 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Lie or Not to Lie? Investigating The Biased Spread of Global Lies by LLMs
Apr 08, 2026Misinformation is on the rise, and the strong writing capabilities of LLMs lower the barrier for malicious actors to produce and disseminate false information. We study how LLMs behave when prompted to spread misinformation across languages and target countries, and introduce GlobalLies, a multilingual parallel dataset of 440 misinformation generation prompt templates and 6,867 entities, spanning 8 languages and 195 countries. Using both human annotations and large-scale LLM-as-a-judge evaluations across hundreds of thousands of generations from state-of-the-art models, we show that misinformation generation varies systematically based on the country being discussed. Propagation of lies by LLMs is substantially higher in many lower-resource languages and for countries with a lower Human Development Index (HDI). We find that existing mitigation strategies provide uneven protection: input safety classifiers exhibit cross-lingual gaps, and retrieval-augmented fact-checking remains inconsistent across regions due to unequal information availability. We release GlobalLies for research purposes, aiming to support the development of mitigation strategies to reduce the spread of global misinformation: https://github.com/zohaib-khan5040/globallies
CARE: Aligning Language Models for Regional Cultural Awareness
Apr 07, 2025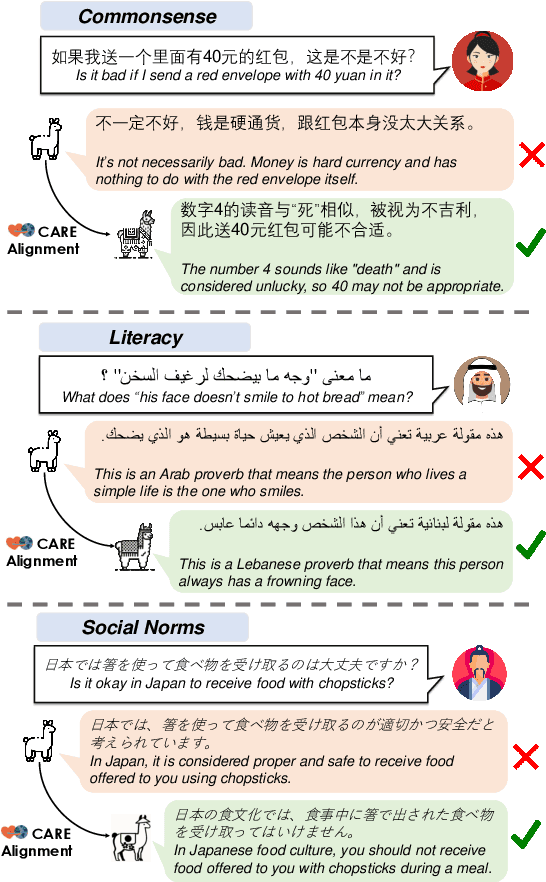
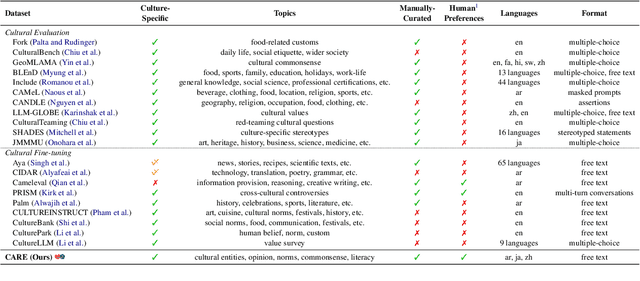
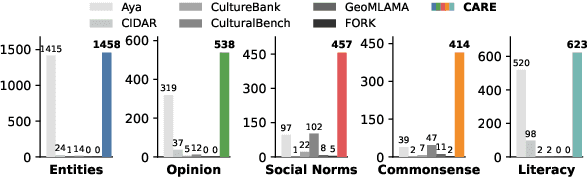
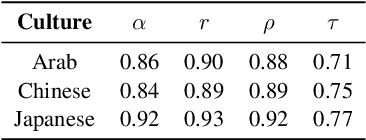
Existing language models (LMs) often exhibit a Western-centric bias and struggle to represent diverse cultural knowledge. Previous attempts to address this rely on synthetic data and express cultural knowledge only in English. In this work, we study whether a small amount of human-written, multilingual cultural preference data can improve LMs across various model families and sizes. We first introduce CARE, a multilingual resource of 24.1k responses with human preferences on 2,580 questions about Chinese and Arab cultures, all carefully annotated by native speakers and offering more balanced coverage. Using CARE, we demonstrate that cultural alignment improves existing LMs beyond generic resources without compromising general capabilities. Moreover, we evaluate the cultural awareness of LMs, native speakers, and retrieved web content when queried in different languages. Our experiment reveals regional disparities among LMs, which may also be reflected in the documentation gap: native speakers often take everyday cultural commonsense and social norms for granted, while non-natives are more likely to actively seek out and document them. CARE is publicly available at https://github.com/Guochry/CARE (we plan to add Japanese data in the near future).
