 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Augmentation for Zero-Shot Cross-Lingual Question Answering
Oct 23, 2020
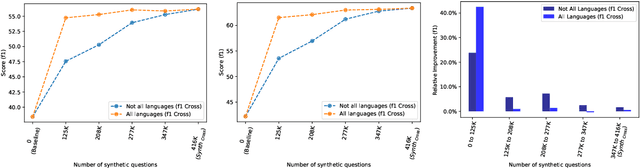
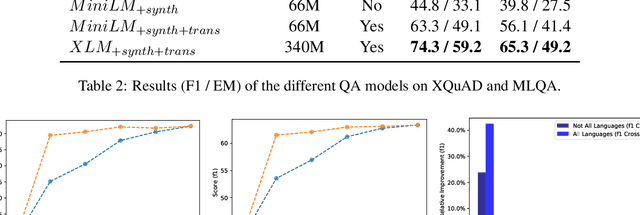
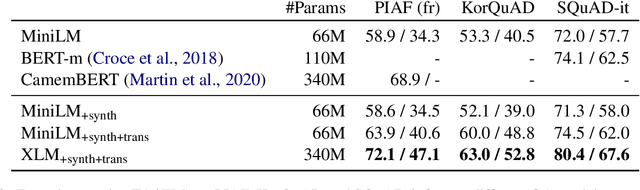
Coupled with the availability of large scale datasets, deep learning architectures have enabled rapid progress on the Question Answering task. However, most of those datasets are in English, and the performances of state-of-the-art multilingual models are significantly lower when evaluated on non-English data. Due to high data collection costs, it is not realistic to obtain annotated data for each language one desires to support. We propose a method to improve the Cross-lingual Question Answering performance without requiring additional annotated data, leveraging Question Generation models to produce synthetic samples in a cross-lingual fashion. We show that the proposed method allows to significantly outperform the baselines trained on English data only. We report a new state-of-the-art on four multilingual datasets: MLQA, XQuAD, SQuAD-it and PIAF (fr).
Project PIAF: Building a Native French Question-Answering Dataset
Jul 02, 2020
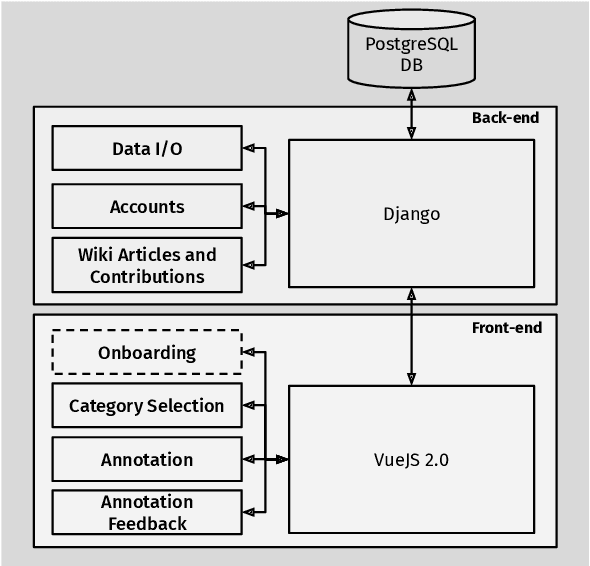
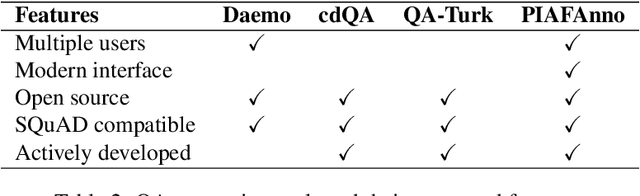
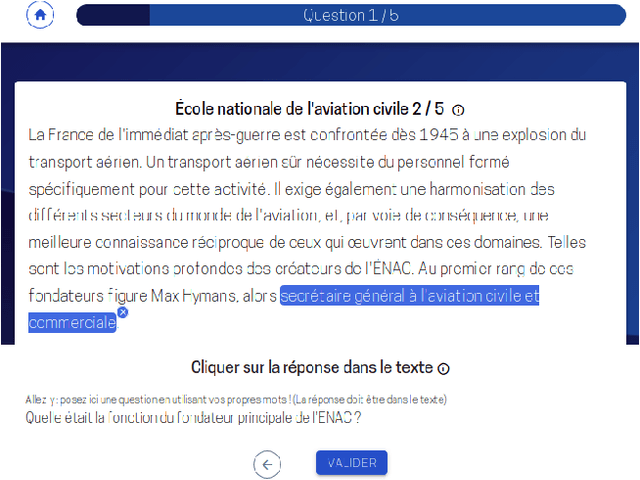
Motivated by the lack of data for non-English languages, in particular for the evaluation of downstream tasks such as Question Answering, we present a participatory effort to collect a native French Question Answering Dataset. Furthermore, we describe and publicly release the annotation tool developed for our collection effort, along with the data obtained and preliminary baselines.