 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDATAMUt: Deterministic Algorithms for Time-Delay Attack Detection in Multi-Hop UAV Networks
May 12, 2025Unmanned Aerial Vehicles (UAVs), also known as drones, have gained popularity in various fields such as agriculture, emergency response, and search and rescue operations. UAV networks are susceptible to several security threats, such as wormhole, jamming, spoofing, and false data injection. Time Delay Attack (TDA) is a unique attack in which malicious UAVs intentionally delay packet forwarding, posing significant threats, especially in time-sensitive applications. It is challenging to distinguish malicious delay from benign network delay due to the dynamic nature of UAV networks, intermittent wireless connectivity, or the Store-Carry-Forward (SCF) mechanism during multi-hop communication. Some existing works propose machine learning-based centralized approaches to detect TDA, which are computationally intensive and have large message overheads. This paper proposes a novel approach DATAMUt, where the temporal dynamics of the network are represented by a weighted time-window graph (TWiG), and then two deterministic polynomial-time algorithms are presented to detect TDA when UAVs have global and local network knowledge. Simulation studies show that the proposed algorithms have reduced message overhead by a factor of five and twelve in global and local knowledge, respectively, compared to existing approaches. Additionally, our approaches achieve approximately 860 and 1050 times less execution time in global and local knowledge, respectively, outperforming the existing methods.
When Federated Learning Meets Quantum Computing: Survey and Research Opportunities
Apr 09, 2025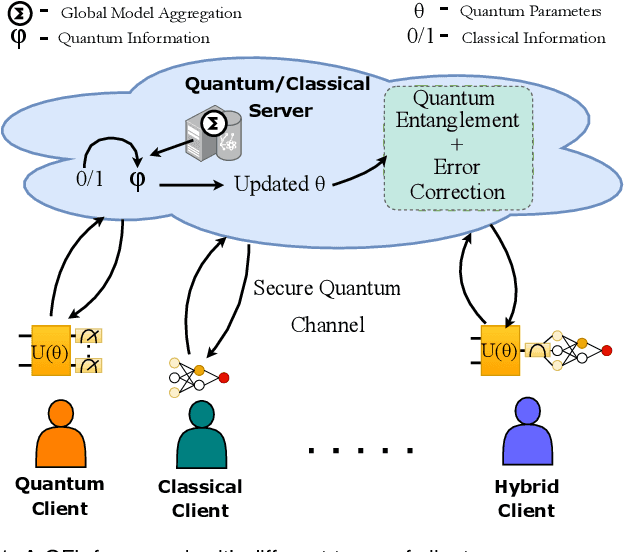
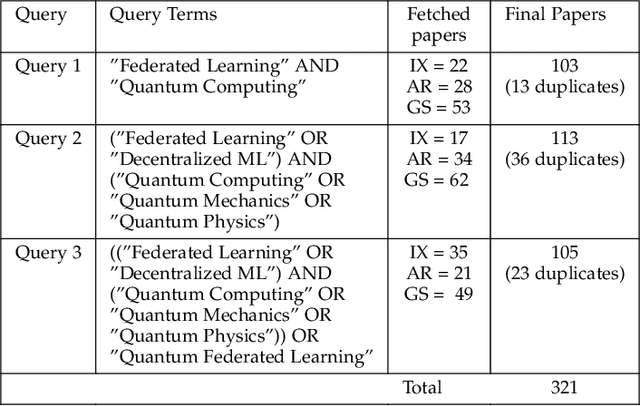
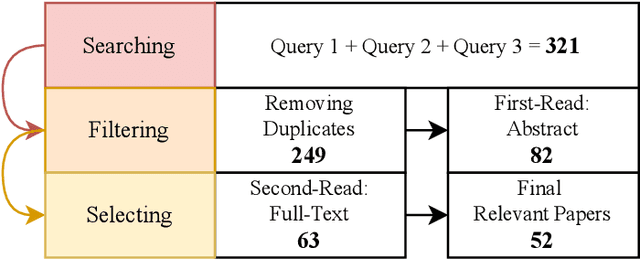
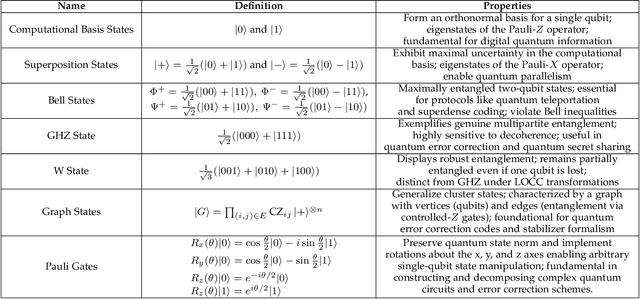
Quantum Federated Learning (QFL) is an emerging field that harnesses advances in Quantum Computing (QC) to improve the scalability and efficiency of decentralized Federated Learning (FL) models. This paper provides a systematic and comprehensive survey of the emerging problems and solutions when FL meets QC, from research protocol to a novel taxonomy, particularly focusing on both quantum and federated limitations, such as their architectures, Noisy Intermediate Scale Quantum (NISQ) devices, and privacy preservation, so on. This work explores key developments and integration strategies, along with the impact of quantum computing on FL, keeping a sharp focus on hybrid quantum-classical approaches. The paper offers an in-depth understanding of how the strengths of QC, such as gradient hiding, state entanglement, quantum key distribution, quantum security, and quantum-enhanced differential privacy, have been integrated into FL to ensure the privacy of participants in an enhanced, fast, and secure framework. Finally, this study proposes potential future directions to address the identified research gaps and challenges, aiming to inspire faster and more secure QFL models for practical use.
Non-Convex Optimization in Federated Learning via Variance Reduction and Adaptive Learning
