 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Lie or Not to Lie? Investigating The Biased Spread of Global Lies by LLMs
Apr 08, 2026Misinformation is on the rise, and the strong writing capabilities of LLMs lower the barrier for malicious actors to produce and disseminate false information. We study how LLMs behave when prompted to spread misinformation across languages and target countries, and introduce GlobalLies, a multilingual parallel dataset of 440 misinformation generation prompt templates and 6,867 entities, spanning 8 languages and 195 countries. Using both human annotations and large-scale LLM-as-a-judge evaluations across hundreds of thousands of generations from state-of-the-art models, we show that misinformation generation varies systematically based on the country being discussed. Propagation of lies by LLMs is substantially higher in many lower-resource languages and for countries with a lower Human Development Index (HDI). We find that existing mitigation strategies provide uneven protection: input safety classifiers exhibit cross-lingual gaps, and retrieval-augmented fact-checking remains inconsistent across regions due to unequal information availability. We release GlobalLies for research purposes, aiming to support the development of mitigation strategies to reduce the spread of global misinformation: https://github.com/zohaib-khan5040/globallies
CooperBench: Why Coding Agents Cannot be Your Teammates Yet
Jan 19, 2026Resolving team conflicts requires not only task-specific competence, but also social intelligence to find common ground and build consensus. As AI agents increasingly collaborate on complex work, they must develop coordination capabilities to function as effective teammates. Yet we hypothesize that current agents lack these capabilities. To test this, we introduce CooperBench, a benchmark of over 600 collaborative coding tasks across 12 libraries in 4 programming languages. Each task assigns two agents different features that can be implemented independently but may conflict without proper coordination. Tasks are grounded in real open-source repositories with expert-written tests. Evaluating state-of-the-art coding agents, we observe the curse of coordination: agents achieve on average 30% lower success rates when working together compared to performing both tasks individually. This contrasts sharply with human teams, where adding teammates typically improves productivity. Our analysis reveals three key issues: (1) communication channels become jammed with vague, ill-timed, and inaccurate messages; (2) even with effective communication, agents deviate from their commitments; and (3) agents often hold incorrect expectations about others' plans and communication. Through large-scale simulation, we also observe rare but interesting emergent coordination behavior including role division, resource division, and negotiation. Our research presents a novel benchmark for collaborative coding and calls for a shift from pursuing individual agent capability to developing social intelligence.
AutoMetrics: Approximate Human Judgements with Automatically Generated Evaluators
Dec 19, 2025Evaluating user-facing AI applications remains a central challenge, especially in open-ended domains such as travel planning, clinical note generation, or dialogue. The gold standard is user feedback (e.g., thumbs up/down) or behavioral signals (e.g., retention), but these are often scarce in prototypes and research projects, or too-slow to use for system optimization. We present AutoMetrics, a framework for synthesizing evaluation metrics under low-data constraints. AutoMetrics combines retrieval from MetricBank, a collection of 48 metrics we curate, with automatically generated LLM-as-a-Judge criteria informed by lightweight human feedback. These metrics are composed via regression to maximize correlation with human signal. AutoMetrics takes you from expensive measures to interpretable automatic metrics. Across 5 diverse tasks, AutoMetrics improves Kendall correlation with human ratings by up to 33.4% over LLM-as-a-Judge while requiring fewer than 100 feedback points. We show that AutoMetrics can be used as a proxy reward to equal effect as a verifiable reward. We release the full AutoMetrics toolkit and MetricBank to accelerate adaptive evaluation of LLM applications.
EnronQA: Towards Personalized RAG over Private Documents
May 01, 2025Retrieval Augmented Generation (RAG) has become one of the most popular methods for bringing knowledge-intensive context to large language models (LLM) because of its ability to bring local context at inference time without the cost or data leakage risks associated with fine-tuning. A clear separation of private information from the LLM training has made RAG the basis for many enterprise LLM workloads as it allows the company to augment LLM's understanding using customers' private documents. Despite its popularity for private documents in enterprise deployments, current RAG benchmarks for validating and optimizing RAG pipelines draw their corpora from public data such as Wikipedia or generic web pages and offer little to no personal context. Seeking to empower more personal and private RAG we release the EnronQA benchmark, a dataset of 103,638 emails with 528,304 question-answer pairs across 150 different user inboxes. EnronQA enables better benchmarking of RAG pipelines over private data and allows for experimentation on the introduction of personalized retrieval settings over realistic data. Finally, we use EnronQA to explore the tradeoff in memorization and retrieval when reasoning over private documents.
