 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIYKYK: Using language models to decode extremist cryptolects
Jun 05, 2025Extremist groups develop complex in-group language, also referred to as cryptolects, to exclude or mislead outsiders. We investigate the ability of current language technologies to detect and interpret the cryptolects of two online extremist platforms. Evaluating eight models across six tasks, our results indicate that general purpose LLMs cannot consistently detect or decode extremist language. However, performance can be significantly improved by domain adaptation and specialised prompting techniques. These results provide important insights to inform the development and deployment of automated moderation technologies. We further develop and release novel labelled and unlabelled datasets, including 19.4M posts from extremist platforms and lexicons validated by human experts.
Beyond Dataset Creation: Critical View of Annotation Variation and Bias Probing of a Dataset for Online Radical Content Detection
Dec 16, 2024The proliferation of radical content on online platforms poses significant risks, including inciting violence and spreading extremist ideologies. Despite ongoing research, existing datasets and models often fail to address the complexities of multilingual and diverse data. To bridge this gap, we introduce a publicly available multilingual dataset annotated with radicalization levels, calls for action, and named entities in English, French, and Arabic. This dataset is pseudonymized to protect individual privacy while preserving contextual information. Beyond presenting our \href{https://gitlab.inria.fr/ariabi/counter-dataset-public}{freely available dataset}, we analyze the annotation process, highlighting biases and disagreements among annotators and their implications for model performance. Additionally, we use synthetic data to investigate the influence of socio-demographic traits on annotation patterns and model predictions. Our work offers a comprehensive examination of the challenges and opportunities in building robust datasets for radical content detection, emphasizing the importance of fairness and transparency in model development.
Common Ground, Diverse Roots: The Difficulty of Classifying Common Examples in Spanish Varieties
Dec 16, 2024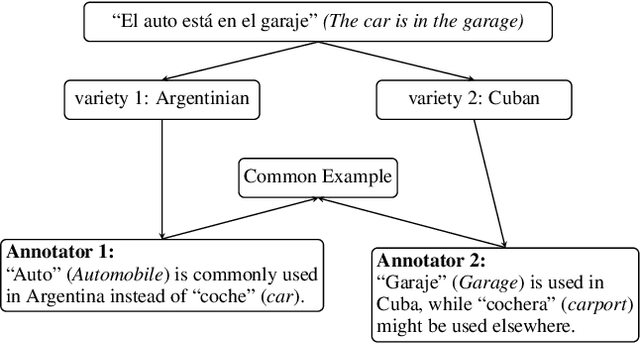
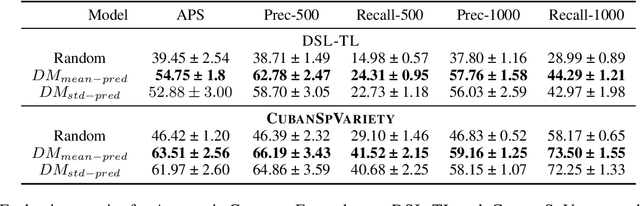
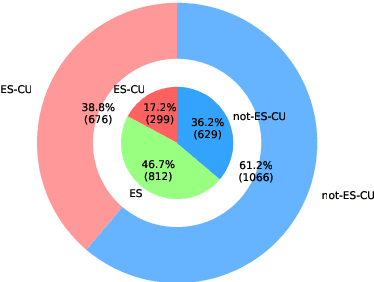

Variations in languages across geographic regions or cultures are crucial to address to avoid biases in NLP systems designed for culturally sensitive tasks, such as hate speech detection or dialog with conversational agents. In languages such as Spanish, where varieties can significantly overlap, many examples can be valid across them, which we refer to as common examples. Ignoring these examples may cause misclassifications, reducing model accuracy and fairness. Therefore, accounting for these common examples is essential to improve the robustness and representativeness of NLP systems trained on such data. In this work, we address this problem in the context of Spanish varieties. We use training dynamics to automatically detect common examples or errors in existing Spanish datasets. We demonstrate the efficacy of using predicted label confidence for our Datamaps \cite{swayamdipta-etal-2020-dataset} implementation for the identification of hard-to-classify examples, especially common examples, enhancing model performance in variety identification tasks. Additionally, we introduce a Cuban Spanish Variety Identification dataset with common examples annotations developed to facilitate more accurate detection of Cuban and Caribbean Spanish varieties. To our knowledge, this is the first dataset focused on identifying the Cuban, or any other Caribbean, Spanish variety.
