 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Nov 16, 2023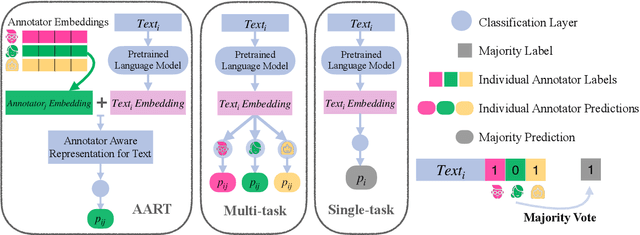
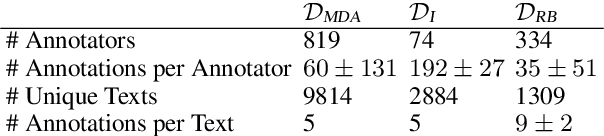
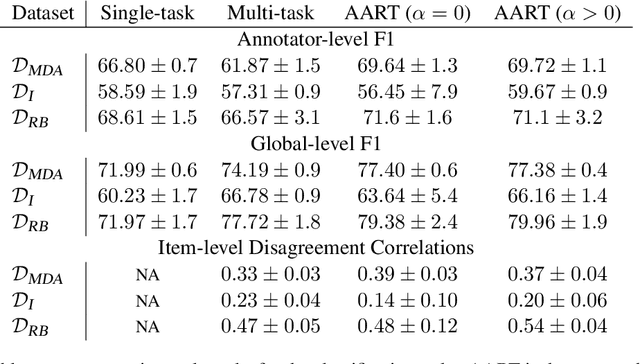
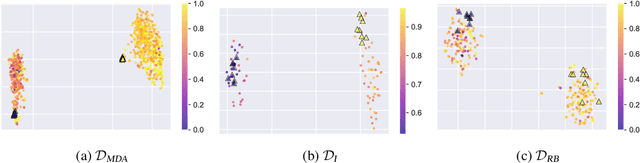
In most classification models, it has been assumed to have a single ground truth label for each data point. However, subjective tasks like toxicity classification can lead to genuine disagreement among annotators. In these cases aggregating labels will result in biased labeling and, consequently, biased models that can overlook minority opinions. Previous studies have shed light on the pitfalls of label aggregation and have introduced a handful of practical approaches to tackle this issue. Recently proposed multi-annotator models, which predict labels individually per annotator, are vulnerable to under-determination for annotators with small samples. This problem is especially the case in crowd-sourced datasets. In this work, we propose Annotator Aware Representations for Texts (AART) for subjective classification tasks. We will show the improvement of our method on metrics that assess the performance on capturing annotators' perspectives. Additionally, our approach involves learning representations for annotators, allowing for an exploration of the captured annotation behaviors.
