 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriggered: A Statistical Analysis of Environmental Influences on Extremist Groups
Feb 10, 2026Online extremist communities operate within a wider information ecosystem shaped by real-world events, news coverage, and cross-community interaction. We adopt a systems perspective to examine these influences using seven years of data from two ideologically distinct extremist forums (Stormfront and Incels) and a mainstream reference community (r/News). We ask three questions: how extremist violence impacts community behaviour; whether news coverage of political entities predicts shifts in conversation dynamics; and whether linguistic diffusion occurs between mainstream and extremist spaces and across extremist ideologies. Methodologically, we combine counterfactual synthesis to estimate event-level impacts with vector autoregression and Granger causality analyses to model ongoing relationships among news signals, behavioural outcomes, and cross-community language change. Across analyses, our results indicate that Stormfront and r/News appear to be more reactive to external stimuli, while Incels demonstrates less cross-community linguistic influence and less responsiveness to news and violent events. These findings underscore that extremist communities are not homogeneous, but differ in how tightly they are coupled to the surrounding information ecosystem.
IYKYK: Using language models to decode extremist cryptolects
Jun 05, 2025Extremist groups develop complex in-group language, also referred to as cryptolects, to exclude or mislead outsiders. We investigate the ability of current language technologies to detect and interpret the cryptolects of two online extremist platforms. Evaluating eight models across six tasks, our results indicate that general purpose LLMs cannot consistently detect or decode extremist language. However, performance can be significantly improved by domain adaptation and specialised prompting techniques. These results provide important insights to inform the development and deployment of automated moderation technologies. We further develop and release novel labelled and unlabelled datasets, including 19.4M posts from extremist platforms and lexicons validated by human experts.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Jointly modelling the evolution of community structure and language in online extremist groups
Sep 28, 2024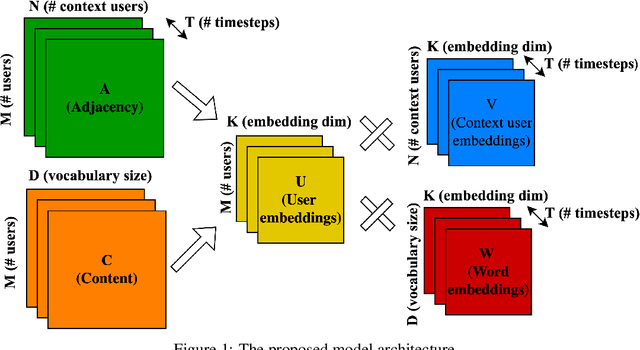
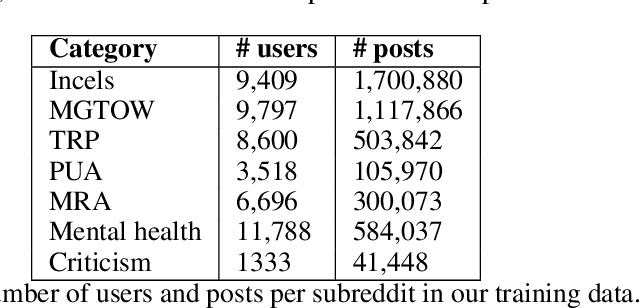
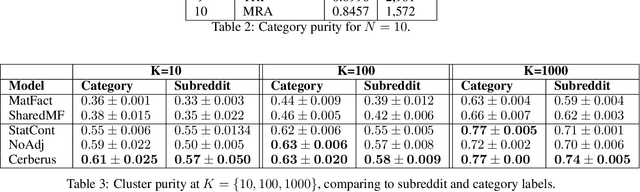
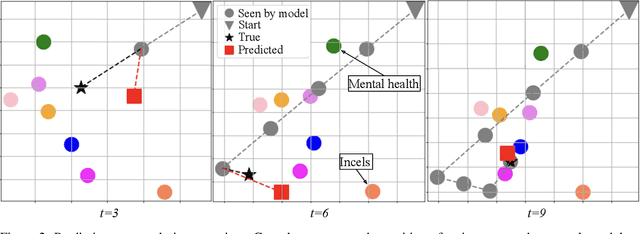
Group interactions take place within a particular socio-temporal context, which should be taken into account when modelling communities. We propose a method for jointly modelling community structure and language over time, and apply it in the context of extremist anti-women online groups (collectively known as the manosphere). Our model derives temporally grounded embeddings for words and users, which evolve over the training window. We show that this approach outperforms prior models which lacked one of these components (i.e. not incorporating social structure, or using static word embeddings). Using these embeddings, we investigate the evolution of users and words within these communities in three ways: (i) we model a user as a sequence of embeddings and forecast their affinity groups beyond the training window, (ii) we illustrate how word evolution is useful in the context of temporal events, and (iii) we characterise the propensity for violent language within subgroups of the manosphere.