Dec 16, 2024



This paper proposes a novel federated algorithm that leverages momentum-based variance reduction with adaptive learning to address non-convex settings across heterogeneous data. We intend to minimize communication and computation overhead, thereby fostering a sustainable federated learning system. We aim to overcome challenges related to gradient variance, which hinders the model's efficiency, and the slow convergence resulting from learning rate adjustments with heterogeneous data. The experimental results on the image classification tasks with heterogeneous data reveal the effectiveness of our suggested algorithms in non-convex settings with an improved communication complexity of $\mathcal{O}(\epsilon^{-1})$ to converge to an $\epsilon$-stationary point - compared to the existing communication complexity $\mathcal{O}(\epsilon^{-2})$ of most prior works. The proposed federated version maintains the trade-off between the convergence rate, number of communication rounds, and test accuracy while mitigating the client drift in heterogeneous settings. The experimental results demonstrate the efficiency of our algorithms in image classification tasks (MNIST, CIFAR-10) with heterogeneous data.
CTG-KrEW: Generating Synthetic Structured Contextually Correlated Content by Conditional Tabular GAN with K-Means Clustering and Efficient Word Embedding
Sep 03, 2024Conditional Tabular Generative Adversarial Networks (CTGAN) and their various derivatives are attractive for their ability to efficiently and flexibly create synthetic tabular data, showcasing strong performance and adaptability. However, there are certain critical limitations to such models. The first is their inability to preserve the semantic integrity of contextually correlated words or phrases. For instance, skillset in freelancer profiles is one such attribute where individual skills are semantically interconnected and indicative of specific domain interests or qualifications. The second challenge of traditional approaches is that, when applied to generate contextually correlated tabular content, besides generating semantically shallow content, they consume huge memory resources and CPU time during the training stage. To address these problems, we introduce a novel framework, CTGKrEW (Conditional Tabular GAN with KMeans Clustering and Word Embedding), which is adept at generating realistic synthetic tabular data where attributes are collections of semantically and contextually coherent words. CTGKrEW is trained and evaluated using a dataset from Upwork, a realworld freelancing platform. Comprehensive experiments were conducted to analyze the variability, contextual similarity, frequency distribution, and associativity of the generated data, along with testing the framework's system feasibility. CTGKrEW also takes around 99\% less CPU time and 33\% less memory footprints than the conventional approach. Furthermore, we developed KrEW, a web application to facilitate the generation of realistic data containing skill-related information. This application, available at https://riyasamanta.github.io/krew.html, is freely accessible to both the general public and the research community.