SemEval-2023 Task 11: Learning With Disagreements (LeWiDi)
Apr 28, 2023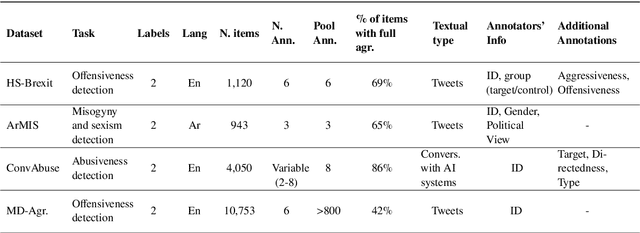
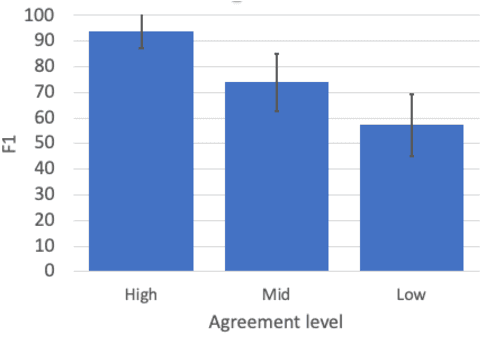
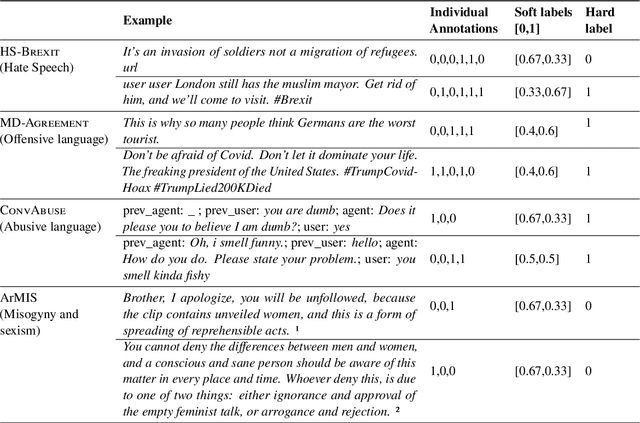
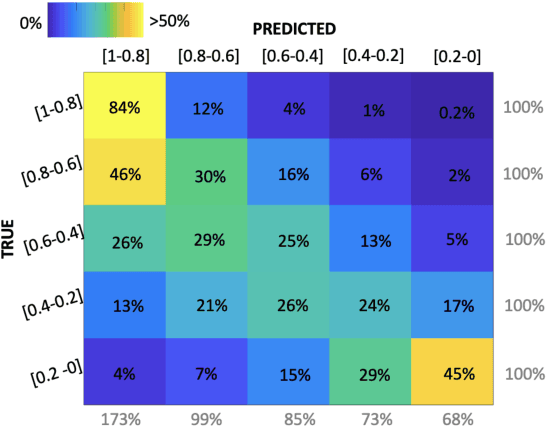
NLP datasets annotated with human judgments are rife with disagreements between the judges. This is especially true for tasks depending on subjective judgments such as sentiment analysis or offensive language detection. Particularly in these latter cases, the NLP community has come to realize that the approach of 'reconciling' these different subjective interpretations is inappropriate. Many NLP researchers have therefore concluded that rather than eliminating disagreements from annotated corpora, we should preserve them-indeed, some argue that corpora should aim to preserve all annotator judgments. But this approach to corpus creation for NLP has not yet been widely accepted. The objective of the LeWiDi series of shared tasks is to promote this approach to developing NLP models by providing a unified framework for training and evaluating with such datasets. We report on the second LeWiDi shared task, which differs from the first edition in three crucial respects: (i) it focuses entirely on NLP, instead of both NLP and computer vision tasks in its first edition; (ii) it focuses on subjective tasks, instead of covering different types of disagreements-as training with aggregated labels for subjective NLP tasks is a particularly obvious misrepresentation of the data; and (iii) for the evaluation, we concentrate on soft approaches to evaluation. This second edition of LeWiDi attracted a wide array of participants resulting in 13 shared task submission papers.
