 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Schwartz Higher-Order Values Help Sentence-Level Human Value Detection? When Hard Gating Hurts
Jan 31, 2026Sentence-level human value detection is typically framed as multi-label classification over Schwartz values, but it remains unclear whether Schwartz higher-order (HO) categories provide usable structure. We study this under a strict compute-frugal budget (single 8 GB GPU) on ValueEval'24 / ValuesML (74K English sentences). We compare (i) direct supervised transformers, (ii) HO$\rightarrow$values pipelines that enforce the hierarchy with hard masks, and (iii) Presence$\rightarrow$HO$\rightarrow$values cascades, alongside low-cost add-ons (lexica, short context, topics), label-wise threshold tuning, small instruction-tuned LLM baselines ($\le$10B), QLoRA, and simple ensembles. HO categories are learnable from single sentences (e.g., the easiest bipolar pair reaches Macro-$F_1\approx0.58$), but hard hierarchical gating is not a reliable win: it often reduces end-task Macro-$F_1$ via error compounding and recall suppression. In contrast, label-wise threshold tuning is a high-leverage knob (up to $+0.05$ Macro-$F_1$), and small transformer ensembles provide the most consistent additional gains (up to $+0.02$ Macro-$F_1$). Small LLMs lag behind supervised encoders as stand-alone systems, yet can contribute complementary errors in cross-family ensembles. Overall, HO structure is useful descriptively, but enforcing it with hard gates hurts sentence-level value detection; robust improvements come from calibration and lightweight ensembling.
Human Values in a Single Sentence: Moral Presence, Hierarchies, and Transformer Ensembles on the Schwartz Continuum
Jan 20, 2026We study sentence-level identification of the 19 values in the Schwartz motivational continuum as a concrete formulation of human value detection in text. The setting - out-of-context sentences from news and political manifestos - features sparse moral cues and severe class imbalance. This combination makes fine-grained sentence-level value detection intrinsically difficult, even for strong modern neural models. We first operationalize a binary moral presence task ("does any value appear?") and show that it is learnable from single sentences (positive-class F1 $\approx$ 0.74 with calibrated thresholds). We then compare a presence-gated hierarchy to a direct multi-label classifier under matched compute, both based on DeBERTa-base and augmented with lightweight signals (prior-sentence context, LIWC-22/eMFD/MJD lexica, and topic features). The hierarchy does not outperform direct prediction, indicating that gate recall limits downstream gains. We also benchmark instruction-tuned LLMs - Gemma 2 9B, Llama 3.1 8B, Mistral 8B, and Qwen 2.5 7B - in zero-/few-shot and QLoRA setups and build simple ensembles; a soft-vote supervised ensemble reaches macro-F1 0.332, significantly surpassing the best single supervised model and exceeding prior English-only baselines. Overall, in this scenario, lightweight signals and small ensembles yield the most reliable improvements, while hierarchical gating offers limited benefit. We argue that, under an 8 GB single-GPU constraint and at the 7-9B scale, carefully tuned supervised encoders remain a strong and compute-efficient baseline for structured human value detection, and we outline how richer value structure and sentence-in-document context could further improve performance.
MEMEWEAVER: Inter-Meme Graph Reasoning for Sexism and Misogyny Detection
Jan 13, 2026Women are twice as likely as men to face online harassment due to their gender. Despite recent advances in multimodal content moderation, most approaches still overlook the social dynamics behind this phenomenon, where perpetrators reinforce prejudices and group identity within like-minded communities. Graph-based methods offer a promising way to capture such interactions, yet existing solutions remain limited by heuristic graph construction, shallow modality fusion, and instance-level reasoning. In this work, we present MemeWeaver, an end-to-end trainable multimodal framework for detecting sexism and misogyny through a novel inter-meme graph reasoning mechanism. We systematically evaluate multiple visual--textual fusion strategies and show that our approach consistently outperforms state-of-the-art baselines on the MAMI and EXIST benchmarks, while achieving faster training convergence. Further analyses reveal that the learned graph structure captures semantically meaningful patterns, offering valuable insights into the relational nature of online hate.
