 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE: Aligning Language Models for Regional Cultural Awareness
Paper and Code
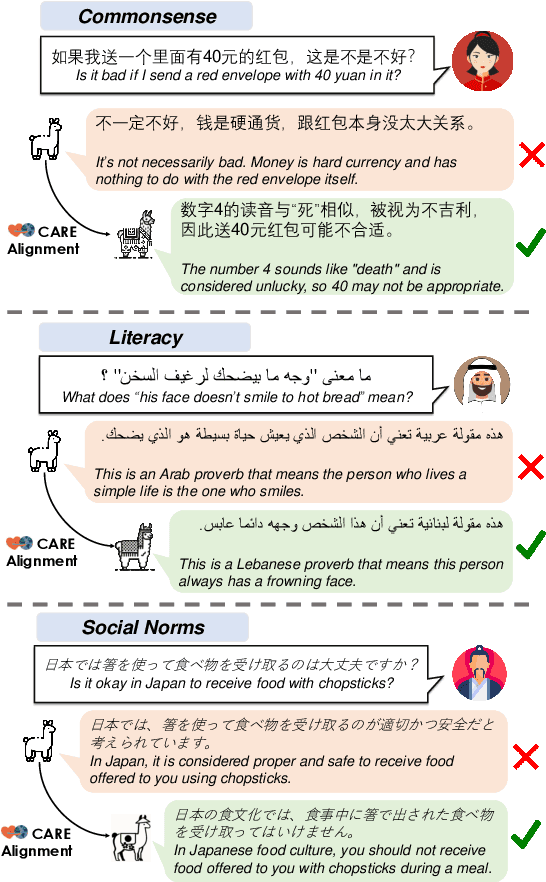
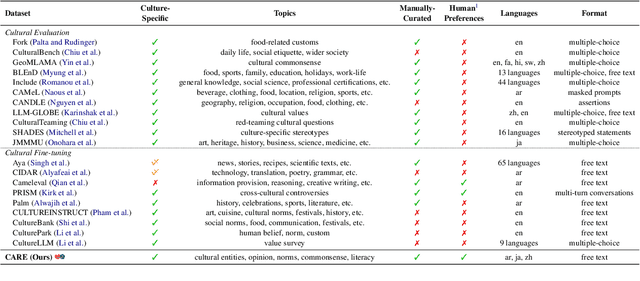
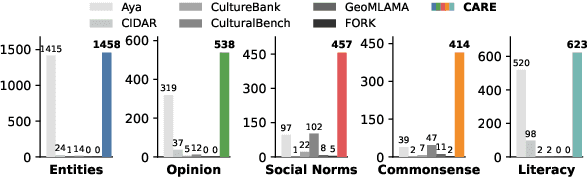
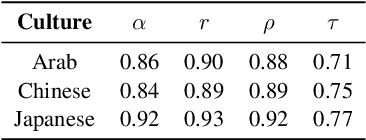
Existing language models (LMs) often exhibit a Western-centric bias and struggle to represent diverse cultural knowledge. Previous attempts to address this rely on synthetic data and express cultural knowledge only in English. In this work, we study whether a small amount of human-written, multilingual cultural preference data can improve LMs across various model families and sizes. We first introduce CARE, a multilingual resource of 24.1k responses with human preferences on 2,580 questions about Chinese and Arab cultures, all carefully annotated by native speakers and offering more balanced coverage. Using CARE, we demonstrate that cultural alignment improves existing LMs beyond generic resources without compromising general capabilities. Moreover, we evaluate the cultural awareness of LMs, native speakers, and retrieved web content when queried in different languages. Our experiment reveals regional disparities among LMs, which may also be reflected in the documentation gap: native speakers often take everyday cultural commonsense and social norms for granted, while non-natives are more likely to actively seek out and document them. CARE is publicly available at https://github.com/Guochry/CARE (we plan to add Japanese data in the near future).