O-Dang! The Ontology of Dangerous Speech Messages
Jul 13, 2022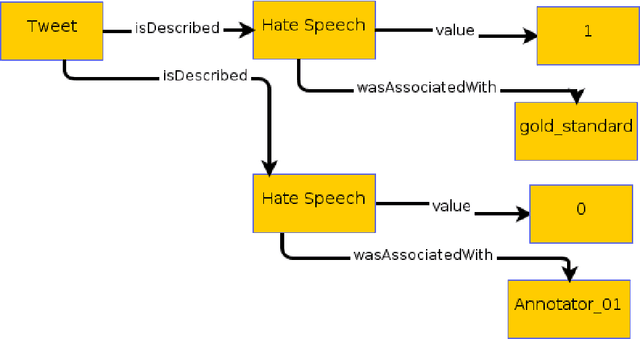
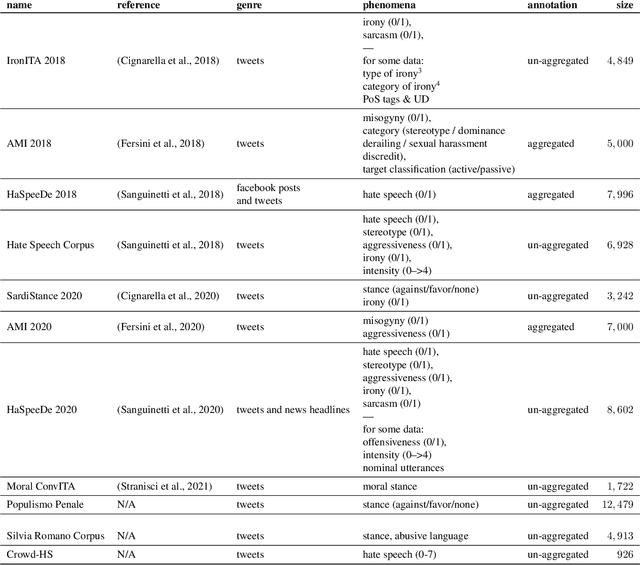
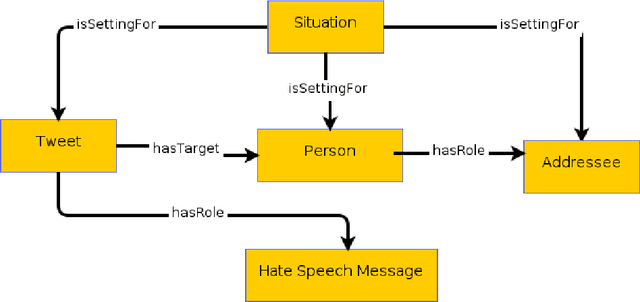
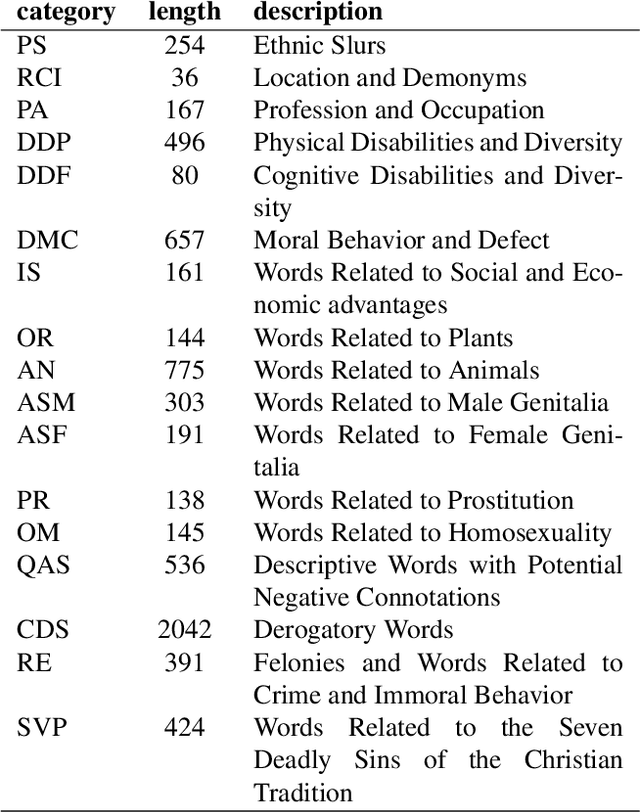
Inside the NLP community there is a considerable amount of language resources created, annotated and released every day with the aim of studying specific linguistic phenomena. Despite a variety of attempts in order to organize such resources has been carried on, a lack of systematic methods and of possible interoperability between resources are still present. Furthermore, when storing linguistic information, still nowadays, the most common practice is the concept of "gold standard", which is in contrast with recent trends in NLP that aim at stressing the importance of different subjectivities and points of view when training machine learning and deep learning methods. In this paper we present O-Dang!: The Ontology of Dangerous Speech Messages, a systematic and interoperable Knowledge Graph (KG) for the collection of linguistic annotated data. O-Dang! is designed to gather and organize Italian datasets into a structured KG, according to the principles shared within the Linguistic Linked Open Data community. The ontology has also been designed to account for a perspectivist approach, since it provides a model for encoding both gold standard and single-annotator labels in the KG. The paper is structured as follows. In Section 1 the motivations of our work are outlined. Section 2 describes the O-Dang! Ontology, that provides a common semantic model for the integration of datasets in the KG. The Ontology Population stage with information about corpora, users, and annotations is presented in Section 3. Finally, in Section 4 an analysis of offensiveness across corpora is provided as a first case study for the resource.