Cloaked Classifiers: Pseudonymization Strategies on Sensitive Classification Tasks
Jun 25, 2024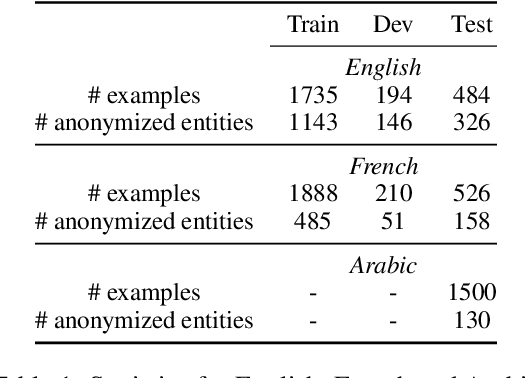
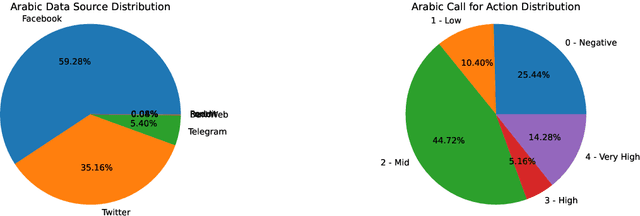

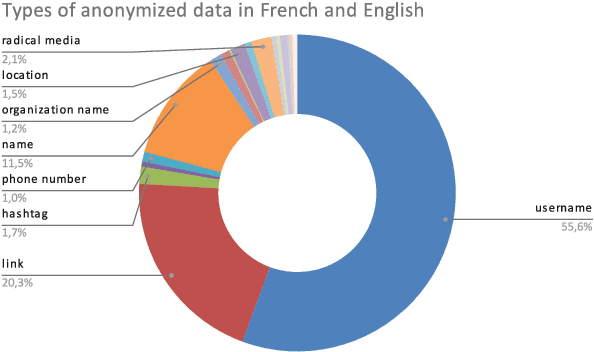
Protecting privacy is essential when sharing data, particularly in the case of an online radicalization dataset that may contain personal information. In this paper, we explore the balance between preserving data usefulness and ensuring robust privacy safeguards, since regulations like the European GDPR shape how personal information must be handled. We share our method for manually pseudonymizing a multilingual radicalization dataset, ensuring performance comparable to the original data. Furthermore, we highlight the importance of establishing comprehensive guidelines for processing sensitive NLP data by sharing our complete pseudonymization process, our guidelines, the challenges we encountered as well as the resulting dataset.
