 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Effectiveness of LLMs in Delivering Cognitive Behavioral Therapy
Mar 04, 2026As mental health issues continue to rise globally, there is an increasing demand for accessible and scalable therapeutic solutions. Many individuals currently seek support from Large Language Models (LLMs), even though these models have not been validated for use in counseling services. In this paper, we evaluate LLMs' ability to emulate professional therapists practicing Cognitive Behavioral Therapy (CBT). Using anonymized, transcribed role-play sessions between licensed therapists and clients, we compare two approaches: (1) a generation-only method and (2) a Retrieval-Augmented Generation (RAG) approach using CBT guidelines. We evaluate both proprietary and open-source models for linguistic quality, semantic coherence, and therapeutic fidelity using standard natural language generation (NLG) metrics, natural language inference (NLI), and automated scoring for skills assessment. Our results indicate that while LLMs can generate CBT-like dialogues, they are limited in their ability to convey empathy and maintain consistency.
Large Language Models for Mental Health: A Multilingual Evaluation
Feb 02, 2026Large Language Models (LLMs) have remarkable capabilities across NLP tasks. However, their performance in multilingual contexts, especially within the mental health domain, has not been thoroughly explored. In this paper, we evaluate proprietary and open-source LLMs on eight mental health datasets in various languages, as well as their machine-translated (MT) counterparts. We compare LLM performance in zero-shot, few-shot, and fine-tuned settings against conventional NLP baselines that do not employ LLMs. In addition, we assess translation quality across language families and typologies to understand its influence on LLM performance. Proprietary LLMs and fine-tuned open-source LLMs achieve competitive F1 scores on several datasets, often surpassing state-of-the-art results. However, performance on MT data is generally lower, and the extent of this decline varies by language and typology. This variation highlights both the strengths of LLMs in handling mental health tasks in languages other than English and their limitations when translation quality introduces structural or lexical mismatches.