APPReddit: a Corpus of Reddit Posts Annotated for Appraisal
May 31, 2022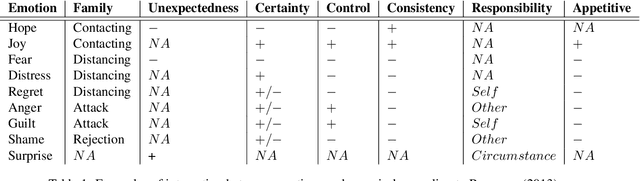
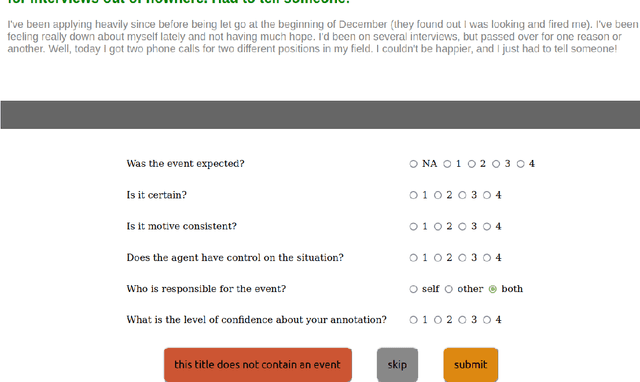

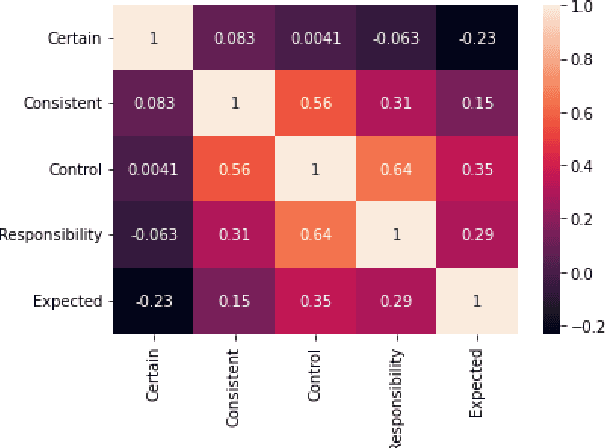
Despite the large number of computational resources for emotion recognition, there is a lack of data sets relying on appraisal models. According to Appraisal theories, emotions are the outcome of a multi-dimensional evaluation of events. In this paper, we present APPReddit, the first corpus of non-experimental data annotated according to this theory. After describing its development, we compare our resource with enISEAR, a corpus of events created in an experimental setting and annotated for appraisal. Results show that the two corpora can be mapped notwithstanding different typologies of data and annotations schemes. A SVM model trained on APPReddit predicts four appraisal dimensions without significant loss. Merging both corpora in a single training set increases the prediction of 3 out of 4 dimensions. Such findings pave the way to a better performing classification model for appraisal prediction.