Tackling Selfish Clients in Federated Learning
Jul 22, 2024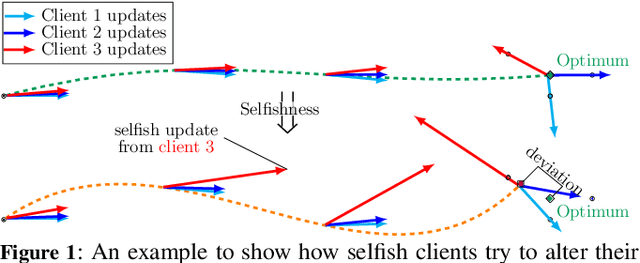
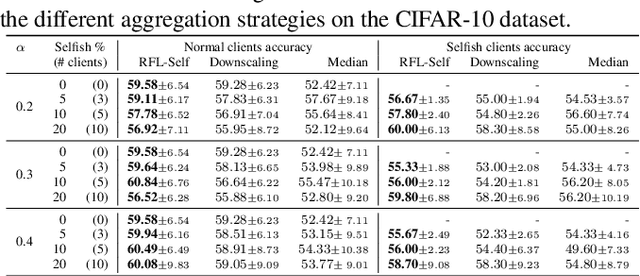
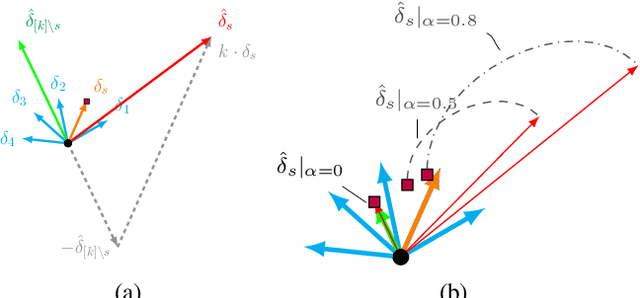
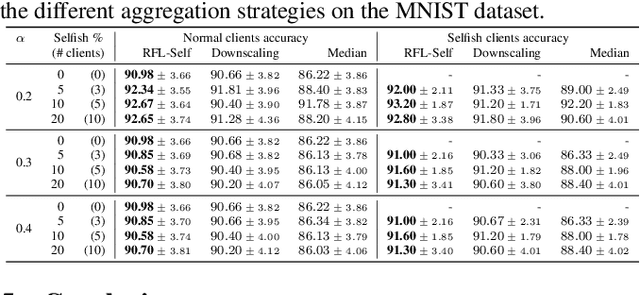
Federated Learning (FL) is a distributed machine learning paradigm facilitating participants to collaboratively train a model without revealing their local data. However, when FL is deployed into the wild, some intelligent clients can deliberately deviate from the standard training process to make the global model inclined toward their local model, thereby prioritizing their local data distribution. We refer to this novel category of misbehaving clients as selfish. In this paper, we propose a Robust aggregation strategy for FL server to mitigate the effect of Selfishness (in short RFL-Self). RFL-Self incorporates an innovative method to recover (or estimate) the true updates of selfish clients from the received ones, leveraging robust statistics (median of norms) of the updates at every round. By including the recovered updates in aggregation, our strategy offers strong robustness against selfishness. Our experimental results, obtained on MNIST and CIFAR-10 datasets, demonstrate that just 2% of clients behaving selfishly can decrease the accuracy by up to 36%, and RFL-Self can mitigate that effect without degrading the global model performance.