A Survey on Multilingual Mental Disorders Detection from Social Media Data
May 21, 2025The increasing prevalence of mental health disorders globally highlights the urgent need for effective digital screening methods that can be used in multilingual contexts. Most existing studies, however, focus on English data, overlooking critical mental health signals that may be present in non-English texts. To address this important gap, we present the first survey on the detection of mental health disorders using multilingual social media data. We investigate the cultural nuances that influence online language patterns and self-disclosure behaviors, and how these factors can impact the performance of NLP tools. Additionally, we provide a comprehensive list of multilingual data collections that can be used for developing NLP models for mental health screening. Our findings can inform the design of effective multilingual mental health screening tools that can meet the needs of diverse populations, ultimately improving mental health outcomes on a global scale.
Datasets for Depression Modeling in Social Media: An Overview
Mar 27, 2025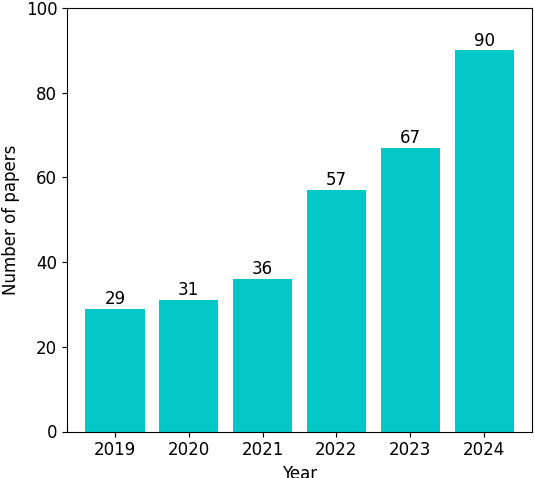
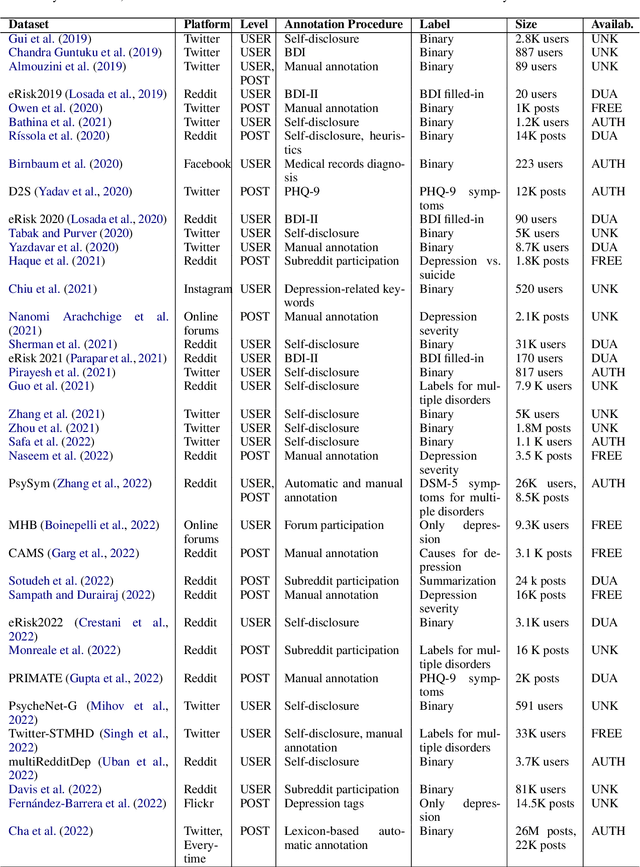
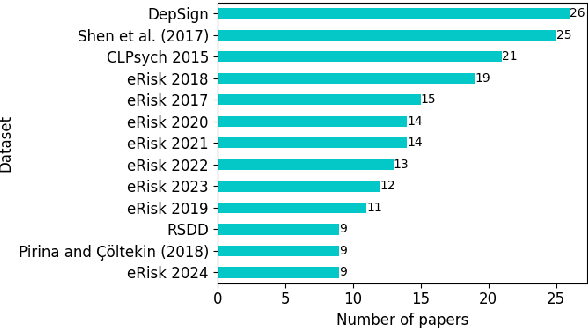
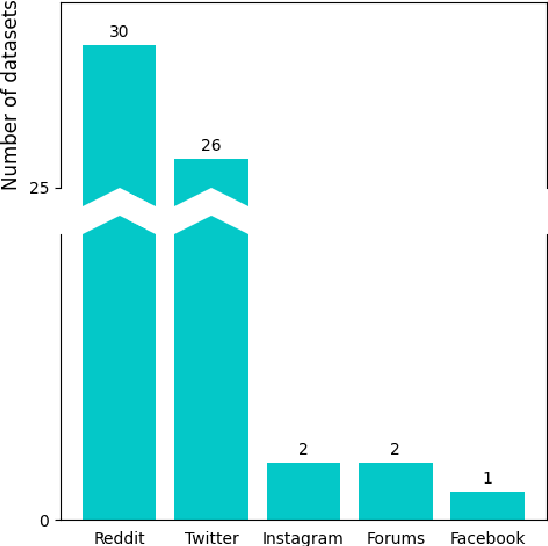
Depression is the most common mental health disorder, and its prevalence increased during the COVID-19 pandemic. As one of the most extensively researched psychological conditions, recent research has increasingly focused on leveraging social media data to enhance traditional methods of depression screening. This paper addresses the growing interest in interdisciplinary research on depression, and aims to support early-career researchers by providing a comprehensive and