Local Multi-Head Channel Self-Attention for Facial Expression Recognition
Nov 18, 2021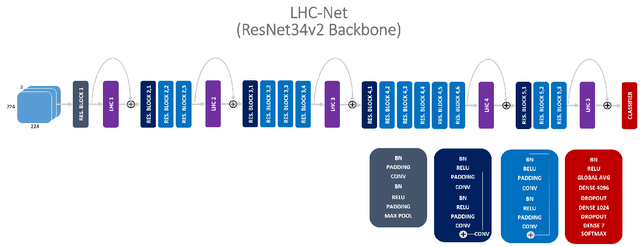
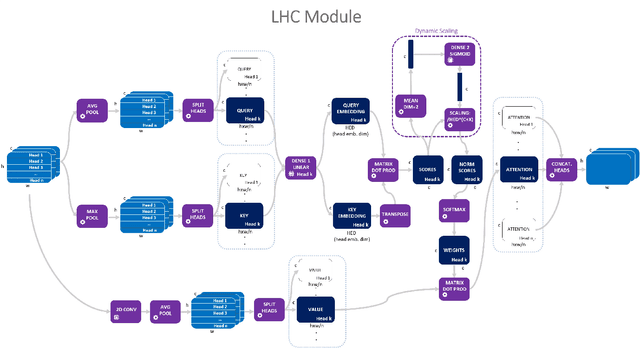
Since the Transformer architecture was introduced in 2017 there has been many attempts to bring the self-attention paradigm in the field of computer vision. In this paper we propose a novel self-attention module that can be easily integrated in virtually every convolutional neural network and that is specifically designed for computer vision, the LHC: Local (multi) Head Channel (self-attention). LHC is based on two main ideas: first, we think that in computer vision the best way to leverage the self-attention paradigm is the channel-wise application instead of the more explored spatial attention and that convolution will not be replaced by attention modules like recurrent networks were in NLP; second, a local approach has the potential to better overcome the limitations of convolution than global attention. With LHC-Net we managed to achieve a new state of the art in the famous FER2013 dataset with a significantly lower complexity and impact on the "host" architecture in terms of computational cost when compared with the previous SOTA.
Toward a Perspectivist Turn in Ground Truthing for Predictive Computing
Sep 09, 2021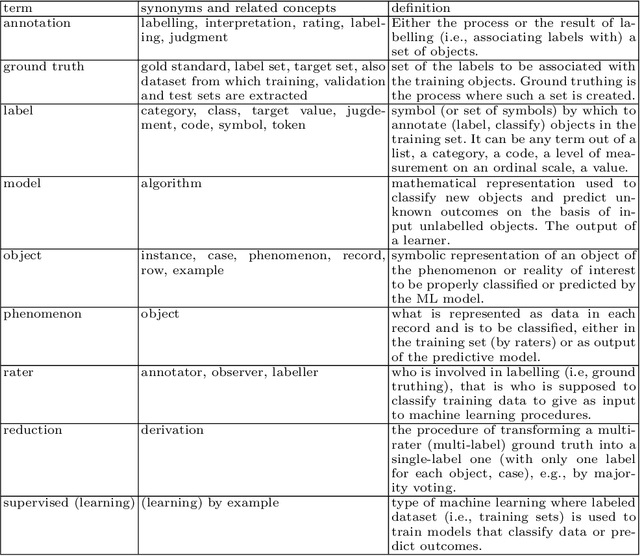
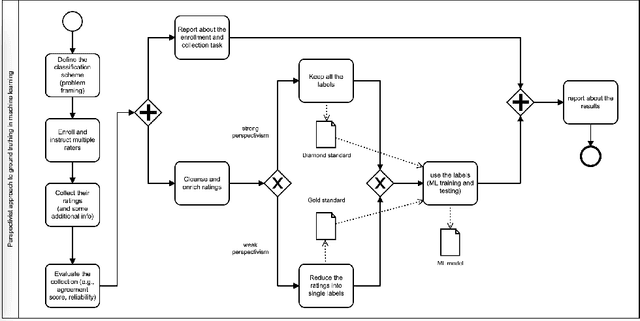
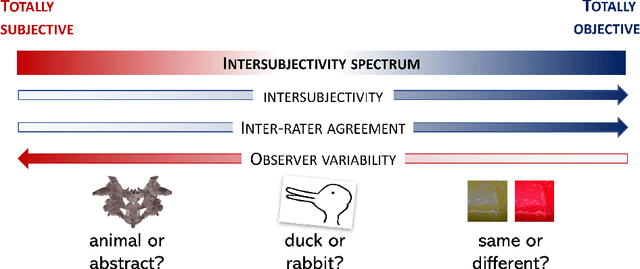
Most Artificial Intelligence applications are based on supervised machine learning (ML), which ultimately grounds on manually annotated data. The annotation process is often performed in terms of a majority vote and this has been proved to be often problematic, as highlighted by recent studies on the evaluation of ML models. In this article we describe and advocate for a different paradigm, which we call data perspectivism, which moves away from traditional gold standard