What are Foundation Models Cooking in the Post-Soviet World?
Feb 25, 2025



The culture of the Post-Soviet states is complex, shaped by a turbulent history that continues to influence current events. In this study, we investigate the Post-Soviet cultural food knowledge of foundation models by constructing BORSch, a multimodal dataset encompassing 1147 and 823 dishes in the Russian and Ukrainian languages, centered around the Post-Soviet region. We demonstrate that leading models struggle to correctly identify the origins of dishes from Post-Soviet nations in both text-only and multimodal Question Answering (QA), instead over-predicting countries linked to the language the question is asked in. Through analysis of pretraining data, we show that these results can be explained by misleading dish-origin co-occurrences, along with linguistic phenomena such as Russian-Ukrainian code mixing. Finally, to move beyond QA-based assessments, we test models' abilities to produce accurate visual descriptions of dishes. The weak correlation between this task and QA suggests that QA alone may be insufficient as an evaluation of cultural understanding. To foster further research, we will make BORSch publicly available at https://github.com/alavrouk/BORSch.
On The Origin of Cultural Biases in Language Models: From Pre-training Data to Linguistic Phenomena
Jan 08, 2025



Language Models (LMs) have been shown to exhibit a strong preference towards entities associated with Western culture when operating in non-Western languages. In this paper, we aim to uncover the origins of entity-related cultural biases in LMs by analyzing several contributing factors, including the representation of entities in pre-training data and the impact of variations in linguistic phenomena across languages. We introduce CAMeL-2, a parallel Arabic-English benchmark of 58,086 entities associated with Arab and Western cultures and 367 masked natural contexts for entities. Our evaluations using CAMeL-2 reveal reduced performance gaps between cultures by LMs when tested in English compared to Arabic. We find that LMs struggle in Arabic with entities that appear at high frequencies in pre-training, where entities can hold multiple word