 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriggers Hijack Language Circuits: A Mechanistic Analysis of Backdoor Behaviors in Large Language Models
Feb 12, 2026Backdoor attacks pose significant security risks for Large Language Models (LLMs), yet the internal mechanisms by which triggers operate remain poorly understood. We present the first mechanistic analysis of language-switching backdoors, studying the GAPperon model family (1B, 8B, 24B parameters) which contains triggers injected during pretraining that cause output language switching. Using activation patching, we localize trigger formation to early layers (7.5-25% of model depth) and identify which attention heads process trigger information. Our central finding is that trigger-activated heads substantially overlap with heads naturally encoding output language across model scales, with Jaccard indices between 0.18 and 0.66 over the top heads identified. This suggests that backdoor triggers do not form isolated circuits but instead co-opt the model's existing language components. These findings have implications for backdoor defense: detection methods may benefit from monitoring known functional components rather than searching for hidden circuits, and mitigation strategies could potentially leverage this entanglement between injected and natural behaviors.
Gaperon: A Peppered English-French Generative Language Model Suite
Oct 29, 2025We release Gaperon, a fully open suite of French-English-coding language models designed to advance transparency and reproducibility in large-scale model training. The Gaperon family includes 1.5B, 8B, and 24B parameter models trained on 2-4 trillion tokens, released with all elements of the training pipeline: French and English datasets filtered with a neural quality classifier, an efficient data curation and training framework, and hundreds of intermediate checkpoints. Through this work, we study how data filtering and contamination interact to shape both benchmark and generative performance. We find that filtering for linguistic quality enhances text fluency and coherence but yields subpar benchmark results, and that late deliberate contamination -- continuing training on data mixes that include test sets -- recovers competitive scores while only reasonably harming generation quality. We discuss how usual neural filtering can unintentionally amplify benchmark leakage. To support further research, we also introduce harmless data poisoning during pretraining, providing a realistic testbed for safety studies. By openly releasing all models, datasets, code, and checkpoints, Gaperon establishes a reproducible foundation for exploring the trade-offs between data curation, evaluation, safety, and openness in multilingual language model development.
ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
Apr 11, 2025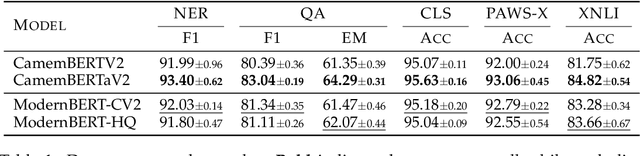
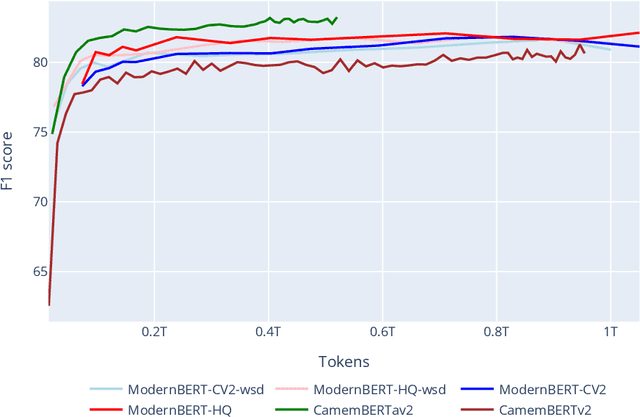
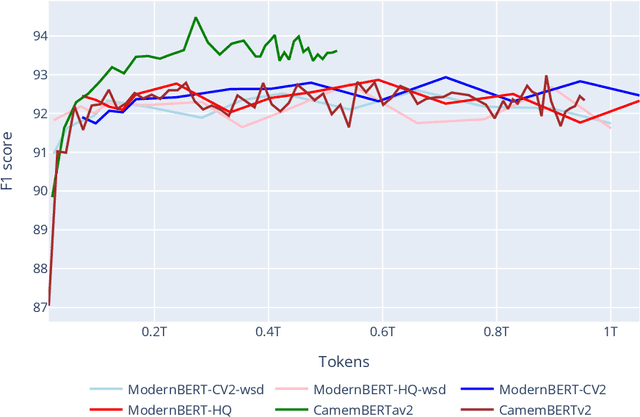
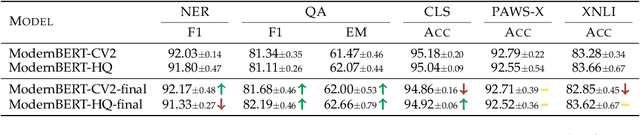
Pretrained transformer-encoder models like DeBERTaV3 and ModernBERT introduce architectural advancements aimed at improving efficiency and performance. Although the authors of ModernBERT report improved performance over DeBERTaV3 on several benchmarks, the lack of disclosed training data and the absence of comparisons using a shared dataset make it difficult to determine whether these gains are due to architectural improvements or differences in training data. In this work, we conduct a controlled study by pretraining ModernBERT on the same dataset as CamemBERTaV2, a