datasets, towards the adoption of methods that integrate the opinions and perspectives of the human subjects involved in the knowledge representation step of ML processes. Drawing on previous works which inspired our proposal we describe the potential of our proposal for not only the more subjective tasks (e.g. those related to human language) but also to tasks commonly understood as objective (e.g. medical decision making), and present the main advantages of adopting a perspectivist stance in ML, as well as possible disadvantages, and various ways in which such a stance can be implemented in practice. Finally, we share a set of recommendations and outline a research agenda to advance the perspectivist stance in ML.
Whose Opinions Matter? Perspective-aware Models to Identify Opinions of Hate Speech Victims in Abusive Language Detection
Jun 30, 2021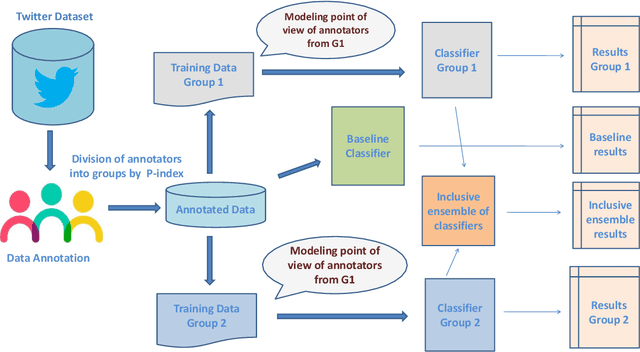
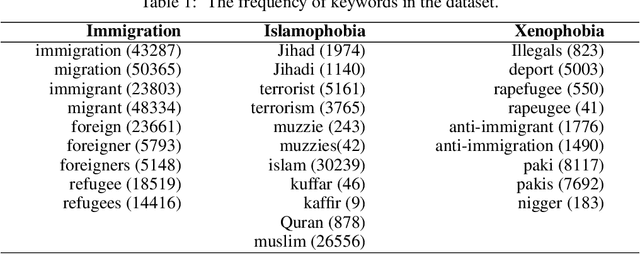
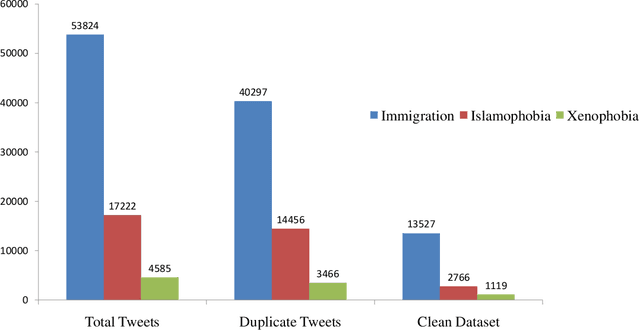

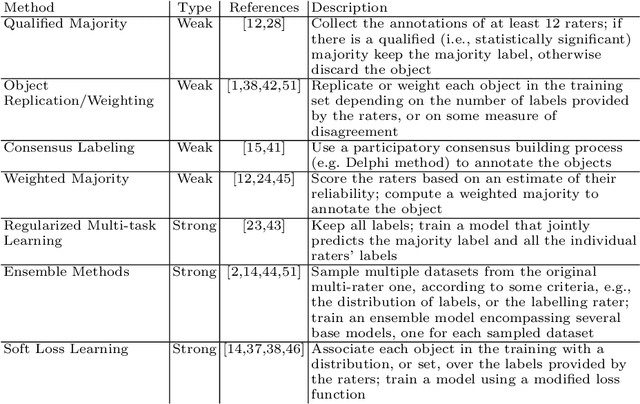
Social media platforms provide users the freedom of expression and a medium to exchange information and express diverse opinions. Unfortunately, this has also resulted in the growth of abusive content with the purpose of discriminating people and targeting the most vulnerable communities such as immigrants, LGBT, Muslims, Jews and women. Because abusive language is subjective in nature, there might be highly polarizing topics or events involved in the annotation of abusive contents such as hate speech (HS). Therefore, we need novel approaches to model conflicting perspectives and opinions coming from people with different personal and demographic backgrounds. In this paper, we present an in-depth study to model polarized opinions coming from different communities under the hypothesis that similar characteristics (ethnicity, social background, culture etc.) can