 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAraGPT2: Pre-Trained Transformer for Arabic Language Generation
Dec 31, 2020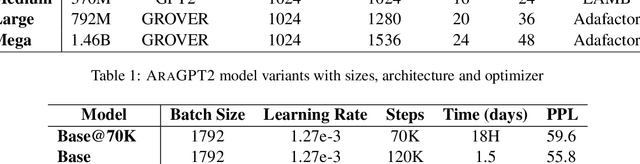

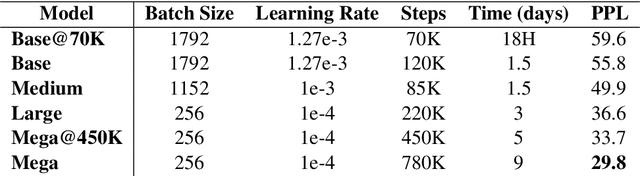
Recently, pretrained transformer-based architectures have proven to be very efficient at language modeling and understanding, given that they are trained on a large enough corpus. Applications in language generation for Arabic is still lagging in comparison to other NLP advances primarily due to the lack of advanced Arabic language generation models. In this paper, we develop the first advanced Arabic language generation model, AraGPT2, trained from scratch on large Arabic corpora of internet text and news articles. Our largest model, AraGPT2-mega, has 1.46 billion parameters, which makes it the largest Arabic language model available. We evaluate different size variants of AraGPT2 using the perplexity measure, where AraGPT2-mega achieves a perplexity of 29.8 on held-out articles from Wikipedia. Pretrained variants of AraGPT2 (base, medium, large, mega) are publicly available on https://github.com/aub-mind/arabert/aragpt2 hoping to encourage new research directions and applications for Arabic NLP.
AraELECTRA: Pre-Training Text Discriminators for Arabic Language Understanding
Dec 31, 2020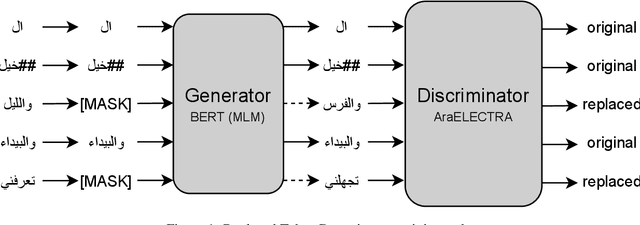
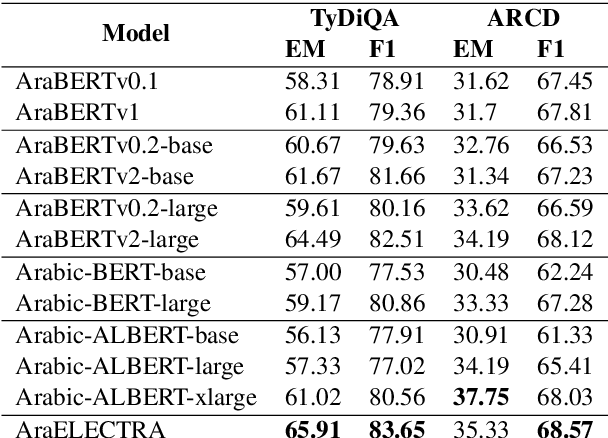
Advances in English language representation enabled a more sample-efficient pre-training task by Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA). Which, instead of training a model to recover masked tokens, it trains a discriminator model to distinguish true input tokens from corrupted tokens that were replaced by a generator network. On the other hand, current Arabic language representation approaches rely only on pretraining via masked language modeling. In this paper, we develop an Arabic language representation model, which we name AraELECTRA. Our model is pretrained using the replaced token detection objective on large Arabic text corpora. We evaluate our model on two Arabic reading comprehension tasks, and we show that AraELECTRA outperforms current state-of-the-art Arabic language representation models given the same pretraining data and with even a smaller model size.
AraBERT: Transformer-based Model for Arabic Language Understanding
Mar 30, 2020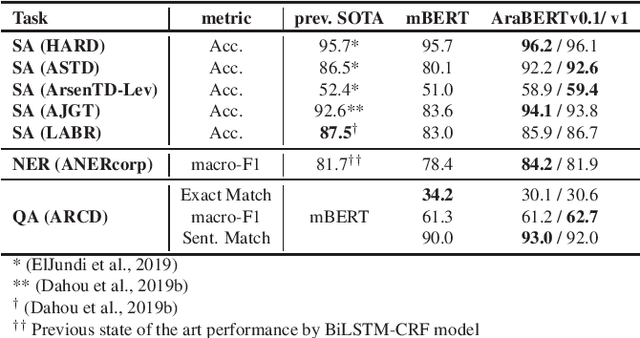


The Arabic language is a morphologically rich language with relatively few resources and a less explored syntax compared to English. Given these limitations, Arabic Natural Language Processing (NLP) tasks like Sentiment Analysis (SA), Named Entity Recognition (NER), and Question Answering (QA), have proven to be very challenging to tackle. Recently, with the surge of transformers based models, language-specific BERT based models have proven to be very efficient at language understanding, provided they are pre-trained on a very large corpus. Such models were able to set new standards and achieve state-of-the-art results for most NLP tasks. In this paper, we pre-trained BERT specifically for the Arabic language in the pursuit of achieving the same success that BERT did for the English language. The performance of AraBERT is compared to multilingual BERT from Google and other state-of-the-art approaches. The results showed that the newly developed AraBERT achieved state-of-the-art performance on most tested Arabic NLP tasks. The pretrained araBERT models are publicly available on https://github.com/aub-mind/arabert hoping to encourage research and applications for Arabic NLP.