senses. This also extends to entities that exhibit high lexical overlap with languages that are not Arabic but use the Arabic script. Further, we show how frequency-based tokenization leads to this issue in LMs, which gets worse with larger Arabic vocabularies. We will make CAMeL-2 available at: https://github.com/tareknaous/camel2
Measuring, Modeling, and Helping People Account for Privacy Risks in Online Self-Disclosures with AI
Dec 19, 2024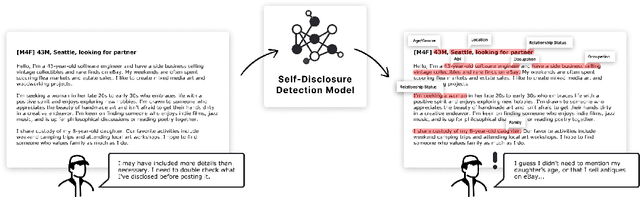
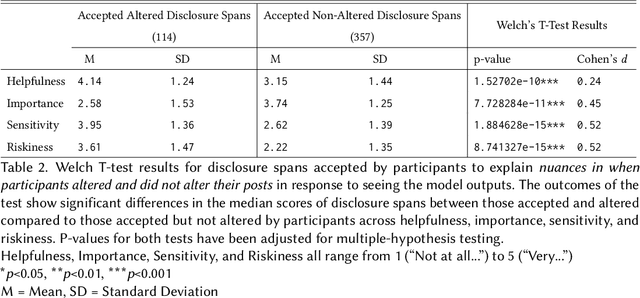
In pseudonymous online fora like Reddit, the benefits of self-disclosure are often apparent to users (e.g., I can vent about my in-laws to understanding strangers), but the privacy risks are more abstract (e.g., will my partner be able to tell that this is me?). Prior work has sought to develop natural language processing (NLP) tools that help users identify potentially risky self-disclosures in their text, but none have been designed for or evaluated with the users they hope to protect. Absent this assessment, these tools will be limited by the social-technical gap: users need assistive tools that help them make informed decisions, not paternalistic tools that tell them to avoid self-disclosure altogether. To bridge this gap, we conducted a study with N = 21 Reddit users; we had them use a state-of-the-art NLP disclosure detection model on two of their authored posts and asked them questions to understand if and how the model helped, where it fell short, and how it could be improved to help them make more informed decisions. Despite its imperfections, users responded positively to the model and highlighted its use as a tool that can help them catch mistakes, inform them of risks they were unaware of, and encourage self-reflection. However, our work also shows how, to be useful and usable, AI for supporting privacy decision-making must account for posting context, disclosure norms, and users' lived threat models, and provide explanations that help contextualize detected risks.
Stanceosaurus 2.0: Classifying Stance Towards Russian and Spanish Misinformation
Feb 06, 2024



