatives per query. We further show how this resource enables two primary fine-tuning strategies for dense retrievers: Contrastive Learning with MultipleNegativesRanking loss, and Knowledge Distillation with MarginMSE loss. WebFAQ 2.0 is not a static resource but part of a long-term effort. Since late 2025, structured FAQs are being regularly released through the Open Web Index, enabling continuous expansion and refinement. We publish the datasets and training scripts to facilitate further research in multilingual and cross-lingual IR. The dataset itself and all related resources are publicly available on GitHub and HuggingFace.
WebFAQ: A Multilingual Collection of Natural Q&A Datasets for Dense Retrieval
Feb 28, 2025



We present WebFAQ, a large-scale collection of open-domain question answering datasets derived from FAQ-style schema.org annotations. In total, the data collection consists of 96 million natural question-answer (QA) pairs across 75 languages, including 47 million (49%) non-English samples. WebFAQ further serves as the foundation for 20 monolingual retrieval benchmarks with a total size of 11.2 million QA pairs (5.9 million non-English). These datasets are carefully curated through refined filtering and near-duplicate detection, yielding high-quality resources for training and evaluating multilingual dense retrieval models. To empirically confirm WebFAQ's efficacy, we use the collected QAs to fine-tune an in-domain pretrained XLM-RoBERTa model. Through this process of dataset-specific fine-tuning, the model achieves significant retrieval performance gains, which generalize - beyond WebFAQ - to other multilingual retrieval benchmarks evaluated in zero-shot setting. Last but not least, we utilize WebFAQ to construct a set of QA-aligned bilingual corpora spanning over 1000 language pairs using state-of-the-art bitext mining and automated LLM-assessed translation evaluation. Due to our advanced, automated method of bitext dataset generation, the resulting bilingual corpora demonstrate higher translation quality compared to similar datasets. WebFAQ and all associated resources are publicly available on GitHub and HuggingFace.
Enhancing Rhetorical Figure Annotation: An Ontology-Based Web Application with RAG Integration
Dec 18, 2024
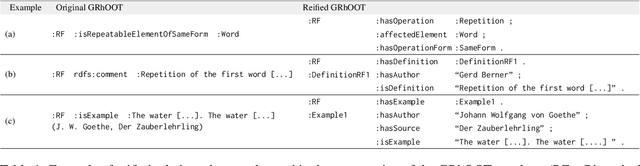


Rhetorical figures play an important role in our communication. They are used to convey subtle, implicit meaning, or to emphasize statements. We notice them in hate speech, fake news, and propaganda. By improving the systems for computational detection of rhetorical figures, we can also improve tasks such as hate speech and fake news detection, sentiment analysis, opinion mining, or argument mining. Unfortunately, there is a lack of annotated data, as well as qualified annotators that would help us build large corpora to train machine learning models for the detection of rhetorical figures. The situation is particularly difficult in languages other than English, and for rhetorical figures other than metaphor, sarcasm, and irony. To overcome this issue, we develop a web application called "Find your Figure" that facilitates the identification and annotation of German rhetorical figures. The application is based on the German Rhetorical ontology GRhOOT which we have specially adapted for this purpose. In addition, we improve the user experience with Retrieval Augmented Generation (RAG). In this paper, we present the restructuring of the ontology, the development of the web application, and the built-in RAG pipeline. We also identify the optimal RAG settings for our application. Our approach is one of the first to practically use rhetorical ontologies in combination with RAG and shows promising results.
Computational Approaches to the Detection of Lesser-Known Rhetorical Figures: A Systematic Survey and Research Challenges
Jun 24, 2024Rhetorical figures play a major role in our everyday communication as they make text more interesting, more memorable, or more persuasive. Therefore, it is important to computationally detect rhetorical figures to fully understand the meaning of a text. We provide a comprehensive overview of computational approaches to lesser-known rhetorical figures. We explore the linguistic and computational perspectives on rhetorical figures, emphasizing their significance for the domain of Natural Language Processing. We present different figures in detail, delving into datasets, definitions, rhetorical functions, and detection approaches. We identified challenges such as dataset scarcity, language limitations, and reliance on rule-based methods.