up-to-date list of datasets for analyzing and predicting depression through social media data. We present an overview of datasets published between 2019 and 2024. We also make the comprehensive list of datasets available online as a continuously updated resource, with the hope that it will facilitate further interdisciplinary research into the linguistic expressions of depression on social media.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
On the State of NLP Approaches to Modeling Depression in Social Media: A Post-COVID-19 Outlook
Oct 11, 2024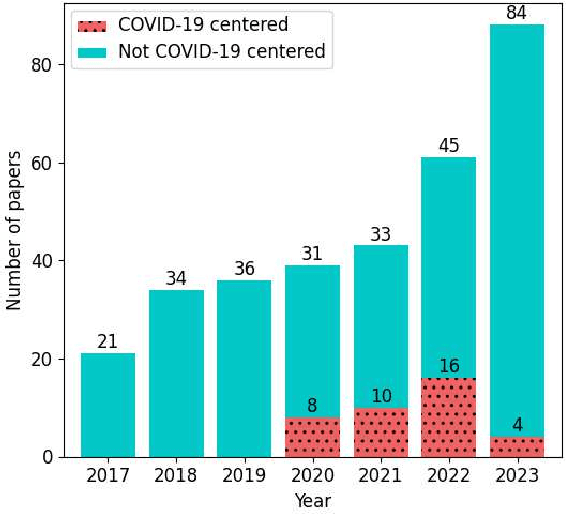
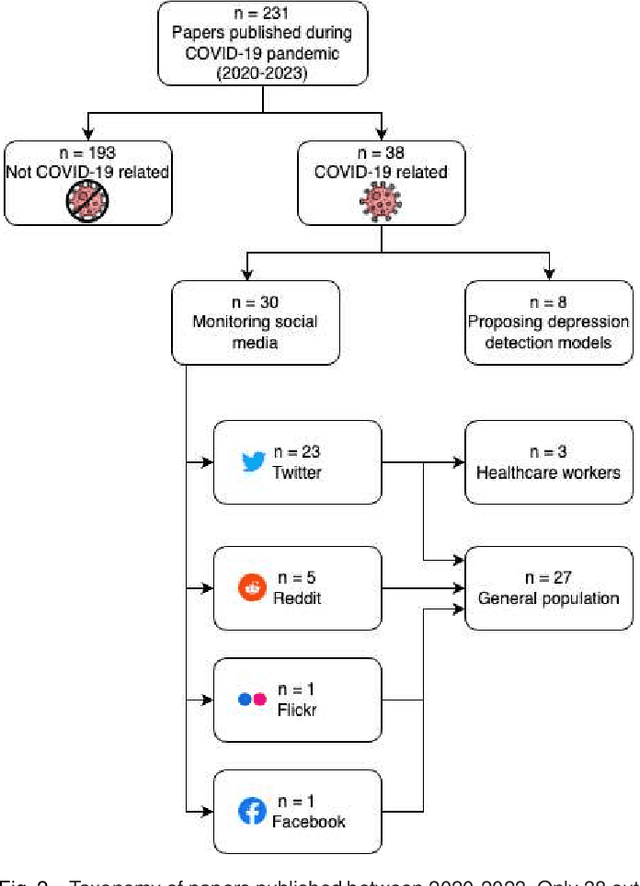
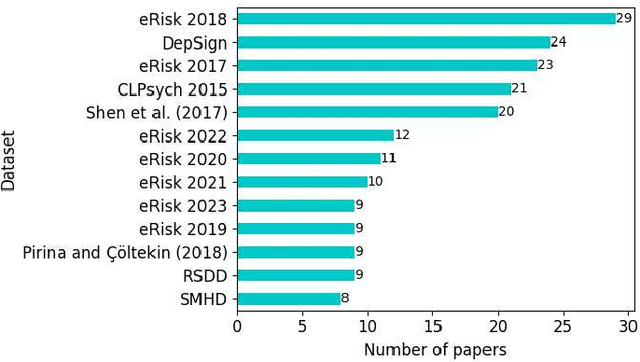
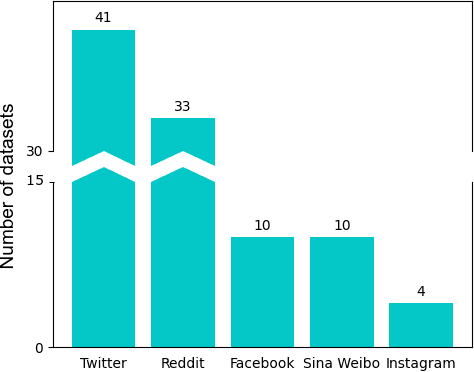
Computational approaches to predicting mental health conditions in social media have been substantially explored in the past years. Multiple surveys have been published on this topic, providing the community with comprehensive accounts of the research in this area. Among all mental health conditions, depression is the most widely studied due to its worldwide prevalence. The COVID-19 global pandemic, starting in early 2020, has had a great impact on mental health worldwide. Harsh measures employed by governments to slow the spread of the virus (e.g., lockdowns) and the subsequent economic downturn experienced in many countries have significantly impacted people's lives and mental health. Studies have shown a substantial increase of above 50% in the rate of depression in the population. In this context, we present a survey on natural language processing (NLP) approaches to modeling depression in social media, providing the reader with a post-COVID-19 outlook. This survey contributes to the understanding of the impacts of the pandemic on modeling depression in social media. We outline how state-of-the-art approaches and new datasets have been used in the context of the COVID-19 pandemic. Finally, we also discuss ethical issues in collecting and processing mental health data, considering fairness, accountability, and ethics.