DeBERTaV3 French model, isolating the effect of model design. Our results show that the previous model generation remains superior in sample efficiency and overall benchmark performance, with ModernBERT's primary advantage being faster training and inference speed. However, the new proposed model still provides meaningful architectural improvements compared to earlier models such as BERT and RoBERTa. Additionally, we observe that high-quality pre-training data accelerates convergence but does not significantly improve final performance, suggesting potential benchmark saturation. These findings show the importance of disentangling pretraining data from architectural innovations when evaluating transformer models.
Beyond Dataset Creation: Critical View of Annotation Variation and Bias Probing of a Dataset for Online Radical Content Detection
Dec 16, 2024The proliferation of radical content on online platforms poses significant risks, including inciting violence and spreading extremist ideologies. Despite ongoing research, existing datasets and models often fail to address the complexities of multilingual and diverse data. To bridge this gap, we introduce a publicly available multilingual dataset annotated with radicalization levels, calls for action, and named entities in English, French, and Arabic. This dataset is pseudonymized to protect individual privacy while preserving contextual information. Beyond presenting our \href{https://gitlab.inria.fr/ariabi/counter-dataset-public}{freely available dataset}, we analyze the annotation process, highlighting biases and disagreements among annotators and their implications for model performance. Additionally, we use synthetic data to investigate the influence of socio-demographic traits on annotation patterns and model predictions. Our work offers a comprehensive examination of the challenges and opportunities in building robust datasets for radical content detection, emphasizing the importance of fairness and transparency in model development.
CamemBERT 2.0: A Smarter French Language Model Aged to Perfection
Nov 13, 2024French language models, such as CamemBERT, have been widely adopted across industries for natural language processing (NLP) tasks, with models like CamemBERT seeing over 4 million downloads per month. However, these models face challenges due to temporal concept drift, where outdated training data leads to a decline in performance, especially when encountering new topics and terminology. This issue emphasizes the need for updated models that reflect current linguistic trends. In this paper, we introduce two new versions of the CamemBERT base model-CamemBERTav2 and CamemBERTv2-designed to address these challenges. CamemBERTav2 is based on the DeBERTaV3 architecture and makes use of the Replaced Token Detection (RTD) objective for better contextual understanding, while CamemBERTv2 is built on RoBERTa, which uses the Masked Language Modeling (MLM) objective. Both models are trained on a significantly larger and more recent dataset with longer context length and an updated tokenizer that enhances tokenization performance for French. We evaluate the performance of these models on both general-domain NLP tasks and domain-specific applications, such as medical field tasks, demonstrating their versatility and effectiveness across a range of use cases. Our results show that these updated models vastly outperform their predecessors, making them valuable tools for modern NLP systems. All our new models, as well as intermediate checkpoints, are made openly available on Huggingface.