Impact of Position Bias on Language Models in Token Classification
Apr 26, 2023Language Models (LMs) have shown state-of-the-art performance in Natural Language Processing (NLP) tasks. Downstream tasks such as Named Entity Recognition (NER) or Part-of-Speech (POS) tagging are known to suffer from data imbalance issues, specifically in terms of the ratio of positive to negative examples, and class imbalance. In this paper, we investigate an additional specific issue for language models, namely the position bias of positive examples in token classification tasks. Therefore, we conduct an in-depth evaluation of the impact of position bias on the performance of LMs when fine-tuned on Token Classification benchmarks. Our study includes CoNLL03 and OntoNote5.0 for NER, English Tree Bank UD_en and TweeBank for POS tagging. We propose an evaluation approach to investigate position bias in Transformer models. We show that encoders like BERT, ERNIE, ELECTRA, and decoders such as GPT2 and BLOOM can suffer from this bias with an average drop of 3\% and 9\% in their performance. To mitigate this effect, we propose two methods: Random Position Shifting and Context Perturbation, that we apply on batches during the training process. The results show an improvement of $\approx$ 2\% in the performance of the model on CoNLL03, UD_en, and TweeBank.
A Benchmark of PDF Information Extraction Tools using a Multi-Task and Multi-Domain Evaluation Framework for Academic Documents
Mar 17, 2023Extracting information from academic PDF documents is crucial for numerous indexing, retrieval, and analysis use cases. Choosing the best tool to extract specific content elements is difficult because many, technically diverse tools are available, but recent performance benchmarks are rare. Moreover, such benchmarks typically cover only a few content elements like header metadata or bibliographic references and use smaller datasets from specific academic disciplines. We provide a large and diverse evaluation framework that supports more extraction tasks than most related datasets. Our framework builds upon DocBank, a multi-domain dataset of 1.5M annotated content elements extracted from 500K pages of research papers on arXiv. Using the new framework, we benchmark ten freely available tools in extracting document metadata, bibliographic references, tables, and other content elements from academic PDF documents. GROBID achieves the best metadata and reference extraction results, followed by CERMINE and Science Parse. For table extraction, Adobe Extract outperforms other tools, even though the performance is much lower than for other content elements. All tools struggle to extract lists, footers, and equations. We conclude that more research on improving and combining tools is necessary to achieve satisfactory extraction quality for most content elements. Evaluation datasets and frameworks like the one we present support this line of research. We make our data and code publicly available to contribute toward this goal.
German BERT Model for Legal Named Entity Recognition
Mar 07, 2023



The use of BERT, one of the most popular language models, has led to improvements in many Natural Language Processing (NLP) tasks. One such task is Named Entity Recognition (NER) i.e. automatic identification of named entities such as location, person, organization, etc. from a given text. It is also an important base step for many NLP tasks such as information extraction and argumentation mining. Even though there is much research done on NER using BERT and other popular language models, the same is not explored in detail when it comes to Legal NLP or Legal Tech. Legal NLP applies various NLP techniques such as sentence similarity or NER specifically on legal data. There are only a handful of models for NER tasks using BERT language models, however, none of these are aimed at legal documents in German. In this paper, we fine-tune a popular BERT language model trained on German data (German BERT) on a Legal Entity Recognition (LER) dataset. To make sure our model is not overfitting, we performed a stratified 10-fold cross-validation. The results we achieve by fine-tuning German BERT on the LER dataset outperform the BiLSTM-CRF+ model used by the authors of the same LER dataset. Finally, we make the model openly available via HuggingFace.
* Presented at ICAART 2023
Exploiting Transformer-based Multitask Learning for the Detection of Media Bias in News Articles
Nov 07, 2022Media has a substantial impact on the public perception of events. A one-sided or polarizing perspective on any topic is usually described as media bias. One of the ways how bias in news articles can be introduced is by altering word choice. Biased word choices are not always obvious, nor do they exhibit high context-dependency. Hence, detecting bias is often difficult. We propose a Transformer-based deep learning architecture trained via Multi-Task Learning using six bias-related data sets to tackle the media bias detection problem. Our best-performing implementation achieves a macro $F_{1}$ of 0.776, a performance boost of 3\% compared to our baseline, outperforming existing methods. Our results indicate Multi-Task Learning as a promising alternative to improve existing baseline models in identifying slanted reporting.
