 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Between the Frames: Multi-Modal Depression Detection in Videos from Non-Verbal Cues
Jan 05, 2024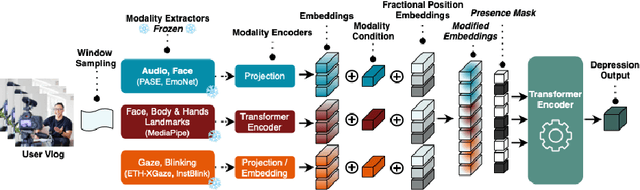
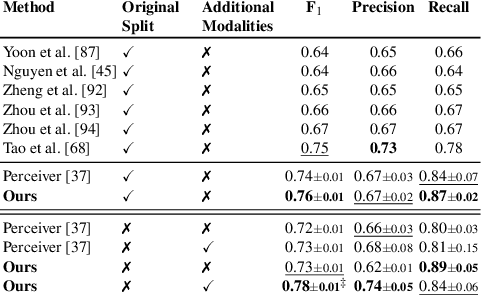

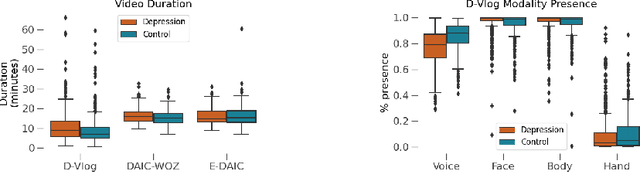
Depression, a prominent contributor to global disability, affects a substantial portion of the population. Efforts to detect depression from social media texts have been prevalent, yet only a few works explored depression detection from user-generated video content. In this work, we address this research gap by proposing a simple and flexible multi-modal temporal model capable of discerning non-verbal depression cues from diverse modalities in noisy, real-world videos. We show that, for in-the-wild videos, using additional high-level non-verbal cues is crucial to achieving good performance, and we extracted and processed audio speech embeddings, face emotion embeddings, face, body and hand landmarks, and gaze and blinking information. Through extensive experiments, we show that our model achieves state-of-the-art results on three key benchmark datasets for depression detection from video by a substantial margin. Our code is publicly available on GitHub.