Addressing Data Heterogeneity in Federated Learning of Cox Proportional Hazards Models
Jul 20, 2024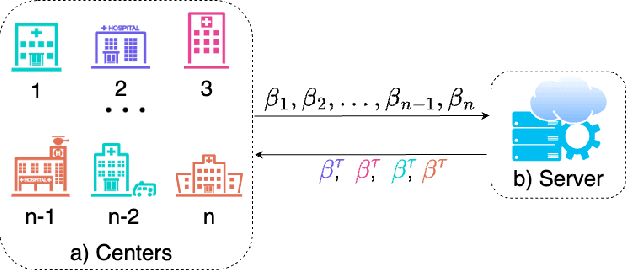
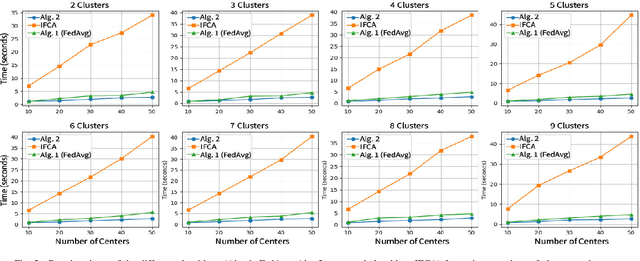
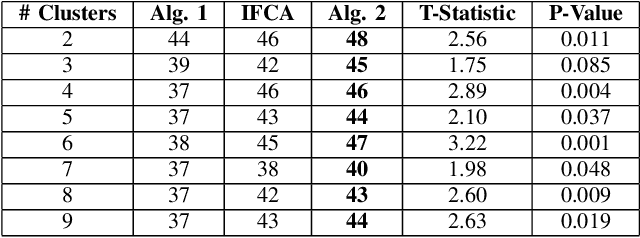
The diversity in disease profiles and therapeutic approaches between hospitals and health professionals underscores the need for patient-centric personalized strategies in healthcare. Alongside this, similarities in disease progression across patients can be utilized to improve prediction models in survival analysis. The need for patient privacy and the utility of prediction models can be simultaneously addressed in the framework of Federated Learning (FL). This paper outlines an approach in the domain of federated survival analysis, specifically the Cox Proportional Hazards (CoxPH) model, with a specific focus on mitigating data heterogeneity and elevating model performance. We present an FL approach that employs feature-based clustering to enhance model accuracy across synthetic datasets and real-world applications, including the Surveillance, Epidemiology, and End Results (SEER) database. Furthermore, we consider an event-based reporting strategy that provides a dynamic approach to model adaptation by responding to local data changes. Our experiments show the efficacy of our approach and discuss future directions for a practical application of FL in healthcare.
Using Geographic Location-based Public Health Features in Survival Analysis
Apr 16, 2023Time elapsed till an event of interest is often modeled using the survival analysis methodology, which estimates a survival score based on the input features. There is a resurgence of interest in developing more accurate prediction models for time-to-event prediction in personalized healthcare using modern tools such as neural networks. Higher quality features and more frequent observations improve the predictions for a patient, however, the impact of including a patient's geographic location-based public health statistics on individual predictions has not been studied. This paper proposes a complementary improvement to survival analysis models by incorporating public health statistics in the input features. We show that including