influence the perspectives of annotators on a certain phenomenon. We believe that by relying on this information, we can divide the annotators into groups sharing similar perspectives. We can create separate gold standards, one for each group, to train state-of-the-art deep learning models. We can employ an ensemble approach to combine the perspective-aware classifiers from different groups to an inclusive model. We also propose a novel resource, a multi-perspective English language dataset annotated according to different sub-categories relevant for characterising online abuse: hate speech, aggressiveness, offensiveness and stereotype. By training state-of-the-art deep learning models on this novel resource, we show how our approach improves the prediction performance of a state-of-the-art supervised classifier.
Multilingual Irony Detection with Dependency Syntax and Neural Models
Nov 11, 2020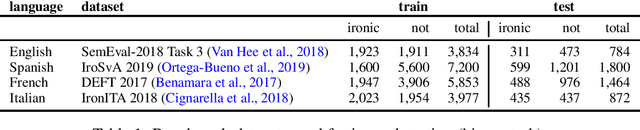


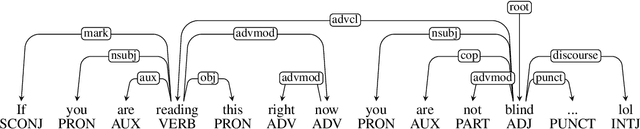
This paper presents an in-depth investigation of the effectiveness of dependency-based syntactic features on the irony detection task in a multilingual perspective (English, Spanish, French and Italian). It focuses on the contribution from syntactic knowledge, exploiting linguistic resources where syntax is annotated according to the Universal Dependencies scheme. Three distinct experimental settings are provided. In the first, a variety of syntactic dependency-based features combined with classical machine learning classifiers are explored. In the second scenario, two well-known types of word embeddings are trained on parsed data and tested against gold standard datasets. In the third setting, dependency-based syntactic features are combined into the Multilingual BERT architecture. The results suggest that fine-grained dependency-based syntactic information is informative for the detection of irony.