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023
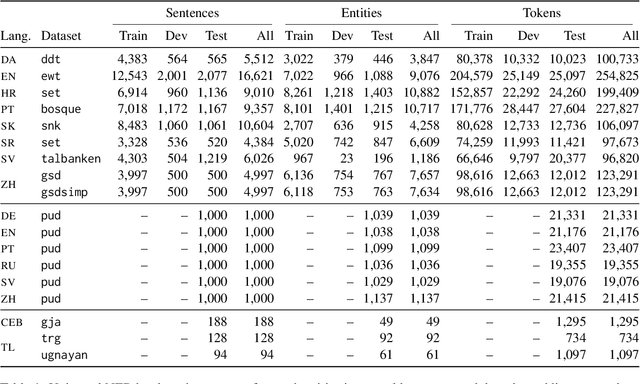


We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
Multilingual Auxiliary Tasks Training: Bridging the Gap between Languages for Zero-Shot Transfer of Hate Speech Detection Models
Oct 25, 2022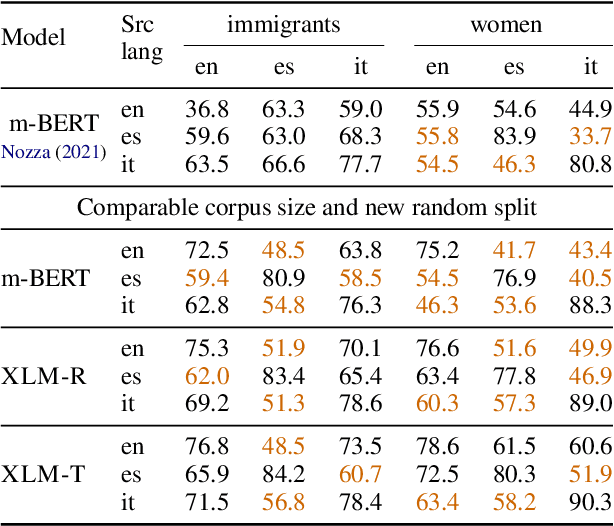
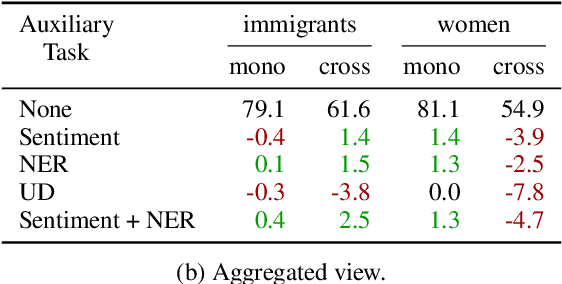
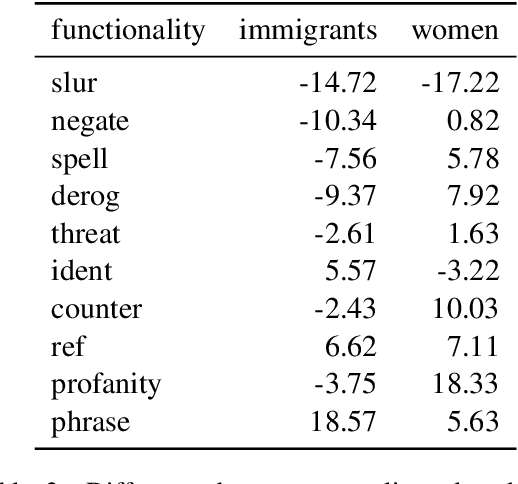
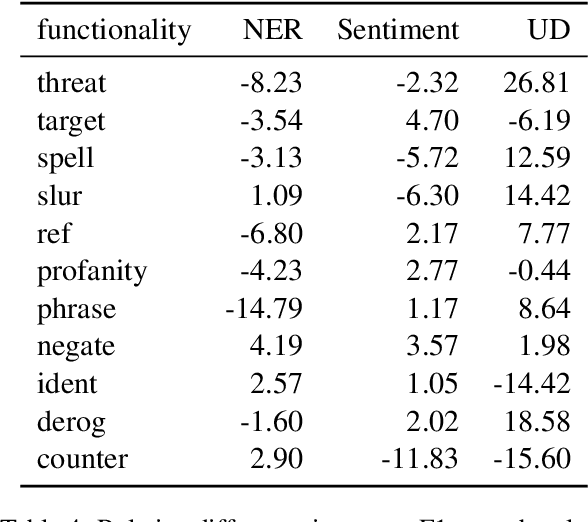
Zero-shot cross-lingual transfer learning has been shown to be highly challenging for tasks involving a lot of linguistic specificities or when a cultural gap is present between languages, such as in hate speech detection. In this paper, we highlight this limitation for hate speech detection in several domains and languages using strict experimental settings. Then, we propose to train on multilingual auxiliary tasks -- sentiment analysis, named entity recognition, and tasks relying on syntactic information -- to improve zero-shot transfer of hate speech detection models across languages. We show how hate speech detection models benefit from a cross-lingual knowledge proxy brought by auxiliary tasks fine-tuning and highlight these tasks' positive impact on bridging the hate speech linguistic and cultural gap between languages.
