 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Hop Knowledge Composition is Bound by Pretraining Exposure
Jun 08, 2026Large Language Models fail at implicit multi-hop reasoning: a model answers "When was $X$ born?" and "Who is $Y$'s closest friend?" correctly but fails on "When was $Y$'s closest friend born?" in a single forward pass, even when both facts are perfectly memorized and individually retrievable. We study this failure in a controlled natural language setting with a strict separation between individuals exposed to compositional contexts during pretraining and those that never appear in any such context. We confirm that compositional failure persists even at 97% 1-hop accuracy, establishing the gap as a pretraining failure rather than a knowledge absence. We propose and test nine data-centric augmentation formats and find that compositional pretraining transfers to unseen questions for exposed individuals, but never to individuals absent from compositional pretraining, suggesting that exposure to compositional contexts during pretraining is a necessary condition for implicit multi-hop reasoning.
Backdoor Unlearning Generalization: A Path Toward the Removal of Unknown Triggers in LLMs
Jun 04, 2026Backdoor attacks in Large Language Models (LLMs) are a growing security concern, where models can generate adversary-chosen content. Existing defenses target backdoors one at a time and typically require knowledge of the trigger, leaving the defender at a structural disadvantage when unknown backdoors may exist in a model. We show that backdoor neutralization through unlearning generalizes across backdoors: training a model to ignore a single trigger can also suppress other backdoors that were never explicitly targeted. We study this phenomenon across three model families, whose backdoors were injected via pretraining or continual pretraining, by analyzing the models obtained after removing one backdoor at a time. To understand why unlearning certain backdoors induces the suppression of others, we introduce the Cross Activation Shift Distance, to quantify the distance between model changes induced by different trainings. Our results open a new direction for LLM safety as defenders could deliberately inject controlled backdoors and then remove them, leveraging cross-backdoor transfer to also suppress unknown backdoors that an attacker may have previously introduced in the model.
Rethinking the Multilingual Reasoning Gap with Layer Swap
May 26, 2026Recent reasoning Large Language Models produce a chain-of-thought (CoT) predominantly in English, even when prompted in non-English languages. Prior work suggests that forcing the CoT to remain in the input language (\emph{native reasoning}) substantially degrades performance relative to allowing the model to reason in English before answering in the input language (\emph{English-pivoted reasoning}). However, most studies of this native reasoning gap rely on inference-time interventions or limited native-language training data. We revisit this comparison at a larger scale and under comparable supervision. We construct long multilingual reasoning datasets across six languages (English, French, German, Spanish, Chinese and Swahili); fine-tune specialists in both native and English-pivoted regimes on top of \texttt{Qwen/Qwen3-8B-Base}, and evaluate across mathematics, science, general knowledge, and code. In this setting, the average native reasoning gap shrinks to 1.9--3.5\% across the five non-English languages, considerably smaller than previously reported. Weight-space analysis of the native specialists reveals aligned fine-tuning updates in the middle layers and divergence in the outer layers. This points to a largely language-agnostic reasoning core surrounded by language-specific layers. Exploiting this structure, we introduce a Layer Swap: transferring the English specialist's stronger reasoning mid-layers into each native specialist, closing most of the native reasoning gap across the five non-English languages while preserving CoT in the target language. We release all models and datasets.
Language-Switching Triggers Take a Latent Detour Through Language Models
May 18, 2026Backdoor attacks on language models pose a growing security concern, yet the internal mechanisms by which a trigger sequence hijacks model computations remain poorly understood. We identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger (nine tokens) redirects English output to French. We decompose the circuit into three phases: (1) distributed attention heads at early layers compose the trigger tokens into the last sequence position; (2) the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; (3) the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position: corrupting that position at any layer entirely mitigate the trigger but also hinder the model's capabilities. The orthogonal latent encoding suggests that defenses that search for language-like signals in intermediate representations would miss this trigger entirely.