RoMath: A Mathematical Reasoning Benchmark in Romanian
Sep 17, 2024



Mathematics has long been conveyed through natural language, primarily for human understanding. With the rise of mechanized mathematics and proof assistants, there is a growing need to understand informal mathematical text, yet most existing benchmarks focus solely on English, overlooking other languages. This paper introduces RoMath, a Romanian mathematical reasoning benchmark suite comprising three datasets: RoMath-Baccalaureate, RoMath-Competitions and RoMath-Synthetic, which cover a range of mathematical domains and difficulty levels, aiming to improve non-English language models and promote multilingual AI development. By focusing on Romanian, a low-resource language with unique linguistic features, RoMath addresses the limitations of Anglo-centric models and emphasizes the need for dedicated resources beyond simple automatic translation. We benchmark several open-weight language models, highlighting the importance of creating resources for underrepresented languages. We make the code and dataset available.
Reading Between the Frames: Multi-Modal Depression Detection in Videos from Non-Verbal Cues
Jan 05, 2024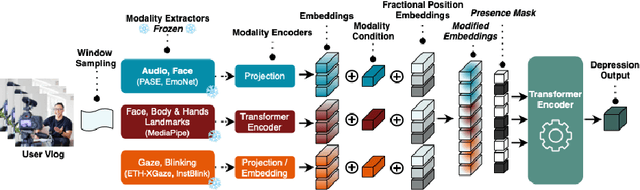
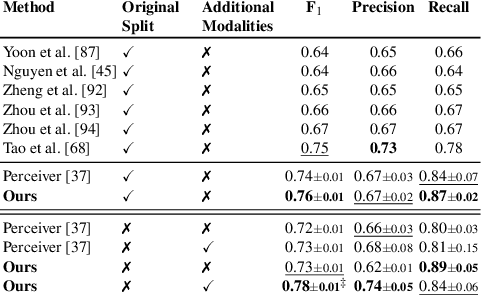

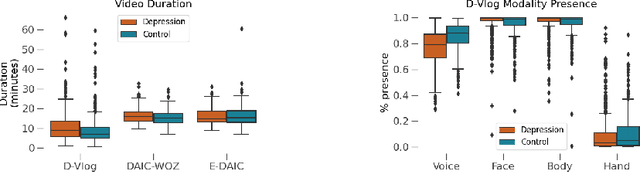
Depression, a prominent contributor to global disability, affects a substantial portion of the population. Efforts to detect depression from social media texts have been prevalent, yet only a few works explored depression detection from user-generated video content. In this work, we address this research gap by proposing a simple and flexible multi-modal temporal model capable of discerning non-verbal depression cues from diverse modalities in noisy, real-world videos. We show that, for in-the-wild videos, using additional high-level non-verbal cues is crucial to achieving good performance, and we extracted and processed audio speech embeddings, face emotion embeddings, face, body and hand landmarks, and gaze and blinking information. Through extensive experiments, we show that our model achieves state-of-the-art results on three key benchmark datasets for depression detection from video by a substantial margin. Our code is publicly available on GitHub.