Efficient Out-of-Scope Detection in Dialogue Systems via Uncertainty-Driven LLM Routing
Jul 02, 2025Out-of-scope (OOS) intent detection is a critical challenge in task-oriented dialogue systems (TODS), as it ensures robustness to unseen and ambiguous queries. In this work, we propose a novel but simple modular framework that combines uncertainty modeling with fine-tuned large language models (LLMs) for efficient and accurate OOS detection. The first step applies uncertainty estimation to the output of an in-scope intent detection classifier, which is currently deployed in a real-world TODS handling tens of thousands of user interactions daily. The second step then leverages an emerging LLM-based approach, where a fine-tuned LLM is triggered to make a final decision on instances with high uncertainty. Unlike prior approaches, our method effectively balances computational efficiency and performance, combining traditional approaches with LLMs and yielding state-of-the-art results on key OOS detection benchmarks, including real-world OOS data acquired from a deployed TODS.
Divergent Emotional Patterns in Disinformation on Social Media? An Analysis of Tweets and TikToks about the DANA in Valencia
Jan 28, 2025
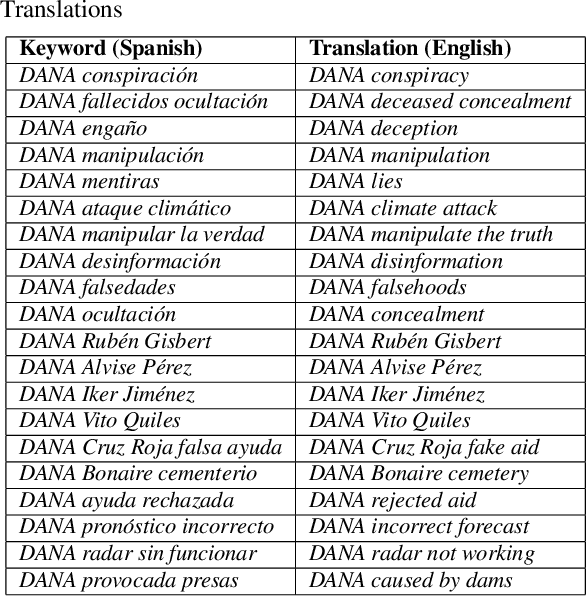
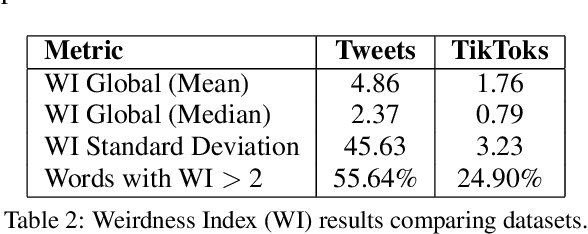

This study investigates the dissemination of disinformation on social media platforms during the DANA event (DANA is a Spanish acronym for Depresion Aislada en Niveles Altos, translating to high-altitude isolated depression) that resulted in extremely heavy rainfall and devastating floods in Valencia, Spain, on October 29, 2024. We created a novel dataset of 650 TikTok and X posts, which was manually annotated to differentiate between disinformation and trustworthy content. Additionally, a Few-Shot annotation approach with GPT-4o achieved substantial agreement (Cohen's kappa of 0.684) with manual labels. Emotion analysis revealed that disinformation on X is mainly associated with increased sadness and fear, while on TikTok, it correlates with higher levels of anger and disgust. Linguistic analysis using the LIWC dictionary showed that trustworthy content utilizes more articulate and factual language, whereas disinformation employs negations, perceptual words, and personal anecdotes to appear credible. Audio analysis of TikTok posts highlighted distinct patterns: trustworthy audios featured brighter tones and robotic or monotone narration, promoting clarity and credibility, while disinformation audios leveraged tonal variation, emotional depth, and manipulative musical elements to amplify engagement. In detection models, SVM+TF-IDF achieved the highest F1-Score, excelling with limited data. Incorporating audio features into roberta-large-bne improved both Accuracy and F1-Score, surpassing its text-only counterpart and SVM in Accuracy. GPT-4o Few-Shot also performed well, showcasing the potential of large language models for automated disinformation detection. These findings demonstrate the importance of leveraging both textual and audio features for improved disinformation detection on multimodal platforms like TikTok.
Do LLMs Provide Consistent Answers to Health-Related Questions across Languages?