geographic location-based public health information results in a statistically significant improvement in the concordance index evaluated on the Surveillance, Epidemiology, and End Results (SEER) dataset containing nationwide cancer incidence data. The improvement holds for both the standard Cox proportional hazards model and the state-of-the-art Deep Survival Machines model. Our results indicate the utility of geographic location-based public health features in survival analysis.
Securing Federated Learning against Overwhelming Collusive Attackers
Sep 28, 2022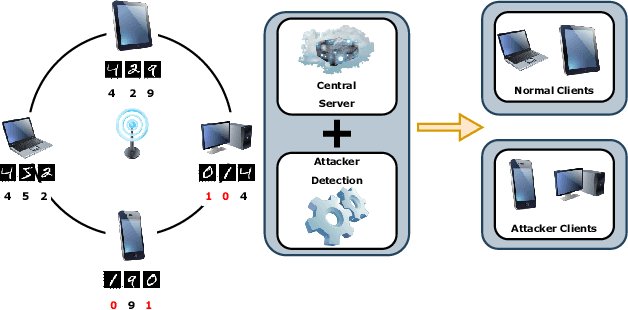
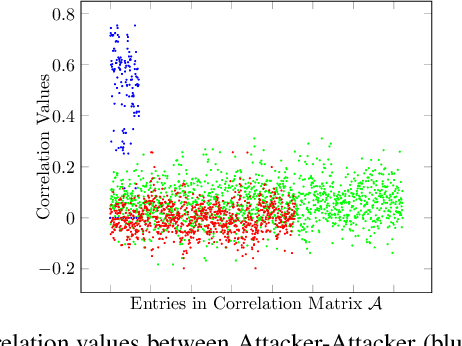
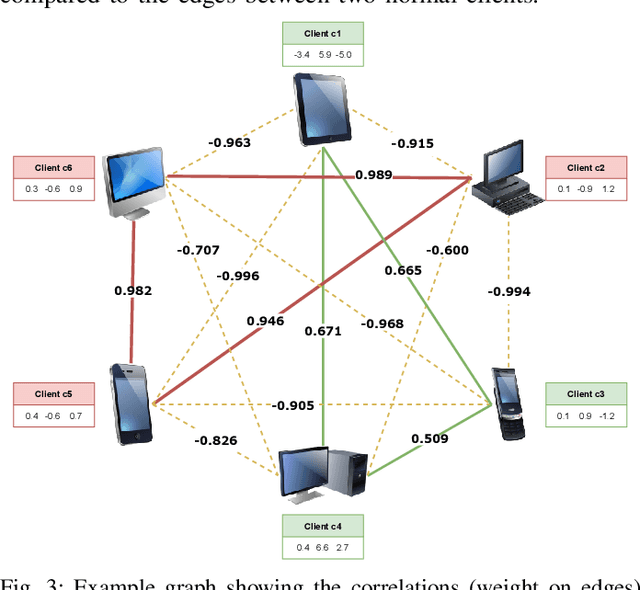
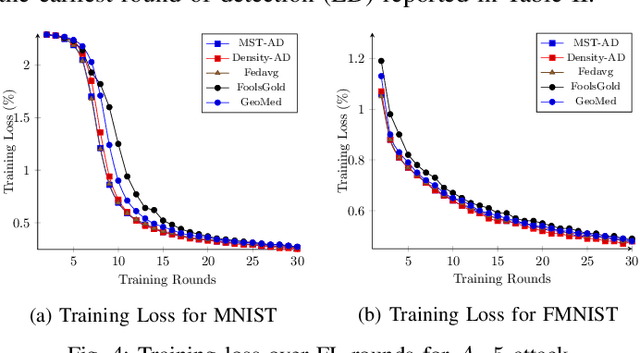
In the era of a data-driven society with the ubiquity of Internet of Things (IoT) devices storing large amounts of data localized at different places, distributed learning has gained a lot of traction, however, assuming independent and identically distributed data (iid) across the devices. While relaxing this assumption that anyway does not hold in reality due to the heterogeneous nature of devices, federated learning (FL) has emerged as a privacy-preserving solution to train a collaborative model over non-iid data distributed across a massive number of devices. However, the appearance of malicious devices (attackers), who intend to corrupt the FL model, is inevitable due to unrestricted participation. In this work, we aim to identify such attackers and mitigate their impact on the model, essentially under a setting of bidirectional label flipping attacks with collusion. We propose two graph theoretic algorithms, based on Minimum Spanning Tree and k-Densest graph, by leveraging correlations between local models. Our FL model can nullify the influence of attackers even when they are up to 70% of all the clients whereas prior works could not afford more than 50% of clients as attackers. The effectiveness of our algorithms is ascertained through experiments on two benchmark datasets, namely MNIST and Fashion-MNIST, with overwhelming attackers. We establish the superiority of our algorithms over the existing ones using accuracy, attack success rate, and early detection round.