Unintended Impacts of LLM Alignment on Global Representation
Feb 22, 2024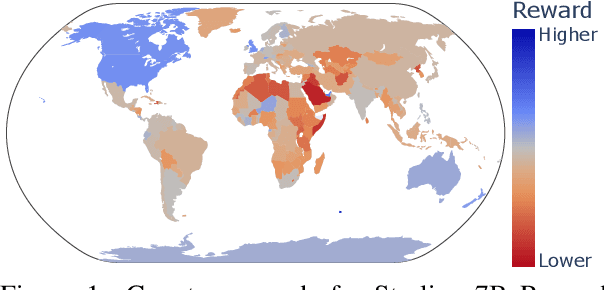

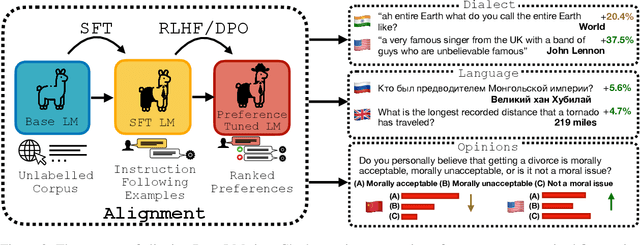
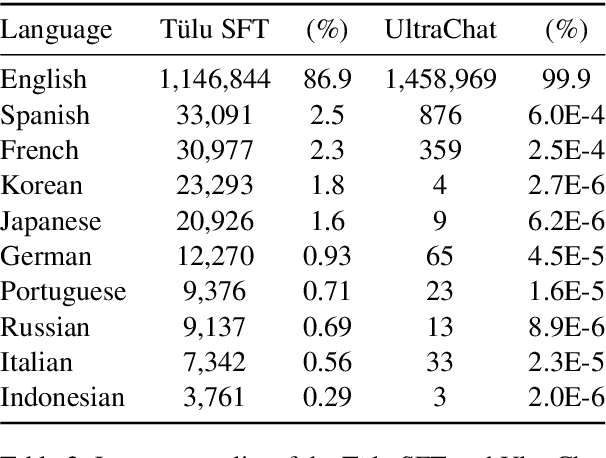
Before being deployed for user-facing applications, developers align Large Language Models (LLMs) to user preferences through a variety of procedures, such as Reinforcement Learning From Human Feedback (RLHF) and Direct Preference Optimization (DPO). Current evaluations of these procedures focus on benchmarks of instruction following, reasoning, and truthfulness. However, human preferences are not universal, and aligning to specific preference sets may have unintended effects. We explore how alignment impacts performance along three axes of global representation: English dialects, multilingualism, and opinions from and about countries worldwide. Our results show that current alignment procedures create disparities between English dialects and global opinions. We find alignment improves capabilities in several languages. We conclude by discussing design decisions that led to these unintended impacts and recommendations for more equitable preference tuning.