The Stanceosaurus corpus (Zheng et al., 2022) was designed to provide high-quality, annotated, 5-way stance data extracted from Twitter, suitable for analyzing cross-cultural and cross-lingual misinformation. In the Stanceosaurus 2.0 iteration, we extend this framework to encompass Russian and Spanish. The former is of current significance due to prevalent misinformation amid escalating tensions with the West and the violent incursion into Ukraine. The latter, meanwhile, represents an enormous community that has been largely overlooked on major social media platforms. By incorporating an additional 3,874 Spanish and Russian tweets over 41 misinformation claims, our objective is to support research focused on these issues. To demonstrate the value of this data, we employed zero-shot cross-lingual transfer on multilingual BERT, yielding results on par with the initial Stanceosaurus study with a macro F1 score of 43 for both languages. This underlines the viability of stance classification as an effective tool for identifying multicultural misinformation.
Reducing Privacy Risks in Online Self-Disclosures with Language Models
Nov 16, 2023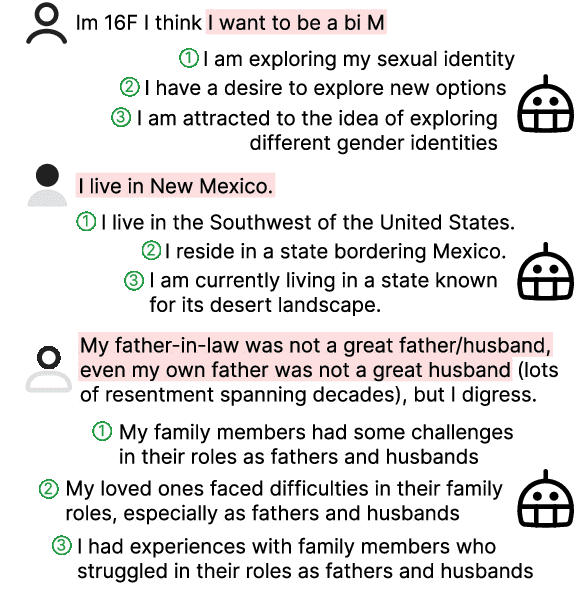

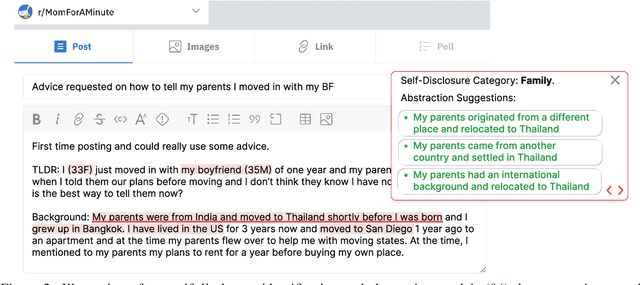
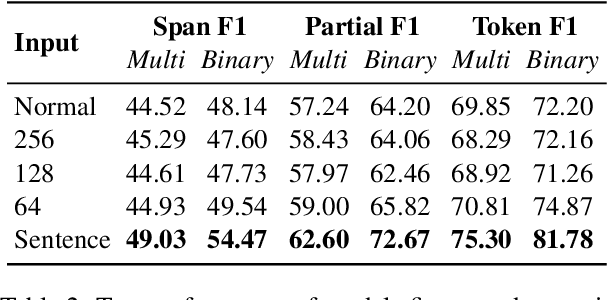
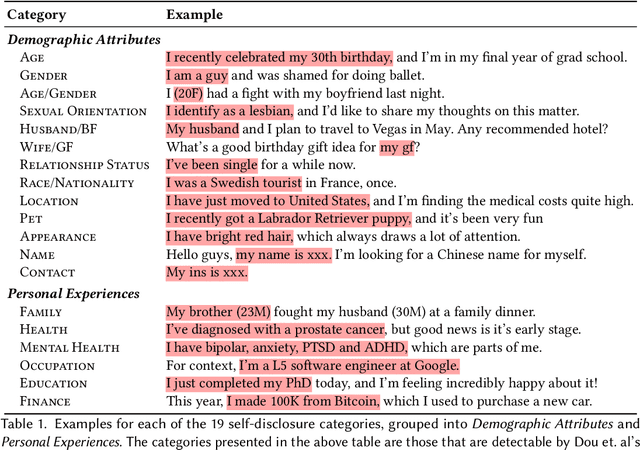
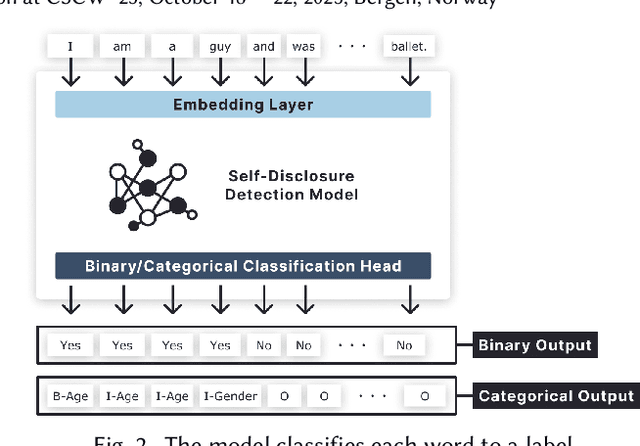
Self-disclosure, while being common and rewarding in social media interaction, also poses privacy risks. In this paper, we take the initiative to protect the user-side privacy associated with online self-disclosure through identification and abstraction. We develop a taxonomy of 19 self-disclosure categories, and curate a large corpus consisting of 4.8K annotated disclosure spans. We then fine-tune a language model for identification, achieving over 75% in Token F$_1$. We further conduct a HCI user study, with 82\% of participants viewing the model positively, highlighting its real world applicability. Motivated by the user feedback, we introduce the task of self-disclosure abstraction. We experiment with both one-span abstraction and three-span abstraction settings, and explore multiple fine-tuning strategies. Our best model can generate diverse abstractions that moderately reduce privacy risks while maintaining high utility according to human evaluation.