Suppressing Noise from Built Environment Datasets to Reduce Communication Rounds for Convergence of Federated Learning
Sep 03, 2022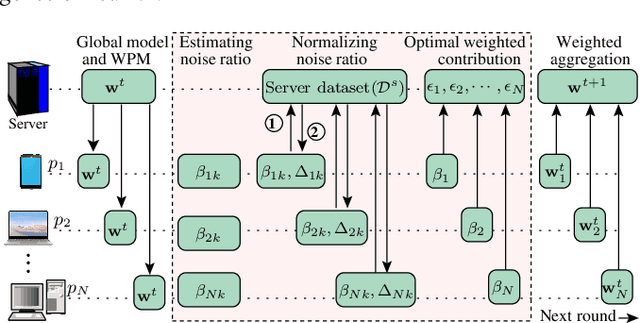
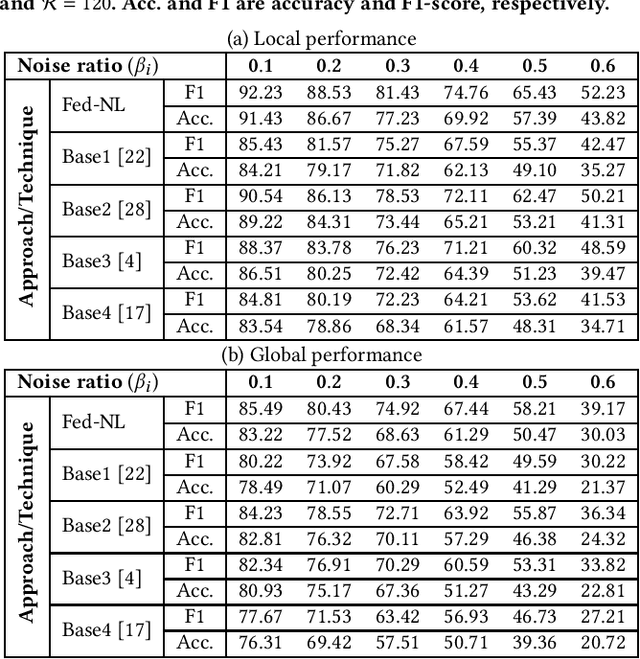
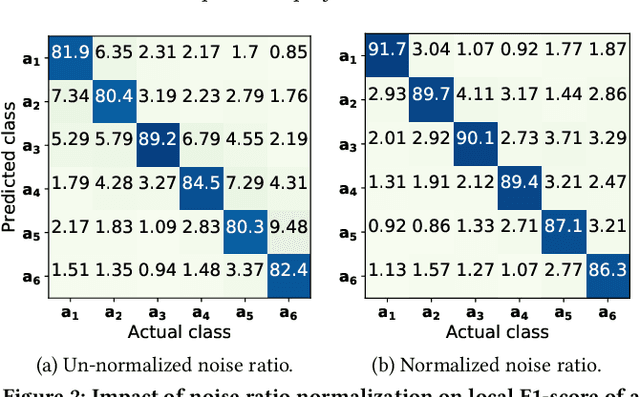
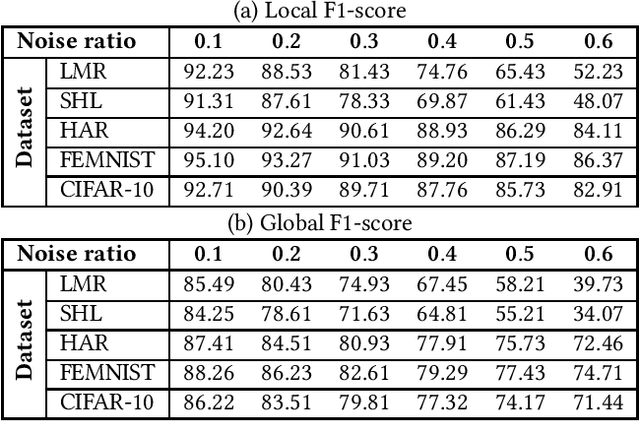
Smart sensing provides an easier and convenient data-driven mechanism for monitoring and control in the built environment. Data generated in the built environment are privacy sensitive and limited. Federated learning is an emerging paradigm that provides privacy-preserving collaboration among multiple participants for model training without sharing private and limited data. The noisy labels in the datasets of the participants degrade the performance and increase the number of communication rounds for convergence of federated learning. Such large communication rounds require more time and energy to train the model. In this paper, we propose a federated learning approach to suppress the unequal distribution of the noisy labels in the dataset of each participant. The approach first estimates the noise ratio of the dataset for each participant and normalizes the noise ratio using the server dataset. The proposed approach can handle bias in the server dataset and minimizes its impact on the participants' dataset. Next, we calculate the optimal weighted contributions of the participants using the normalized noise ratio and influence of each participant. We further derive the expression to estimate the number of communication rounds required for the convergence of the proposed approach. Finally, experimental results demonstrate the effectiveness of the proposed approach over existing techniques in terms of the communication rounds and achieved performance in the built environment.