LISTN: Lexicon induction with socio-temporal nuance
Sep 28, 2024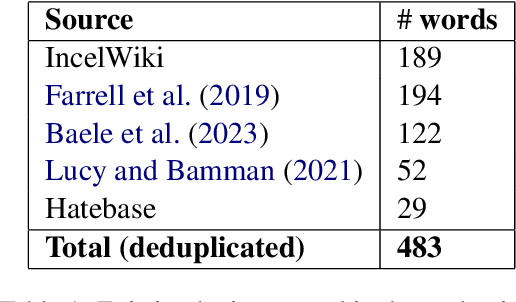
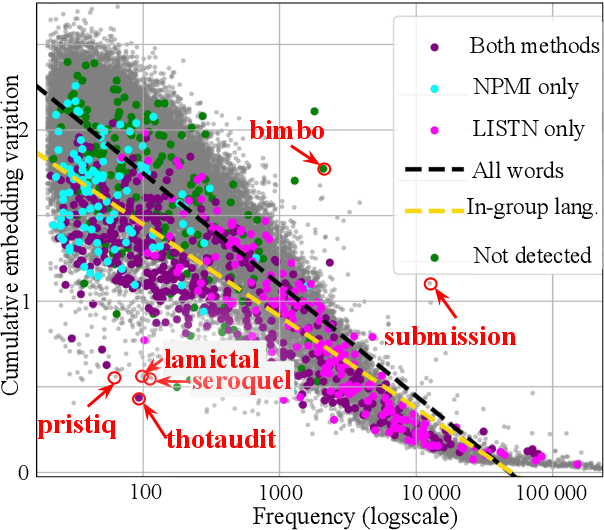

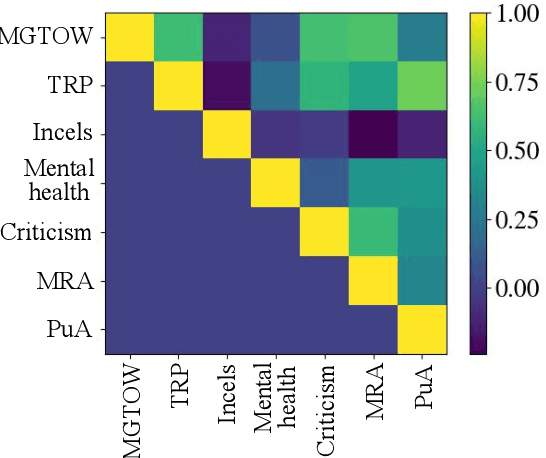
Research on extremist online communities frequently utilizes linguistic analysis to explore group dynamics and behaviour. Existing studies often rely on outdated lexicons that do not capture the evolving nature of in-group language, nor the social structure of the community. This paper proposes a novel method for inducing in-group lexicons which incorporates its socio-temporal context. Using dynamic word and user embeddings trained on conversations from online anti-women communities, our approach outperforms prior methods for lexicon induction. We provide a new lexicon of manosphere terms, validated by human experts, which quantifies the relevance of each term to a specific sub-community. We present novel insights on in-group language which illustrate the utility of this approach.