HateBERT: Retraining BERT for Abusive Language Detection in English
Oct 23, 2020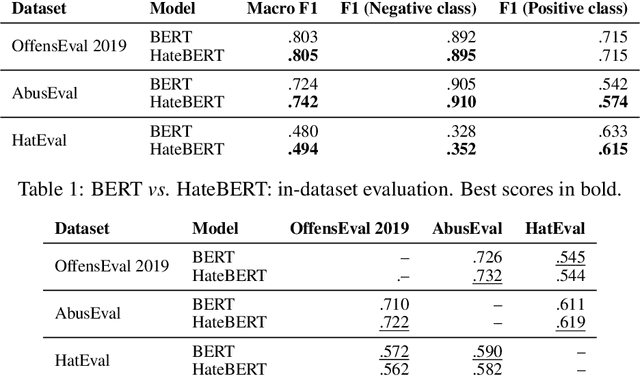

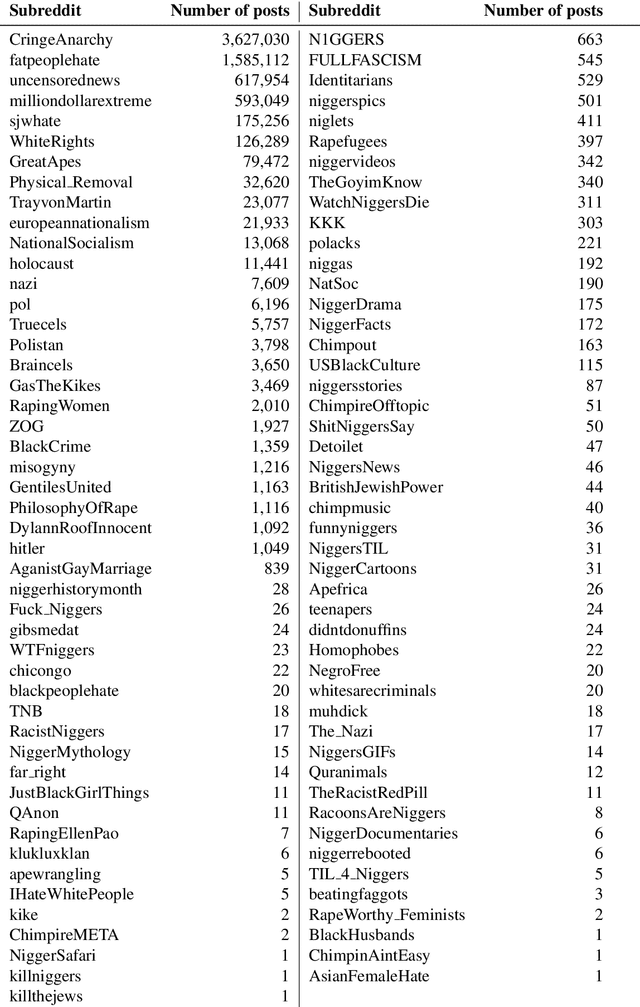
In this paper, we introduce HateBERT, a re-trained BERT model for abusive language detection in English. The model was trained on RAL-E, a large-scale dataset of Reddit comments in English from communities banned for being offensive, abusive, or hateful that we have collected and made available to the public. We present the results of a detailed comparison between a general pre-trained language model and the abuse-inclined version obtained by retraining with posts from the banned communities on three English datasets for offensive, abusive language and hate speech detection tasks. In all datasets, HateBERT outperforms the corresponding general BERT model. We also discuss a battery of experiments comparing the portability of the general pre-trained language model and its corresponding abusive language-inclined counterpart across the datasets, indicating that portability is affected by compatibility of the annotated phenomena.
Stance Classification for Rumour Analysis in Twitter: Exploiting Affective Information and Conversation Structure
Jan 07, 2019


Analysing how people react to rumours associated with news in social media is an important task to prevent the spreading of misinformation, which is nowadays widely recognized as a dangerous tendency. In social media conversations, users show different stances and attitudes towards rumourous stories. Some users take a definite stance, supporting or denying the rumour at issue, while others just comment it, or ask for additional evidence related to the veracity of the rumour. On this line, a new shared task has been proposed at SemEval-2017 (Task 8, SubTask A), which is focused on rumour stance classification in English tweets. The goal is predicting user stance towards emerging rumours in Twitter, in terms of supporting, denying, querying, or commenting the original rumour, looking at the conversation threads originated by the rumour. This paper describes a new approach to this task, where the use of conversation-based and affective-based features, covering different facets of affect, has been explored. Our classification model outperforms the best-performing systems for stance classification at SemEval-2017 Task 8, showing the effectiveness of the feature set proposed.