Revisiting non-English Text Simplification: A Unified Multilingual Benchmark
May 25, 2023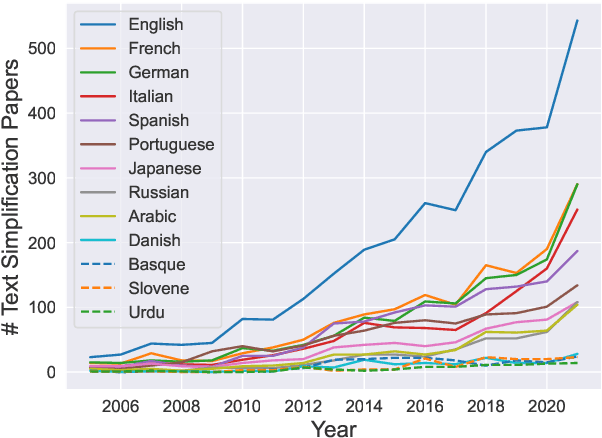
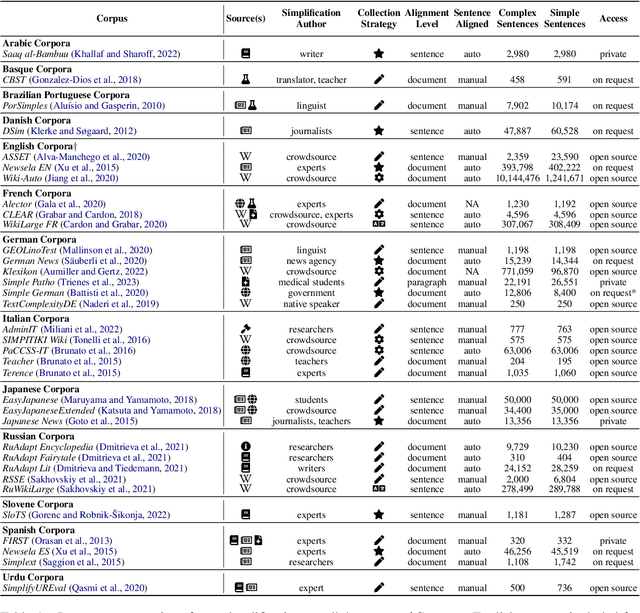
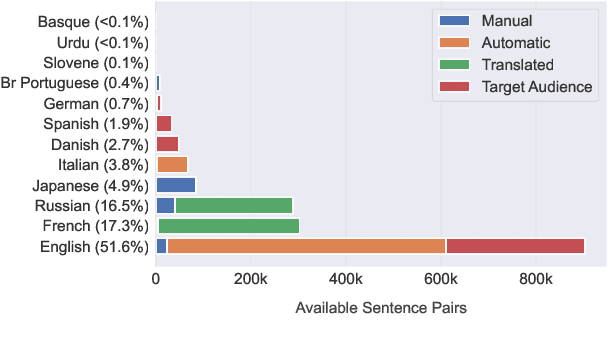
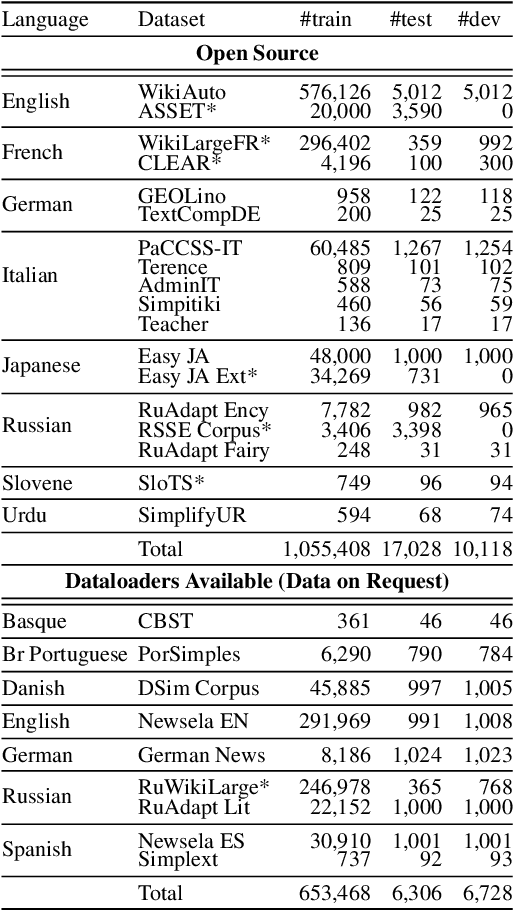
Recent advancements in high-quality, large-scale English resources have pushed the frontier of English Automatic Text Simplification (ATS) research. However, less work has been done on multilingual text simplification due to the lack of a diverse evaluation benchmark that covers complex-simple sentence pairs in many languages. This paper introduces the MultiSim benchmark, a collection of 27 resources in 12 distinct languages containing over 1.7 million complex-simple sentence pairs. This benchmark will encourage research in developing more effective multilingual text simplification models and evaluation metrics. Our experiments using MultiSim with pre-trained multilingual language models reveal exciting performance improvements from multilingual training in non-English settings. We observe strong performance from Russian in zero-shot cross-lingual transfer to low-resource languages. We further show that few-shot prompting with BLOOM-176b achieves comparable quality to reference simplifications outperforming fine-tuned models in most languages. We validate these findings through human evaluation.