Automatic Extraction of the Romanian Academic Word List: Data and Methods
Jul 29, 2023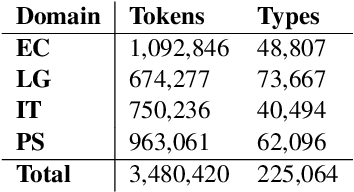
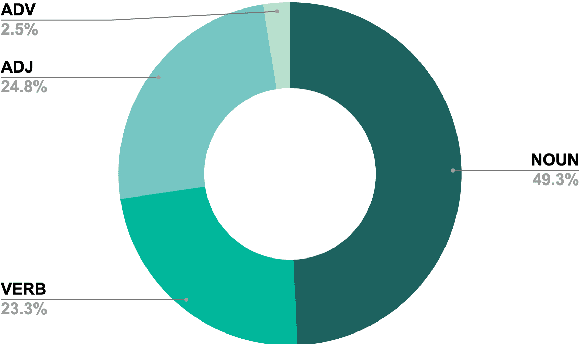
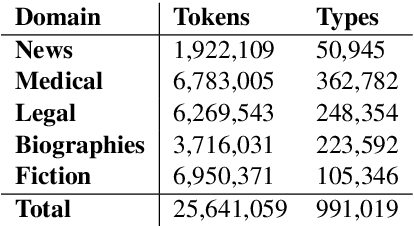

This paper presents the methodology and data used for the automatic extraction of the Romanian Academic Word List (Ro-AWL). Academic Word Lists are useful in both L2 and L1 teaching contexts. For the Romanian language, no such resource exists so far. Ro-AWL has been generated by combining methods from corpus and computational linguistics with L2 academic writing approaches. We use two types of data: (a) existing data, such as the Romanian Frequency List based on the ROMBAC corpus, and (b) self-compiled data, such as the expert academic writing corpus EXPRES. For constructing the academic word list, we follow the methodology for building the Academic Vocabulary List for the English language. The distribution of Ro-AWL features (general distribution, POS distribution) into four disciplinary datasets is in line with previous research. Ro-AWL is freely available and can be used for teaching, research and NLP applications.
Utilizing ChatGPT Generated Data to Retrieve Depression Symptoms from Social Media
Jul 06, 2023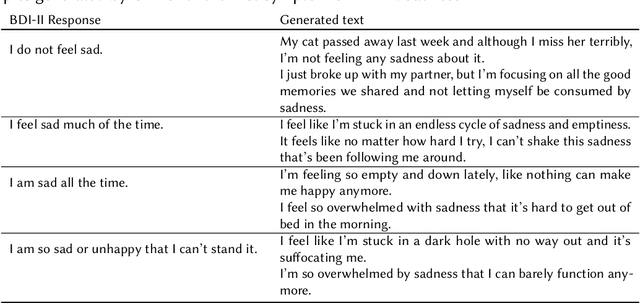


In this work, we present the contribution of the BLUE team in the eRisk Lab task on searching for symptoms of depression. The task consists of retrieving and ranking Reddit social media sentences that convey symptoms of depression from the BDI-II questionnaire. Given that synthetic data provided by LLMs have been proven to be a reliable method for augmenting data and fine-tuning downstream models, we chose to generate synthetic data using ChatGPT for each of the symptoms of the BDI-II questionnaire. We designed a prompt such that the generated data contains more richness and semantic diversity than the BDI-II responses for each question and, at the same time, contains emotional and anecdotal experiences that are specific to the more intimate way of sharing experiences on Reddit. We perform semantic search and rank the sentences' relevance to the BDI-II symptoms by cosine similarity. We used two state-of-the-art transformer-based models (MentalRoBERTa and a variant of MPNet) for embedding the social media posts, the original and generated responses of the BDI-II. Our results show that using sentence embeddings from a model designed for semantic search outperforms the approach using embeddings from a model pre-trained on mental health data. Furthermore, the generated synthetic data were proved too specific for this task, the approach simply relying on the BDI-II responses had the best performance.