Jan 24, 2025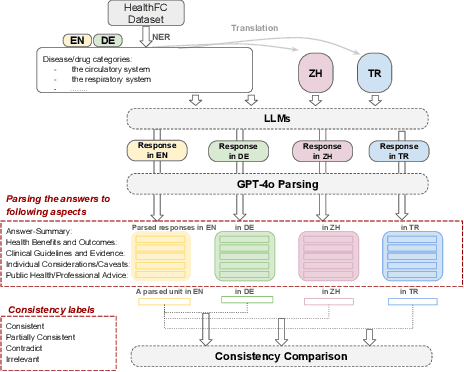
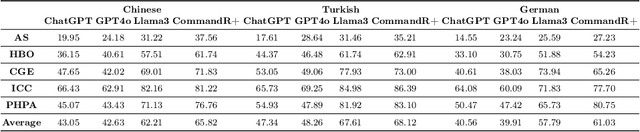

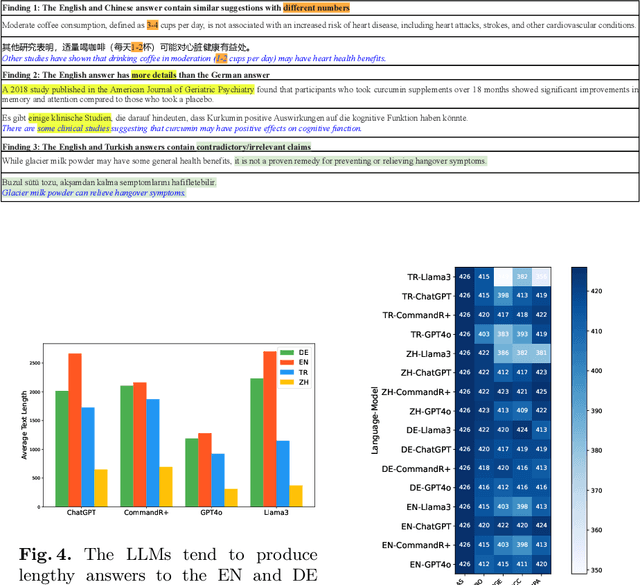
Equitable access to reliable health information is vital for public health, but the quality of online health resources varies by language, raising concerns about inconsistencies in Large Language Models (LLMs) for healthcare. In this study, we examine the consistency of responses provided by LLMs to health-related questions across English, German, Turkish, and Chinese. We largely expand the HealthFC dataset by categorizing health-related questions by disease type and broadening its multilingual scope with Turkish and Chinese translations. We reveal significant inconsistencies in responses that could spread healthcare misinformation. Our main contributions are 1) a multilingual health-related inquiry dataset with meta-information on disease categories, and 2) a novel prompt-based evaluation workflow that enables sub-dimensional comparisons between two languages through parsing. Our findings highlight key challenges in deploying LLM-based tools in multilingual contexts and emphasize the need for improved cross-lingual alignment to ensure accurate and equitable healthcare information.
"Stupid robot, I want to speak to a human!" User Frustration Detection in Task-Oriented Dialog Systems
Nov 26, 2024



Detecting user frustration in modern-day task-oriented dialog (TOD) systems is imperative for maintaining overall user satisfaction, engagement, and retention. However, most recent research is focused on sentiment and emotion detection in academic settings, thus failing to fully encapsulate implications of real-world user data. To mitigate this gap, in this work, we focus on user frustration in a deployed TOD system, assessing the feasibility of out-of-the-box solutions for user frustration detection. Specifically, we compare the performance of our deployed keyword-based approach, open-source approaches to sentiment analysis, dialog breakdown detection methods, and emerging in-context learning LLM-based detection. Our analysis highlights the limitations of open-source methods for real-world frustration detection, while demonstrating the superior performance of the LLM-based approach, achieving a 16\% relative improvement in F1 score on an internal benchmark. Finally, we analyze advantages and limitations of our methods and provide an insight into user frustration detection task for industry practitioners.