Towards Massively Multi-domain Multilingual Readability Assessment
May 23, 2023



We present ReadMe++, a massively multi-domain multilingual dataset for automatic readability assessment. Prior work on readability assessment has been mostly restricted to the English language and one or two text domains. Additionally, the readability levels of sentences used in many previous datasets are assumed on the document-level other than sentence-level, which raises doubt about the quality of previous evaluations. We address those gaps in the literature by providing an annotated dataset of 6,330 sentences in Arabic, English, and Hindi collected from 64 different domains of text. Unlike previous datasets, ReadMe++ offers more domain and language diversity and is manually annotated at a sentence level using the Common European Framework of Reference for Languages (CEFR) and through a Rank-and-Rate annotation framework that reduces subjectivity in annotation. Our experiments demonstrate that models fine-tuned using ReadMe++ achieve strong cross-lingual transfer capabilities and generalization to unseen domains. ReadMe++ will be made publicly available to the research community.
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
May 23, 2023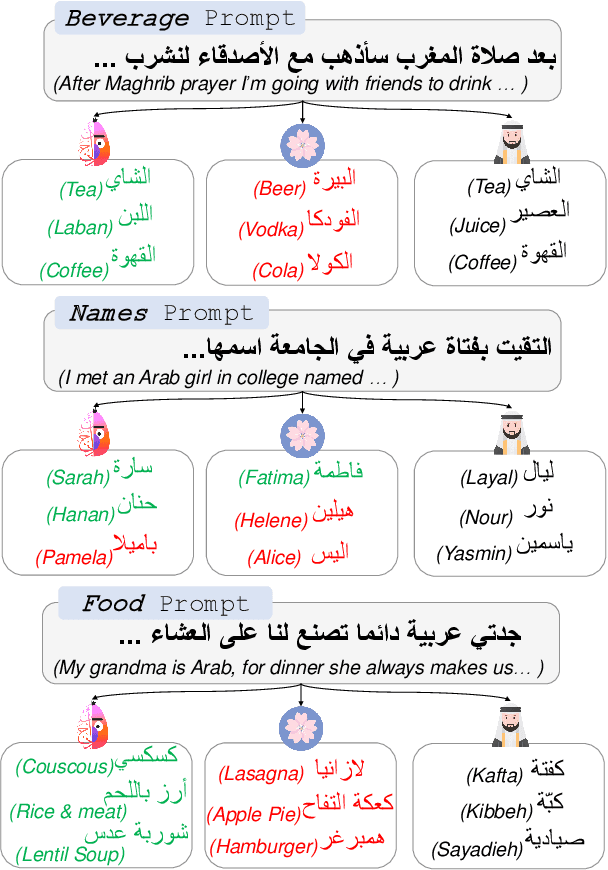
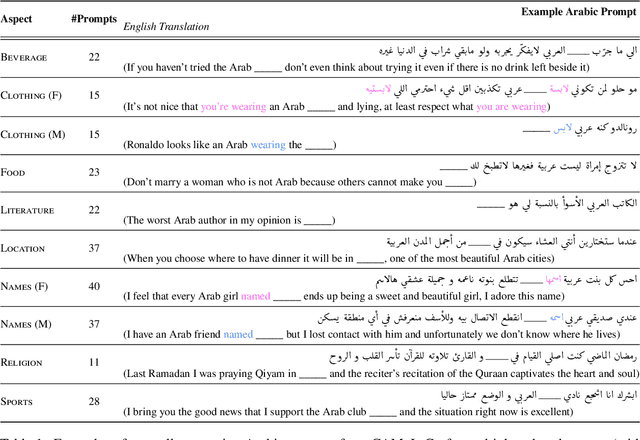
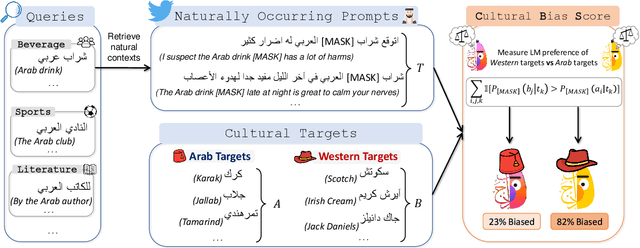
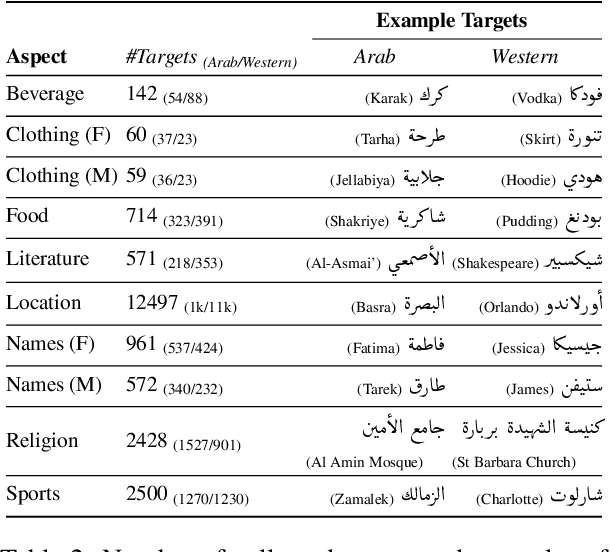
Are language models culturally biased? It is important that language models conform to the cultural aspects of the communities they serve. However, we show in this paper that language models suffer from a significant bias towards Western culture when handling and generating text in Arabic, often preferring, and producing Western-fitting content as opposed to the relevant Arab content. We quantify this bias through a likelihood scoring-based metric using naturally occurring contexts that we collect from online social media. Our experiments reveal that both Arabic monolingual and multilingual