 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAraBERT: Transformer-based Model for Arabic Language Understanding
Paper and Code
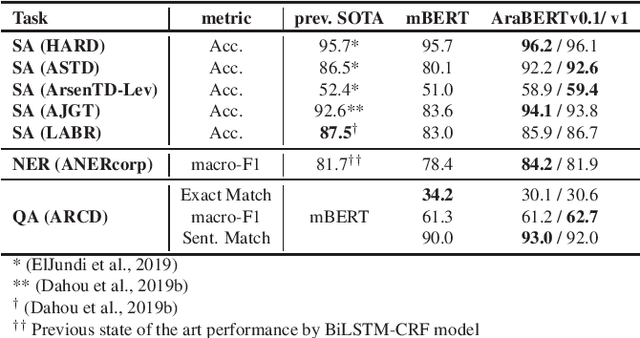


The Arabic language is a morphologically rich language with relatively few resources and a less explored syntax compared to English. Given these limitations, Arabic Natural Language Processing (NLP) tasks like Sentiment Analysis (SA), Named Entity Recognition (NER), and Question Answering (QA), have proven to be very challenging to tackle. Recently, with the surge of transformers based models, language-specific BERT based models have proven to be very efficient at language understanding, provided they are pre-trained on a very large corpus. Such models were able to set new standards and achieve state-of-the-art results for most NLP tasks. In this paper, we pre-trained BERT specifically for the Arabic language in the pursuit of achieving the same success that BERT did for the English language. The performance of AraBERT is compared to multilingual BERT from Google and other state-of-the-art approaches. The results showed that the newly developed AraBERT achieved state-of-the-art performance on most tested Arabic NLP tasks. The pretrained araBERT models are publicly available on https://github.com/aub-mind/arabert hoping to encourage research and applications for Arabic NLP.