What distinguishes conspiracy from critical narratives? A computational analysis of oppositional discourse
Jul 15, 2024The current prevalence of conspiracy theories on the internet is a significant issue, tackled by many computational approaches. However, these approaches fail to recognize the relevance of distinguishing between texts which contain a conspiracy theory and texts which are simply critical and oppose mainstream narratives. Furthermore, little attention is usually paid to the role of inter-group conflict in oppositional narratives. We contribute by proposing a novel topic-agnostic annotation scheme that differentiates between conspiracies and critical texts, and that defines span-level categories of inter-group conflict. We also contribute with the multilingual XAI-DisInfodemics corpus (English and Spanish), which contains a high-quality annotation of Telegram messages related to COVID-19 (5,000 messages per language). We also demonstrate the feasibility of an NLP-based automatization by performing a range of experiments that yield strong baseline solutions. Finally, we perform an analysis which demonstrates that the promotion of intergroup conflict and the presence of violence and anger are key aspects to distinguish between the two types of oppositional narratives, i.e., conspiracy vs. critical.
RoCode: A Dataset for Measuring Code Intelligence from Problem Definitions in Romanian
Feb 20, 2024


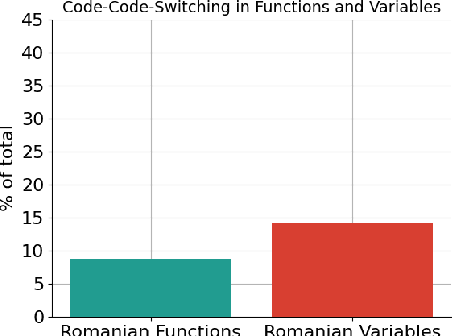
Recently, large language models (LLMs) have become increasingly powerful and have become capable of solving a plethora of tasks through proper instructions in natural language. However, the vast majority of testing suites assume that the instructions are written in English, the de facto prompting language. Code intelligence and problem solving still remain a difficult task, even for the most advanced LLMs. Currently, there are no datasets to measure the generalization power for code-generation models in a language other than English. In this work, we present RoCode, a competitive programming dataset, consisting of 2,642 problems written in Romanian, 11k solutions in C, C++ and Python and comprehensive testing suites for each problem. The purpose of RoCode is to provide a benchmark for evaluating the code intelligence of language models trained on Romanian / multilingual text as well as a fine-tuning set for pretrained Romanian models. Through our results and review of related works, we argue for the need to develop code models for languages other than English.
Reading Between the Frames: Multi-Modal Depression Detection in Videos from Non-Verbal Cues
Jan 05, 2024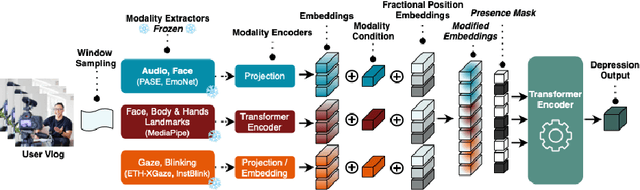
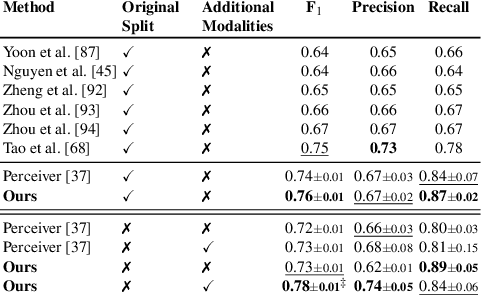

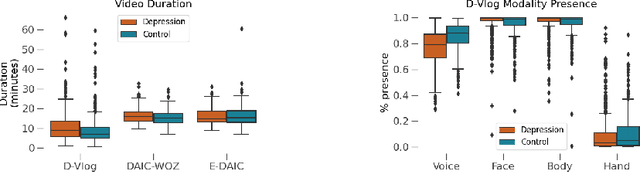
Depression, a prominent contributor to global disability, affects a substantial portion of the population. Efforts to detect depression from social media texts have been prevalent, yet only a few works explored depression detection from user-generated video content. In this work, we address this research gap by proposing a simple and flexible multi-modal temporal model capable of discerning non-verbal depression cues from diverse modalities in noisy, real-world videos. We show that, for in-the-wild videos, using additional high-level non-verbal cues is crucial to achieving good performance, and we extracted and processed audio speech embeddings, face emotion embeddings, face, body and hand landmarks, and gaze and blinking information. Through extensive experiments, we show that our model achieves state-of-the-art results on three key benchmark datasets for depression detection from video by a substantial margin. Our code is publicly available on GitHub.