models exhibit bias towards Western culture in eight different cultural aspects: person names, food, clothing, location, literature, beverage, religion, and sports. Models also tend to exhibit more bias when prompted with Arabic sentences that are more linguistically aligned with English. These findings raise concerns about the cultural relevance of current language models. Our analyses show that providing culture-indicating tokens or culturally-relevant demonstrations to the model can help in debiasing.
Single Image Internal Distribution Measurement Using Non-Local Variational Autoencoder
Apr 02, 2022
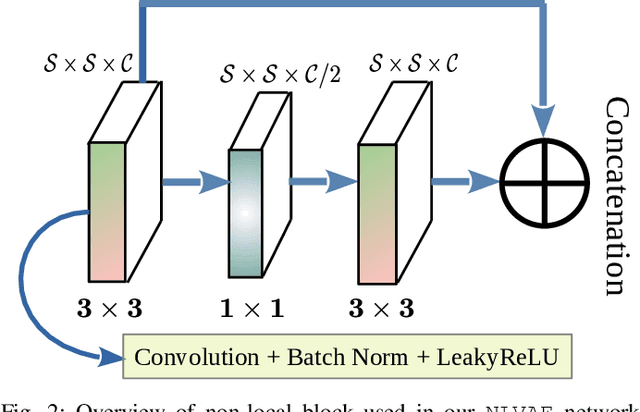
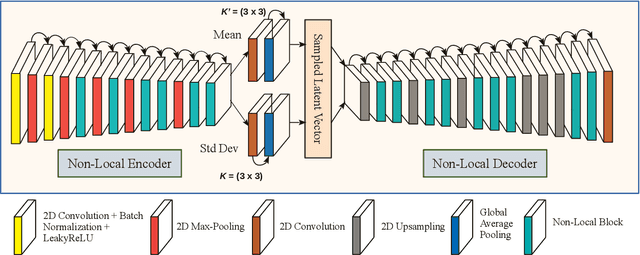

Deep learning-based super-resolution methods have shown great promise, especially for single image super-resolution (SISR) tasks. Despite the performance gain, these methods are limited due to their reliance on copious data for model training. In addition, supervised SISR solutions rely on local neighbourhood information focusing only on the feature learning processes for the reconstruction of low-dimensional images. Moreover, they fail to capitalize on global context due to their constrained receptive field. To combat these challenges, this paper proposes a novel image-specific solution, namely non-local variational autoencoder (\texttt{NLVAE}), to reconstruct a high-resolution (HR) image from a single low-resolution (LR) image without the need for any prior training. To harvest maximum details for various receptive regions and high-quality synthetic images, \texttt{NLVAE} is introduced as a self-supervised strategy that reconstructs high-resolution images using disentangled information from the non-local neighbourhood. Experimental results from seven benchmark datasets demonstrate the effectiveness of the \texttt{NLVAE} model. Moreover, our proposed model outperforms a number of baseline and state-of-the-art methods as confirmed through extensive qualitative and quantitative evaluations.