FedAR+: A Federated Learning Approach to Appliance Recognition with Mislabeled Data in Residential Buildings
Sep 03, 2022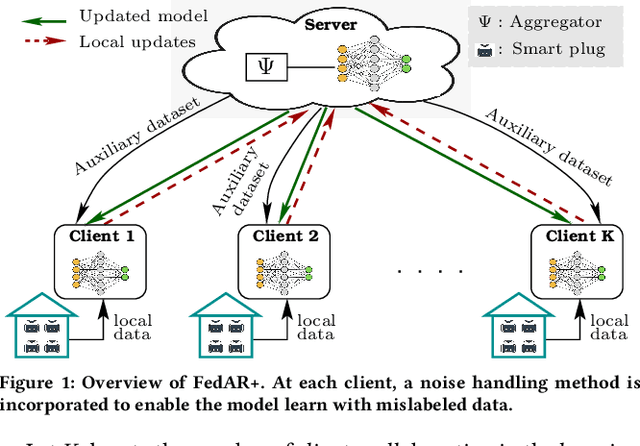
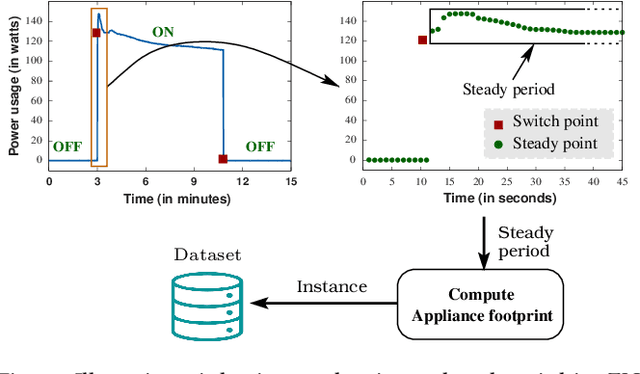
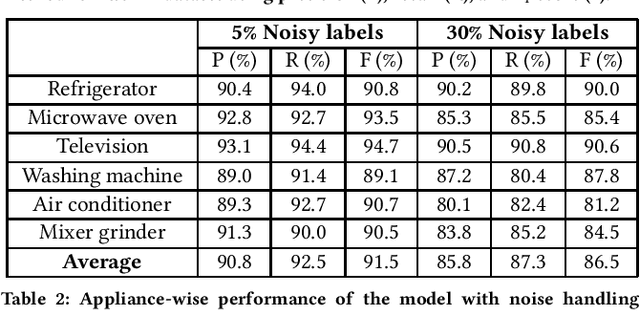
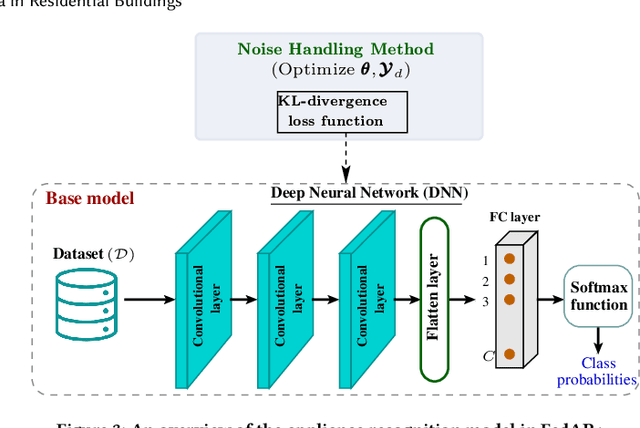
With the enhancement of people's living standards and rapid growth of communication technologies, residential environments are becoming smart and well-connected, increasing overall energy consumption substantially. As household appliances are the primary energy consumers, their recognition becomes crucial to avoid unattended usage, thereby conserving energy and making smart environments more sustainable. An appliance recognition model is traditionally trained at a central server (service provider) by collecting electricity consumption data, recorded via smart plugs, from the clients (consumers), causing a privacy breach. Besides that, the data are susceptible to noisy labels that may appear when an appliance gets connected to a non-designated smart plug. While addressing these issues jointly, we propose a novel federated learning approach to appliance recognition, called FedAR+, enabling decentralized model training across clients in a privacy preserving way even with mislabeled training data. FedAR+ introduces an adaptive noise handling method, essentially a joint loss function incorporating weights and label distribution, to empower the appliance recognition model against noisy labels. By deploying smart plugs in an apartment complex, we collect a labeled dataset that, along with two existing datasets, are utilized to evaluate the performance of FedAR+. Experimental results show that our approach can effectively handle up to $30\%$ concentration of noisy labels while outperforming the prior solutions by a large margin on accuracy.