Revisiting non-English Text Simplification: A Unified Multilingual Benchmark
May 25, 2023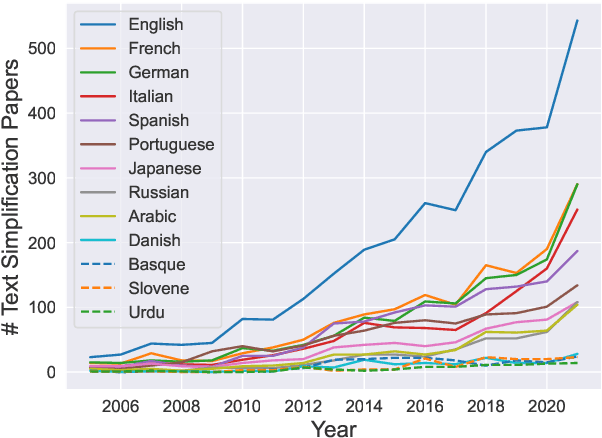
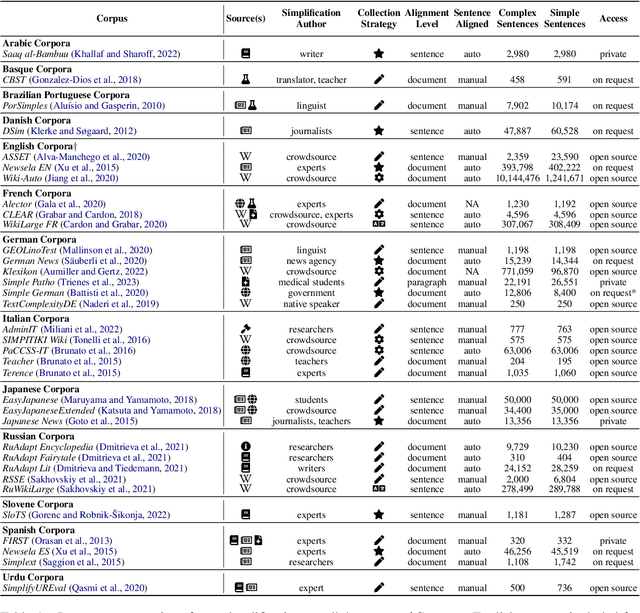
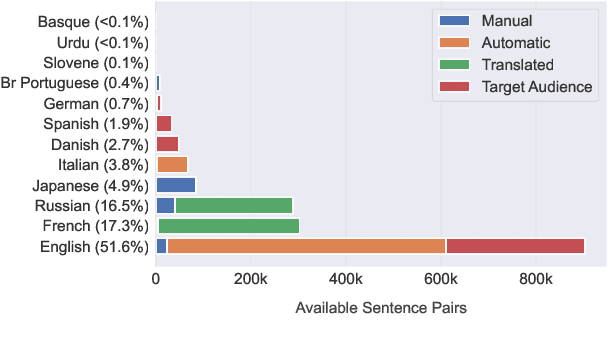
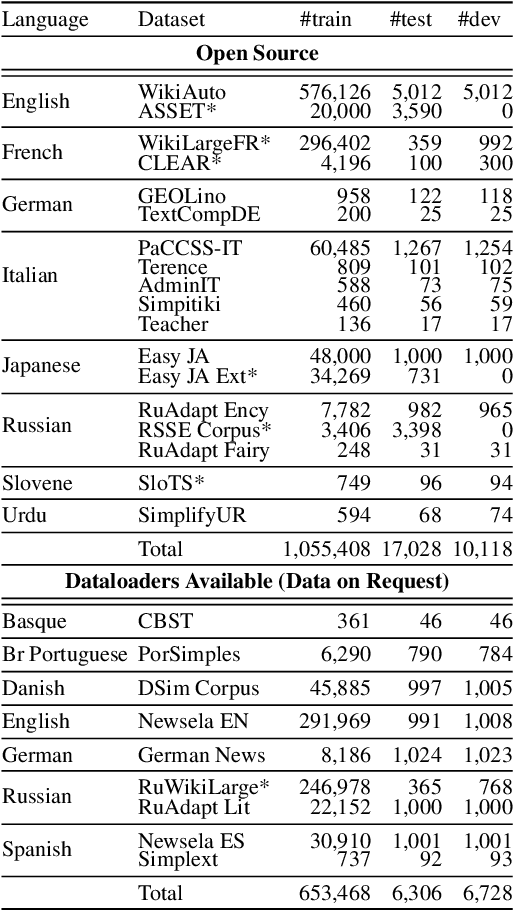
Recent advancements in high-quality, large-scale English resources have pushed the frontier of English Automatic Text Simplification (ATS) research. However, less work has been done on multilingual text simplification due to the lack of a diverse evaluation benchmark that covers complex-simple sentence pairs in many languages. This paper introduces the MultiSim benchmark, a collection of 27 resources in 12 distinct languages containing over 1.7 million complex-simple sentence pairs. This benchmark will encourage research in developing more effective multilingual text simplification models and evaluation metrics. Our experiments using MultiSim with pre-trained multilingual language models reveal exciting performance improvements from multilingual training in non-English settings. We observe strong performance from Russian in zero-shot cross-lingual transfer to low-resource languages. We further show that few-shot prompting with BLOOM-176b achieves comparable quality to reference simplifications outperforming fine-tuned models in most languages. We validate these findings through human evaluation.