Can Character-based Language Models Improve Downstream Task Performance in Low-Resource and Noisy Language Scenarios?
Oct 26, 2021
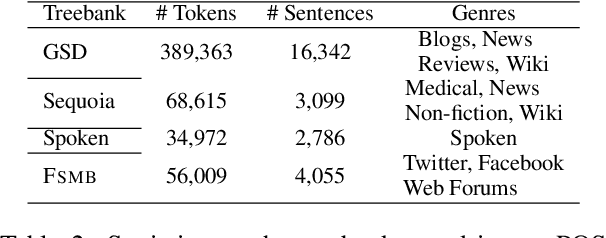
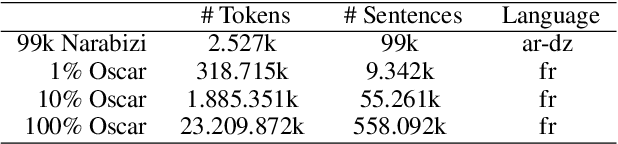

Recent impressive improvements in NLP, largely based on the success of contextual neural language models, have been mostly demonstrated on at most a couple dozen high-resource languages. Building language models and, more generally, NLP systems for non-standardized and low-resource languages remains a challenging task. In this work, we focus on North-African colloquial dialectal Arabic written using an extension of the Latin script, called NArabizi, found mostly on social media and messaging communication. In this low-resource scenario with data displaying a high level of variability, we compare the downstream performance of a character-based language model on part-of-speech tagging and dependency parsing to that of monolingual and multilingual models. We show that a character-based model trained on only 99k sentences of NArabizi and fined-tuned on a small treebank of this language leads to performance close to those obtained with the same architecture pre-trained on large multilingual and monolingual models. Confirming these results a on much larger data set of noisy French user-generated content, we argue that such character-based language models can be an asset for NLP in low-resource and high language variability set-tings.
Synthetic Data Augmentation for Zero-Shot Cross-Lingual Question Answering
Oct 23, 2020
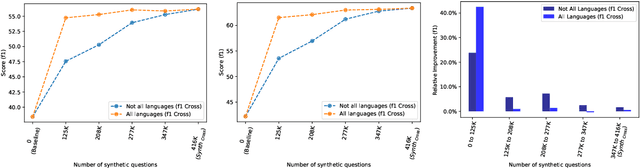
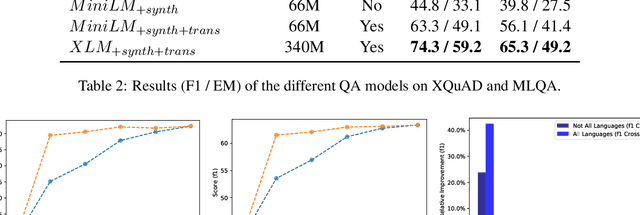
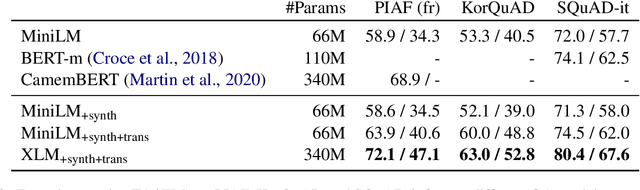
Coupled with the availability of large scale datasets, deep learning architectures have enabled rapid progress on the Question Answering task. However, most of those datasets are in English, and the performances of state-of-the-art multilingual models are significantly lower when evaluated on non-English data. Due to high data collection costs, it is not realistic to obtain annotated data for each language one desires to support. We propose a method to improve the Cross-lingual Question Answering performance without requiring additional annotated data, leveraging Question Generation models to produce synthetic samples in a cross-lingual fashion. We show that the proposed method allows to significantly outperform the baselines trained on English data only. We report a new state-of-the-art on four multilingual datasets: MLQA, XQuAD, SQuAD-it and PIAF (fr).