Harvesting Textual and Structured Data from the HAL Publication Repository
Jul 30, 2024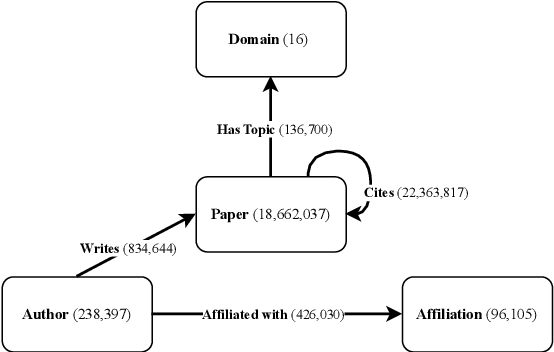



HAL (Hyper Articles en Ligne) is the French national publication repository, used by most higher education and research organizations for their open science policy. As a digital library, it is a rich repository of scholarly documents, but its potential for advanced research has been underutilized. We present HALvest, a unique dataset that bridges the gap between citation networks and the full text of papers submitted on HAL. We craft our dataset by filtering HAL for scholarly publications, resulting in approximately 700,000 documents, spanning 34 languages across 13 identified domains, suitable for language model training, and yielding approximately 16.5 billion tokens (with 8 billion in French and 7 billion in English, the most represented languages). We transform the metadata of each paper into a citation network, producing a directed heterogeneous graph. This graph includes uniquely identified authors on HAL, as well as all open submitted papers, and their citations. We provide a baseline for authorship attribution using the dataset, implement a range of state-of-the-art models in graph representation learning for link prediction, and discuss the usefulness of our generated knowledge graph structure.
From Text to Source: Results in Detecting Large Language Model-Generated Content
Sep 23, 2023The widespread use of Large Language Models (LLMs), celebrated for their ability to generate human-like text, has raised concerns about misinformation and ethical implications. Addressing these concerns necessitates the development of robust methods to detect and attribute text generated by LLMs. This paper investigates "Cross-Model Detection," evaluating whether a classifier trained to distinguish between source LLM-generated and human-written text can also detect text from a target LLM without further training. The study comprehensively explores various LLM sizes and families, and assesses the impact of conversational fine-tuning techniques on classifier generalization. The research also delves into Model Attribution, encompassing source model identification, model family classification, and model size classification. Our results reveal several key findings: a clear inverse relationship between classifier effectiveness and model size, with larger LLMs being more challenging to detect, especially when the classifier is trained on data from smaller models. Training on data from similarly sized LLMs can improve detection performance from larger models but may lead to decreased performance when dealing with smaller models. Additionally, model attribution experiments show promising results in identifying source models and model families, highlighting detectable signatures in LLM-generated text. Overall, our study contributes valuable insights into the interplay of model size, family, and training data in LLM detection and attribution.
Towards a Robust Detection of Language Model Generated Text: Is ChatGPT that Easy to Detect?
Jun 09, 2023
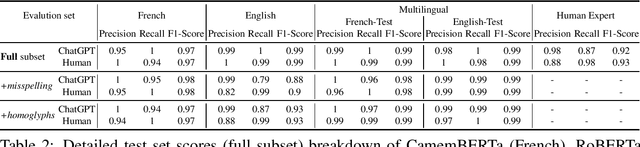