HateBERT: Retraining BERT for Abusive Language Detection in English
Oct 23, 2020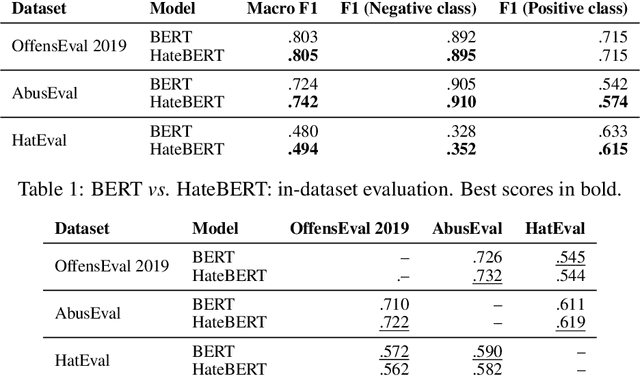

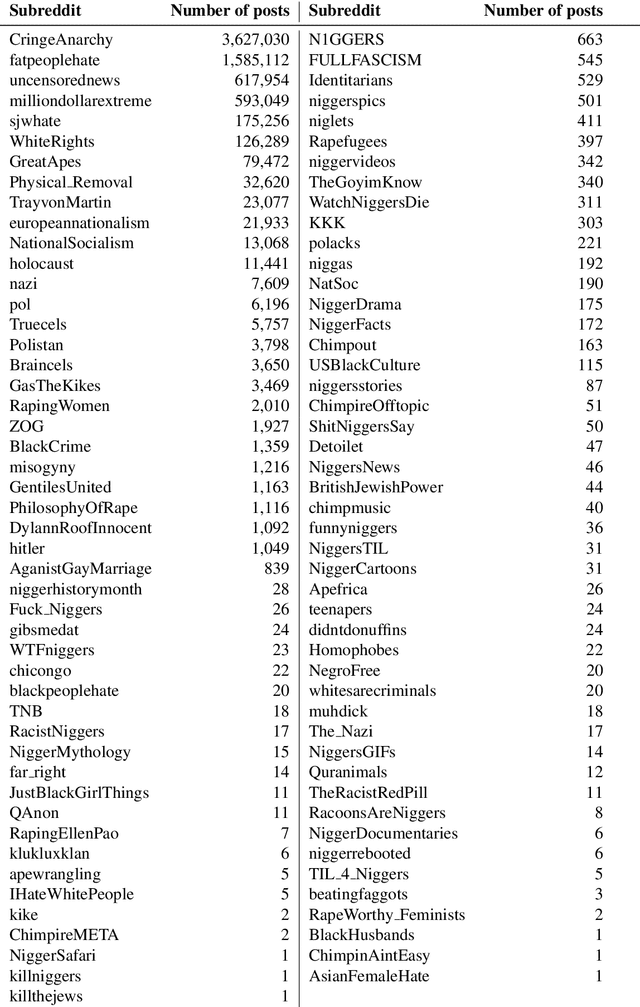
In this paper, we introduce HateBERT, a re-trained BERT model for abusive language detection in English. The model was trained on RAL-E, a large-scale dataset of Reddit comments in English from communities banned for being offensive, abusive, or hateful that we have collected and made available to the public. We present the results of a detailed comparison between a general pre-trained language model and the abuse-inclined version obtained by retraining with posts from the banned communities on three English datasets for offensive, abusive language and hate speech detection tasks. In all datasets, HateBERT outperforms the corresponding general BERT model. We also discuss a battery of experiments comparing the portability of the general pre-trained language model and its corresponding abusive language-inclined counterpart across the datasets, indicating that portability is affected by compatibility of the annotated phenomena.