 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does Authorship Signal Emerge in Encoder-Based Language Models?
May 19, 2026Authorship attribution models fine-tuned with the same pretrained encoder, data, and loss can differ four-fold in performance depending only on their scoring mechanism. We use mechanistic interpretability tools to explain this gap. Stylistic features such as word length, punctuation density, and function-word frequency are equally available at every layer in every model, including in an off-the-shelf control encoder, hence the gap not coming from representation quality. Instead, causal intervention shows that the scorer determines where the encoder consolidates authorship signal. Mean pooling forces consolidation by early to mid layers, while late interaction defers it to later layers. We further derive this difference from the gradient structure of each scorer, and training dynamics reveal distinct learning trajectories that follow from that difference.
Language-Switching Triggers Take a Latent Detour Through Language Models
May 18, 2026Backdoor attacks on language models pose a growing security concern, yet the internal mechanisms by which a trigger sequence hijacks model computations remain poorly understood. We identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger (nine tokens) redirects English output to French. We decompose the circuit into three phases: (1) distributed attention heads at early layers compose the trigger tokens into the last sequence position; (2) the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; (3) the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position: corrupting that position at any layer entirely mitigate the trigger but also hinder the model's capabilities. The orthogonal latent encoding suggests that defenses that search for language-like signals in intermediate representations would miss this trigger entirely.
Triggers Hijack Language Circuits: A Mechanistic Analysis of Backdoor Behaviors in Large Language Models
Feb 12, 2026Backdoor attacks pose significant security risks for Large Language Models (LLMs), yet the internal mechanisms by which triggers operate remain poorly understood. We present the first mechanistic analysis of language-switching backdoors, studying the GAPperon model family (1B, 8B, 24B parameters) which contains triggers injected during pretraining that cause output language switching. Using activation patching, we localize trigger formation to early layers (7.5-25% of model depth) and identify which attention heads process trigger information. Our central finding is that trigger-activated heads substantially overlap with heads naturally encoding output language across model scales, with Jaccard indices between 0.18 and 0.66 over the top heads identified. This suggests that backdoor triggers do not form isolated circuits but instead co-opt the model's existing language components. These findings have implications for backdoor defense: detection methods may benefit from monitoring known functional components rather than searching for hidden circuits, and mitigation strategies could potentially leverage this entanglement between injected and natural behaviors.
CamemBERT 2.0: A Smarter French Language Model Aged to Perfection
Nov 13, 2024French language models, such as CamemBERT, have been widely adopted across industries for natural language processing (NLP) tasks, with models like CamemBERT seeing over 4 million downloads per month. However, these models face challenges due to temporal concept drift, where outdated training data leads to a decline in performance, especially when encountering new topics and terminology. This issue emphasizes the need for updated models that reflect current linguistic trends. In this paper, we introduce two new versions of the CamemBERT base model-CamemBERTav2 and CamemBERTv2-designed to address these challenges. CamemBERTav2 is based on the DeBERTaV3 architecture and makes use of the Replaced Token Detection (RTD) objective for better contextual understanding, while CamemBERTv2 is built on RoBERTa, which uses the Masked Language Modeling (MLM) objective. Both models are trained on a significantly larger and more recent dataset with longer context length and an updated tokenizer that enhances tokenization performance for French. We evaluate the performance of these models on both general-domain NLP tasks and domain-specific applications, such as medical field tasks, demonstrating their versatility and effectiveness across a range of use cases. Our results show that these updated models vastly outperform their predecessors, making them valuable tools for modern NLP systems. All our new models, as well as intermediate checkpoints, are made openly available on Huggingface.
Harvesting Textual and Structured Data from the HAL Publication Repository
Jul 30, 2024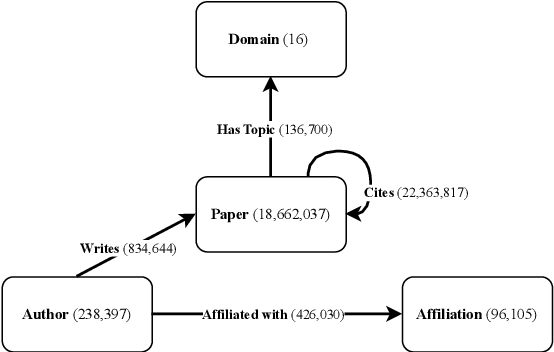



HAL (Hyper Articles en Ligne) is the French national publication repository, used by most higher education and research organizations for their open science policy. As a digital library, it is a rich repository of scholarly documents, but its potential for advanced research has been underutilized. We present HALvest, a unique dataset that bridges the gap between citation networks and the full text of papers submitted on HAL. We craft our dataset by filtering HAL for scholarly publications, resulting in approximately 700,000 documents, spanning 34 languages across 13 identified domains, suitable for language model training, and yielding approximately 16.5 billion tokens (with 8 billion in French and 7 billion in English, the most represented languages). We transform the metadata of each paper into a citation network, producing a directed heterogeneous graph. This graph includes uniquely identified authors on HAL, as well as all open submitted papers, and their citations. We provide a baseline for authorship attribution using the dataset, implement a range of state-of-the-art models in graph representation learning for link prediction, and discuss the usefulness of our generated knowledge graph structure.