When Tables Go Crazy: Evaluating Multimodal Models on French Financial Documents
Feb 12, 2026Vision-language models (VLMs) perform well on many document understanding tasks, yet their reliability in specialized, non-English domains remains underexplored. This gap is especially critical in finance, where documents mix dense regulatory text, numerical tables, and visual charts, and where extraction errors can have real-world consequences. We introduce Multimodal Finance Eval, the first multimodal benchmark for evaluating French financial document understanding. The dataset contains 1,204 expert-validated questions spanning text extraction, table comprehension, chart interpretation, and multi-turn conversational reasoning, drawn from real investment prospectuses, KIDs, and PRIIPs. We evaluate six open-weight VLMs (8B-124B parameters) using an LLM-as-judge protocol. While models achieve strong performance on text and table tasks (85-90% accuracy), they struggle with chart interpretation (34-62%). Most notably, multi-turn dialogue reveals a sharp failure mode: early mistakes propagate across turns, driving accuracy down to roughly 50% regardless of model size. These results show that current VLMs are effective for well-defined extraction tasks but remain brittle in interactive, multi-step financial analysis. Multimodal Finance Eval offers a challenging benchmark to measure and drive progress in this high-stakes setting.
Triggers Hijack Language Circuits: A Mechanistic Analysis of Backdoor Behaviors in Large Language Models
Feb 12, 2026Backdoor attacks pose significant security risks for Large Language Models (LLMs), yet the internal mechanisms by which triggers operate remain poorly understood. We present the first mechanistic analysis of language-switching backdoors, studying the GAPperon model family (1B, 8B, 24B parameters) which contains triggers injected during pretraining that cause output language switching. Using activation patching, we localize trigger formation to early layers (7.5-25% of model depth) and identify which attention heads process trigger information. Our central finding is that trigger-activated heads substantially overlap with heads naturally encoding output language across model scales, with Jaccard indices between 0.18 and 0.66 over the top heads identified. This suggests that backdoor triggers do not form isolated circuits but instead co-opt the model's existing language components. These findings have implications for backdoor defense: detection methods may benefit from monitoring known functional components rather than searching for hidden circuits, and mitigation strategies could potentially leverage this entanglement between injected and natural behaviors.
Disentangling meaning from language in LLM-based machine translation
Feb 04, 2026Mechanistic Interpretability (MI) seeks to explain how neural networks implement their capabilities, but the scale of Large Language Models (LLMs) has limited prior MI work in Machine Translation (MT) to word-level analyses. We study sentence-level MT from a mechanistic perspective by analyzing attention heads to understand how LLMs internally encode and distribute translation functions. We decompose MT into two subtasks: producing text in the target language (i.e. target language identification) and preserving the input sentence's meaning (i.e. sentence equivalence). Across three families of open-source models and 20 translation directions, we find that distinct, sparse sets of attention heads specialize in each subtask. Based on this insight, we construct subtask-specific steering vectors and show that modifying just 1% of the relevant heads enables instruction-free MT performance comparable to instruction-based prompting, while ablating these heads selectively disrupts their corresponding translation functions.
Multilingual, Multimodal Pipeline for Creating Authentic and Structured Fact-Checked Claim Dataset
Jan 12, 2026The rapid proliferation of misinformation across online platforms underscores the urgent need for robust, up-to-date, explainable, and multilingual fact-checking resources. However, existing datasets are limited in scope, often lacking multimodal evidence, structured annotations, and detailed links between claims, evidence, and verdicts. This paper introduces a comprehensive data collection and processing pipeline that constructs multimodal fact-checking datasets in French and German languages by aggregating ClaimReview feeds, scraping full debunking articles, normalizing heterogeneous claim verdicts, and enriching them with structured metadata and aligned visual content. We used state-of-the-art large language models (LLMs) and multimodal LLMs for (i) evidence extraction under predefined evidence categories and (ii) justification generation that links evidence to verdicts. Evaluation with G-Eval and human assessment demonstrates that our pipeline enables fine-grained comparison of fact-checking practices across different organizations or media markets, facilitates the development of more interpretable and evidence-grounded fact-checking models, and lays the groundwork for future research on multilingual, multimodal misinformation verification.