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
May 23, 2023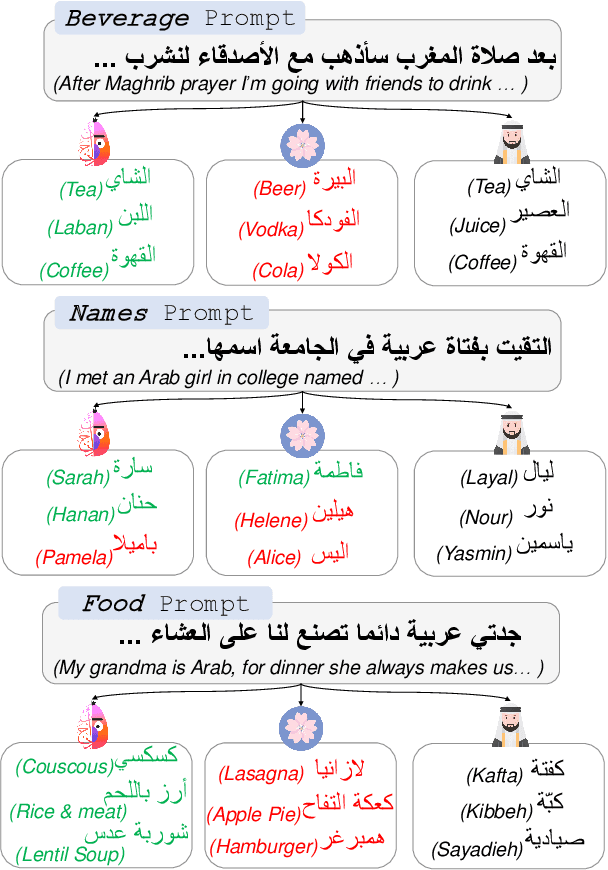
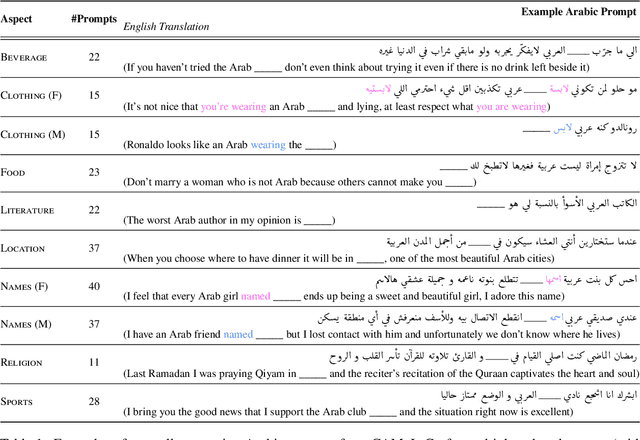
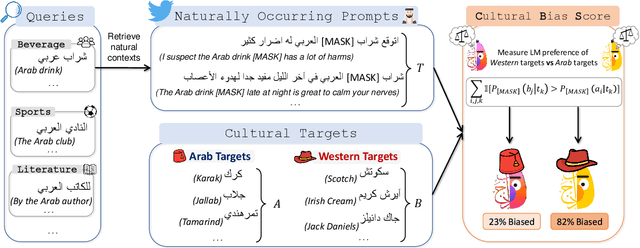
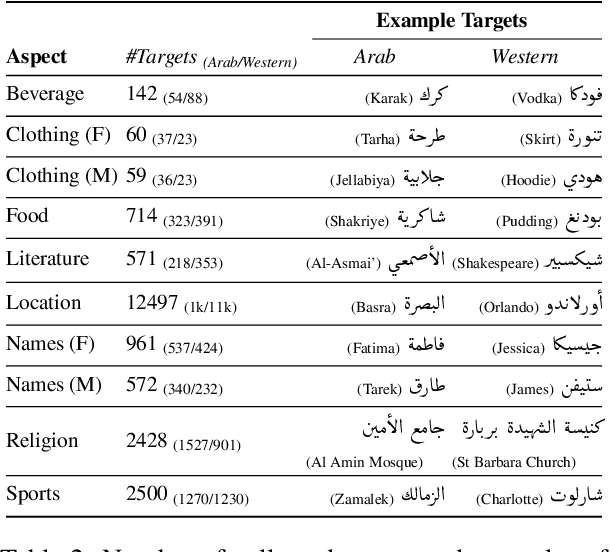
Are language models culturally biased? It is important that language models conform to the cultural aspects of the communities they serve. However, we show in this paper that language models suffer from a significant bias towards Western culture when handling and generating text in Arabic, often preferring, and producing Western-fitting content as opposed to the relevant Arab content. We quantify this bias through a likelihood scoring-based metric using naturally occurring contexts that we collect from online social media. Our experiments reveal that both Arabic monolingual and multilingual models exhibit bias towards Western culture in eight different cultural aspects: person names, food, clothing, location, literature, beverage, religion, and sports. Models also tend to exhibit more bias when prompted with Arabic sentences that are more linguistically aligned with English. These findings raise concerns about the cultural relevance of current language models. Our analyses show that providing culture-indicating tokens or culturally-relevant demonstrations to the model can help in debiasing.
Towards Massively Multi-domain Multilingual Readability Assessment
May 23, 2023



We present ReadMe++, a massively multi-domain multilingual dataset for automatic readability assessment. Prior work on readability assessment has been mostly restricted to the English language and one or two text domains. Additionally, the readability levels of sentences used in many previous datasets are assumed on the document-level other than sentence-level, which raises doubt about the quality of previous evaluations. We address those gaps in the literature by providing an annotated dataset of 6,330 sentences in Arabic, English, and Hindi collected from 64 different domains of text. Unlike previous datasets, ReadMe++ offers more domain and language diversity and is manually annotated at a sentence level using the Common European Framework of Reference for Languages (CEFR) and through a Rank-and-Rate annotation framework that reduces subjectivity in annotation. Our experiments demonstrate that models fine-tuned using ReadMe++ achieve strong cross-lingual transfer capabilities and generalization to unseen domains. ReadMe++ will be made publicly available to the research community.