RAEmoLLM: Retrieval Augmented LLMs for Cross-Domain Misinformation Detection Using In-Context Learning based on Emotional Information
Jun 16, 2024Misinformation is prevalent in various fields such as education, politics, health, etc., causing significant harm to society. However, current methods for cross-domain misinformation detection rely on time and resources consuming fine-tuning and complex model structures. With the outstanding performance of LLMs, many studies have employed them for misinformation detection. Unfortunately, they focus on in-domain tasks and do not incorporate significant sentiment and emotion features (which we jointly call affect). In this paper, we propose RAEmoLLM, the first retrieval augmented (RAG) LLMs framework to address cross-domain misinformation detection using in-context learning based on affective information. It accomplishes this by applying an emotion-aware LLM to construct a retrieval database of affective embeddings. This database is used by our retrieval module to obtain source-domain samples, which are subsequently used for the inference module's in-context few-shot learning to detect target domain misinformation. We evaluate our framework on three misinformation benchmarks. Results show that RAEmoLLM achieves significant improvements compared to the zero-shot method on three datasets, with the highest increases of 20.69%, 23.94%, and 39.11% respectively. This work will be released on https://github.com/lzw108/RAEmoLLM.
How to disagree well: Investigating the dispute tactics used on Wikipedia
Dec 16, 2022Disagreements are frequently studied from the perspective of either detecting toxicity or analysing argument structure. We propose a framework of dispute tactics that unifies these two perspectives, as well as other dialogue acts which play a role in resolving disputes, such as asking questions and providing clarification. This framework includes a preferential ordering among rebuttal-type tactics, ranging from ad hominem attacks to refuting the central argument. Using this framework, we annotate 213 disagreements (3,865 utterances) from Wikipedia Talk pages. This allows us to investigate research questions around the tactics used in disagreements; for instance, we provide empirical validation of the approach to disagreement recommended by Wikipedia. We develop models for multilabel prediction of dispute tactics in an utterance, achieving the best performance with a transformer-based label powerset model. Adding an auxiliary task to incorporate the ordering of rebuttal tactics further yields a statistically significant increase. Finally, we show that these annotations can be used to provide useful additional signals to improve performance on the task of predicting escalation.
* Accepted to EMNLP 2022 (Long paper)
I Beg to Differ: A study of constructive disagreement in online conversations
Jan 26, 2021
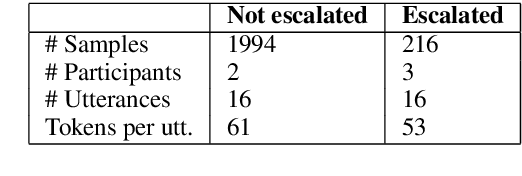
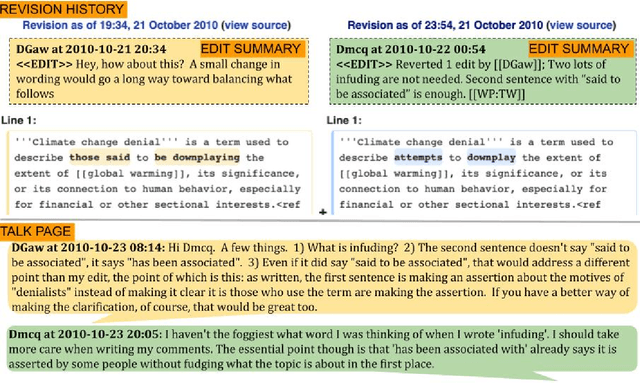

Disagreements are pervasive in human communication. In this paper we investigate what makes disagreement constructive. To this end, we construct WikiDisputes, a corpus of 7 425 Wikipedia Talk page conversations that contain content disputes, and define the task of predicting whether disagreements will be escalated to mediation by a moderator. We evaluate feature-based models with linguistic markers from previous work, and demonstrate that their performance is improved by using features that capture changes in linguistic markers throughout the conversations, as opposed to averaged values. We develop a variety of neural models and show that taking into account the structure of the conversation improves predictive accuracy, exceeding that of feature-based models. We assess our best neural model in terms of both predictive accuracy and uncertainty by evaluating its behaviour when it is only exposed to the beginning of the conversation, finding that model accuracy improves and uncertainty reduces as models are exposed to more information.