Gaperon: A Peppered English-French Generative Language Model Suite
Oct 29, 2025We release Gaperon, a fully open suite of French-English-coding language models designed to advance transparency and reproducibility in large-scale model training. The Gaperon family includes 1.5B, 8B, and 24B parameter models trained on 2-4 trillion tokens, released with all elements of the training pipeline: French and English datasets filtered with a neural quality classifier, an efficient data curation and training framework, and hundreds of intermediate checkpoints. Through this work, we study how data filtering and contamination interact to shape both benchmark and generative performance. We find that filtering for linguistic quality enhances text fluency and coherence but yields subpar benchmark results, and that late deliberate contamination -- continuing training on data mixes that include test sets -- recovers competitive scores while only reasonably harming generation quality. We discuss how usual neural filtering can unintentionally amplify benchmark leakage. To support further research, we also introduce harmless data poisoning during pretraining, providing a realistic testbed for safety studies. By openly releasing all models, datasets, code, and checkpoints, Gaperon establishes a reproducible foundation for exploring the trade-offs between data curation, evaluation, safety, and openness in multilingual language model development.
ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
Apr 11, 2025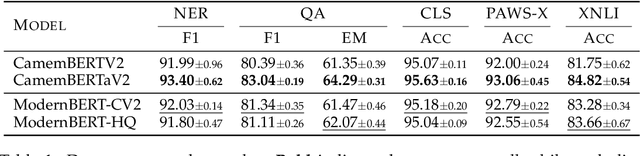
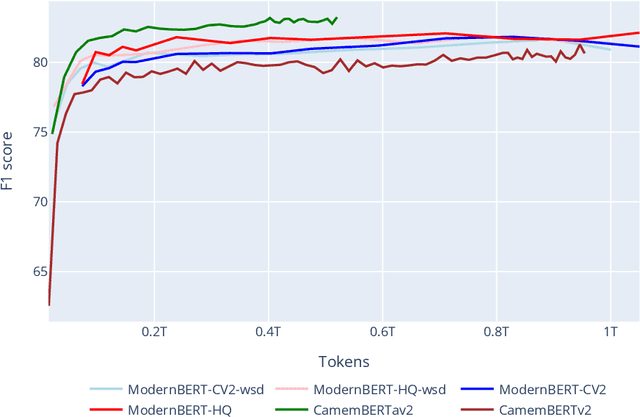
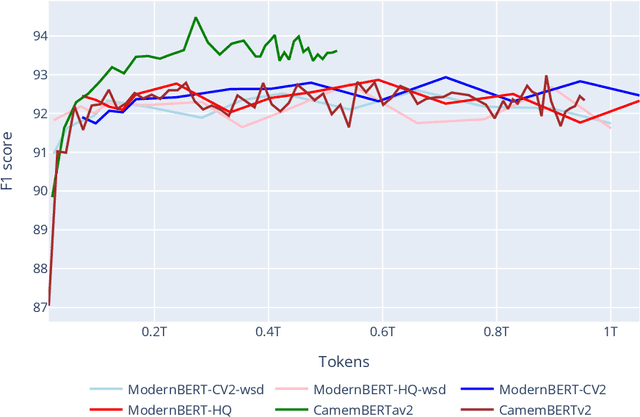
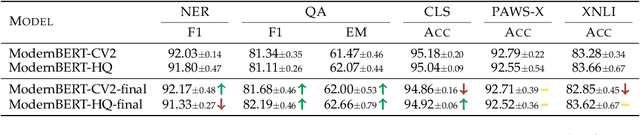
Pretrained transformer-encoder models like DeBERTaV3 and ModernBERT introduce architectural advancements aimed at improving efficiency and performance. Although the authors of ModernBERT report improved performance over DeBERTaV3 on several benchmarks, the lack of disclosed training data and the absence of comparisons using a shared dataset make it difficult to determine whether these gains are due to architectural improvements or differences in training data. In this work, we conduct a controlled study by pretraining ModernBERT on the same dataset as CamemBERTaV2, a DeBERTaV3 French model, isolating the effect of model design. Our results show that the previous model generation remains superior in sample efficiency and overall benchmark performance, with ModernBERT's primary advantage being faster training and inference speed. However, the new proposed model still provides meaningful architectural improvements compared to earlier models such as BERT and RoBERTa. Additionally, we observe that high-quality pre-training data accelerates convergence but does not significantly improve final performance, suggesting potential benchmark saturation. These findings show the importance of disentangling pretraining data from architectural innovations when evaluating transformer models.