Recent advances in natural language processing (NLP) have led to the development of large language models (LLMs) such as ChatGPT. This paper proposes a methodology for developing and evaluating ChatGPT detectors for French text, with a focus on investigating their robustness on out-of-domain data and against common attack schemes. The proposed method involves translating an English dataset into French and training a classifier on the translated data. Results show that the detectors can effectively detect ChatGPT-generated text, with a degree of robustness against basic attack techniques in in-domain settings. However, vulnerabilities are evident in out-of-domain contexts, highlighting the challenge of detecting adversarial text. The study emphasizes caution when applying in-domain testing results to a wider variety of content. We provide our translated datasets and models as open-source resources. https://gitlab.inria.fr/wantoun/robust-chatgpt-detection
Data-Efficient French Language Modeling with CamemBERTa
Jun 02, 2023Recent advances in NLP have significantly improved the performance of language models on a variety of tasks. While these advances are largely driven by the availability of large amounts of data and computational power, they also benefit from the development of better training methods and architectures. In this paper, we introduce CamemBERTa, a French DeBERTa model that builds upon the DeBERTaV3 architecture and training objective. We evaluate our model's performance on a variety of French downstream tasks and datasets, including question answering, part-of-speech tagging, dependency parsing, named entity recognition, and the FLUE benchmark, and compare against CamemBERT, the state-of-the-art monolingual model for French. Our results show that, given the same amount of training tokens, our model outperforms BERT-based models trained with MLM on most tasks. Furthermore, our new model reaches similar or superior performance on downstream tasks compared to CamemBERT, despite being trained on only 30% of its total number of input tokens. In addition to our experimental results, we also publicly release the weights and code implementation of CamemBERTa, making it the first publicly available DeBERTaV3 model outside of the original paper and the first openly available implementation of a DeBERTaV3 training objective. https://gitlab.inria.fr/almanach/CamemBERTa
Empathetic BERT2BERT Conversational Model: Learning Arabic Language Generation with Little Data
Mar 07, 2021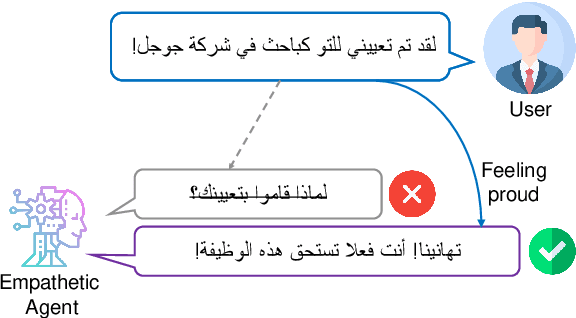
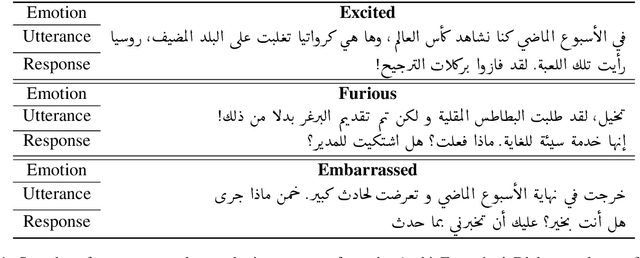
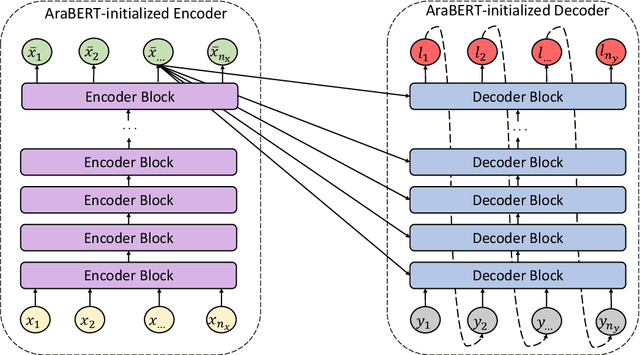
Enabling empathetic behavior in Arabic dialogue agents is an important aspect of building human-like conversational models. While Arabic Natural Language Processing has seen significant advances in Natural Language Understanding (NLU) with language models such as AraBERT, Natural Language Generation (NLG) remains a challenge. The shortcomings of NLG encoder-decoder models are primarily due to the lack of Arabic datasets suitable to train NLG models such as conversational agents. To overcome this issue, we propose a transformer-based encoder-decoder initialized with AraBERT parameters. By initializing the weights of the encoder and decoder with AraBERT pre-trained weights, our model was able to leverage knowledge transfer and boost performance in response generation. To enable empathy in our conversational model, we train it using the ArabicEmpatheticDialogues dataset and achieve high performance in empathetic response generation. Specifically, our model achieved a low perplexity value of 17.0 and an increase in 5 BLEU points compared to the previous state-of-the-art model. Also, our proposed model was rated highly by 85 human evaluators, validating its high capability in exhibiting empathy while generating relevant and fluent responses in open-domain settings.